
JUnit4/JUnit5 注解
| junit4 | junit5 | 特点 |
|---|---|---|
| @BeforeClass | @BeforeAll | 在当前类的所有测试方法之前执行。注解在【静态方法】上。 |
| @AfterClass | @AfterAll | 在当前类中的所有测试方法之后执行。注解在【静态方法】上。 |
| @Before | @BeforeEach | 在每个测试方法之前执行。注解在【非静态方法】上。 |
| @After | @AfterEach | 在每个测试方法之后执行。注解在【非静态方法】上。 |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-07-14
为什么叫"测试夹具":Fixture 的词源与跨领域漫游
测试夹具这个中文词带着工业感,让第一次听到它的开发者往往去搜索"是不是翻译错了"。词源确实如此:fixture 来自机械加工,后来进入电子测试领域,再由 Kent Beck 引入软件测试框架里。这个词在软件工程里覆盖的范围,也远比"单元测试"要宽。 从车间到代码 fixture 这个词在机械加工里有精确含义:在 CNC 车床或焊接台上,fixture 是一种工装,把工件固定在已知位置,让每次加工操作都从相同的起点开始。与 jig(引导刀具路径的夹具)不同,fixture 的职责只有一件事——把工件钳牢,消除定位误差。 词源上,fixture 来自拉丁语 figere(刺入、固定),经 fixura(固定物)演变为英语词汇,约在 16 世纪末进入法律语言,最初指"永久附着于不动产的动产"——嵌入墙体的管道、固定在地板上的书架,那些不能随意拆走的东西。 电子测试领域用法相似:一块 PCB 插入测试夹具后被固定在已知电气状态,探针才能重复施加相同的激励、在相同节点读取信号,排除接触不稳定的干扰。 三种用法的共同语义:将某个对象...

2022-02-11
技术拾遗
Java Java 8 Lambda Java 8 Lambdas - A Peek Under the Hood What does $$ in javac generated name mean? lambda 表达式并不总是持有外部 enclosing object 的引用,如果它不访问任何外部变量,即不持有这样的引用。只要设计一个对比实验,就会发现引用过外部变量的lambda实例才会产生一个 arg 的隐式参数引用。而内部类内部总是含有一个this$0。 lambda表达式是词法作用域的-意思是不产生新的作用域,不产生任何shadowing问题。它可以无缝访问外部作用域的东西,就好像从一个 if block 里访问一个方法里的其他变量一样。但,同样地,不能声明新变量。
2018-10-22
JDWP 与远程调试
JDWP(Java Debug Wire Protocol),它提供了调试器和目标 JVM (target vm)之间的调试协议。 在 target vm 启动时,增加这个 JAVA_OPTS: 1JAVA_OPTS="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=26310" 在服务器端,增加 remote debuging 的时候使用如下配置: 12345678# Java 9 以上-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:8000# Java 5-8-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000# Java 1.4.x -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,addre...

2026-05-21
图灵机:纸带、读写头和最小通用计算
DFA 只有有限状态。NFA 允许同时保留多个状态。PDA 在有限状态之外加了一只栈,可以处理任意深度的嵌套。图灵机再往前走一步:它把栈换成一条可以读、写、左右移动的纸带。 这个变化很小,却足以把机器能力推到通用计算。图灵机仍然只有有限个控制状态,每一步仍然按规则机械执行;不同的是,机器可以在纸带上写下中间结果,之后再移动回来读取。程序状态和可变存储被明确分开。 本文先写一台最小确定性图灵机(Deterministic Turing Machine,DTM)。示例很小:读写头从第一个字符开始,把当前位置的符号改成 1,向右移动一格,然后停机。下一篇再用同一套结构实现一个稍微有算法味的纸带程序。 图灵机比 PDA 多了什么 PDA 的栈只能操作一端。读写都发生在栈顶,历史只能以后进先出的方式取回。图灵机的纸带更自由:读写头可以向左或向右移动,机器可以反复回到某个位置修改内容。 模型 有限控制 可增长存储 读写位置 典型能力 DFA / NFA 有 无 无 正则语言 PDA 有 栈 栈顶 嵌套结构 图灵机 有 纸带 当前格,可左右移动 通用计算 这个表里...
2017-10-23
昂贵的异常
抛出问题 Joshua Bloch 在《Effective Java》的 Item 57 里明确地提到过,不要试图用 Exception 的跳转来代替正常的程序控制流。他列举了很多原因,但特别提到了抛出异常会使得整个程序运行变慢。抛出异常远比普通的 return、break 等操作对控制流、数据流的性能影响要大,它就只适合拿来作异常分支的控制语句,而不能拿来编写正常的逻辑。 Throwing exception is expensive. 这句话在 Java 的程序员世界里面已经成为老生常谈,却很少有人谈及到底抛出异常比正常的程序跳转返回慢在哪里,有多慢。"不要滥用异常"好像一个猴子定律,人们知道不能这么做,却不明白为什么不能这么做。 此前读了一位同事写的好文《Java虚拟机是如何处理异常的》,深入地分析了 JVM 对异常跳转的处理过程:JVM 会通过异常表的机制,优化异常抛出和正常返回之间的性能差异。仅从程序计数器的移动上来讲,抛出一个异常对栈帧的弹栈并不比直接返回更昂贵。写在前头的结论是:"try-catch 语句块几乎不会影响程序运行性能!...
2020-03-11
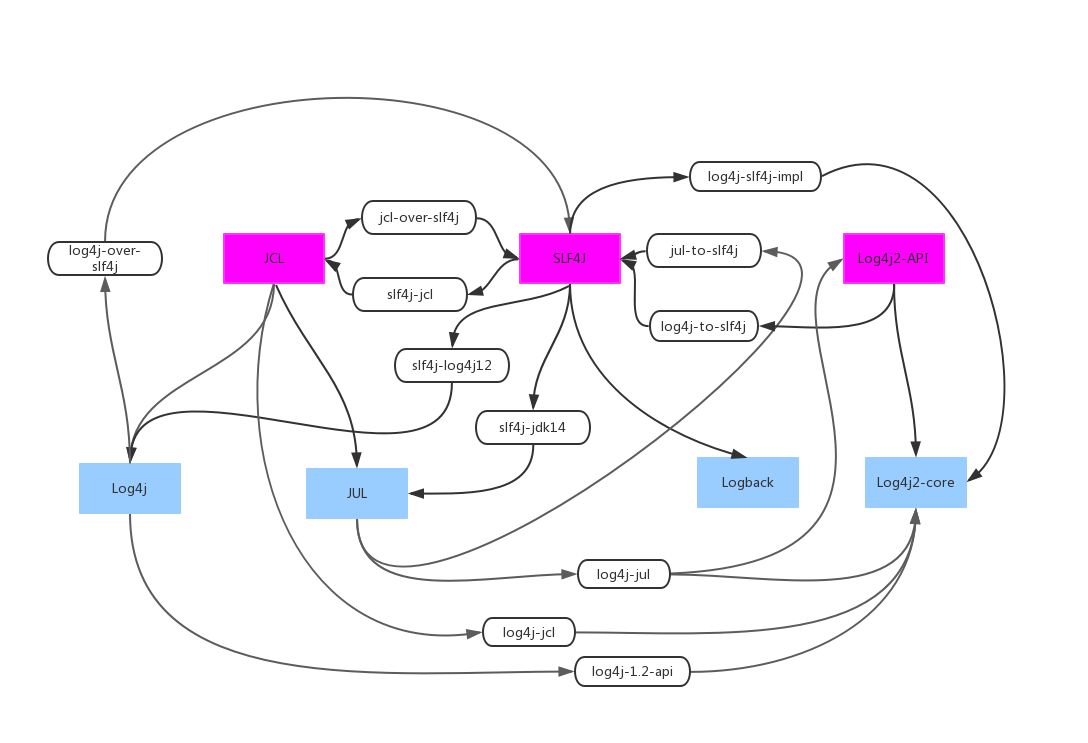
Java Logging
log 历史 阶段 阶段 阶段 阶段 阶段 log4j apache commons logging(JCL) log4j2 JUL simple log logback + slf4j 多个项目使用不同的 logging 库 + 传递依赖等于依赖管理不规范,日志库泛滥以至互斥。 具体框架与门面 所谓的日志框架,指的是日志输出的具体实现,常见的日志框架包括但不仅限于 JUL(Java Util Logging)、Log4j、Log4j2 和 Logback。这些框架的功能不尽相同,比如有些框架支持友好地打印异常,有些不支持,有些框架不支持,不同的框架的日志级别也各有差异。 因此,诞生了日志门面。所谓的门面,就是“使用一个中间层解耦”这一具体思想的应用。使用了门面,可以屏蔽日志使用者对于具体差异的依赖,既让代码变得整洁,而且可以简单地切换实现而不需要修改代码。没有日志门面,不足以统一日志框架的使用。 log facade(定义 interface,早期的 JCL 时代,facade 也被叫做接口)-> log imp...



