Deli AutoResearch:从论文流水线到研究品味
调研截至:2026-06-19。这里追踪的是 Deli Chen 在 2026 年 6 月公开展示的 AutoResearch / paper_writing 项目材料,包括 X 更新、AutoResearch 框架页、V2 博文、paper_writing skill group 页和论文索引页。文中所有页数、引用数、评分和耗时均按项目页面自述记录,不视为独立外部评测。
Deli Chen 这次公开出来的东西,确实可以拆成两个可复用组件,但它们不是两个完全同形的 skill:
| 组件 | 更准确的定位 | 公开状态 | 核心用途 |
|---|---|---|---|
Deli_AutoResearch |
长程自主研究框架协议 | 公开完整 SKILL.md |
约束多天到多周任务里的状态、停滞、看护、方向切换和子 agent 编排 |
paper_writing |
科学论文写作 skill group | 公开方法页 | 把文献召回、结构写作、实验设计、图表、模拟审稿串成论文生产流水线 |
V2 博文写的是“三篇论文、941 条引用、190 页、平均模拟评审 8.5/10、约 38 小时”。论文索引页在 2026-06-17 又更新到“四篇论文、1158 条引用、265 页、8.5+ 平均评分”。这说明它还在高速迭代,博客追踪时不能只摘一个数字当最终状态。
比数字更需要记录的是,Deli 在公开更新里把下一阶段瓶颈归结为 research taste:文章已经能被流水线写顺,难点转向问题选择、角度选择和停止条件。这个判断比页数和引用数更有追踪价值。
为什么单独写一篇
本博客已经有几篇相邻文章:
| 已有文章 | 讨论重点 | 与 Deli AutoResearch 的关系 |
|---|---|---|
| Superpowers 的 skill 体系 | skill 作为 behavior-shaping content,如何约束 agent 行为 | 提供 skill 形态背景 |
| Agentic Flow 不是 Harness | Flow、Policy、Harness、Eval 的分层 | 可以解释 AutoResearch 里的编排层和执行层 |
| Loop Engineering:从 Boris 的 /loops 到持久 Agent 工程 | 持久 Agent 循环、状态、守护、恢复 | 与 AutoResearch 的 heartbeat / stall detection 高度相邻 |
| Ponytail:把 YAGNI 写进 Coding Agent | 把工程纪律写成 agent 可执行约束 | 与 paper_writing 的质量门禁同类 |
这些文章能解释背景,但 Deli AutoResearch 本身已经是一个独立案例:它同时展示了长程运行协议、研究流水线、写作 skill、模拟审稿和引用复核。塞进旧文会变成脚注,反而看不清它作为“研究工厂样本”的价值。
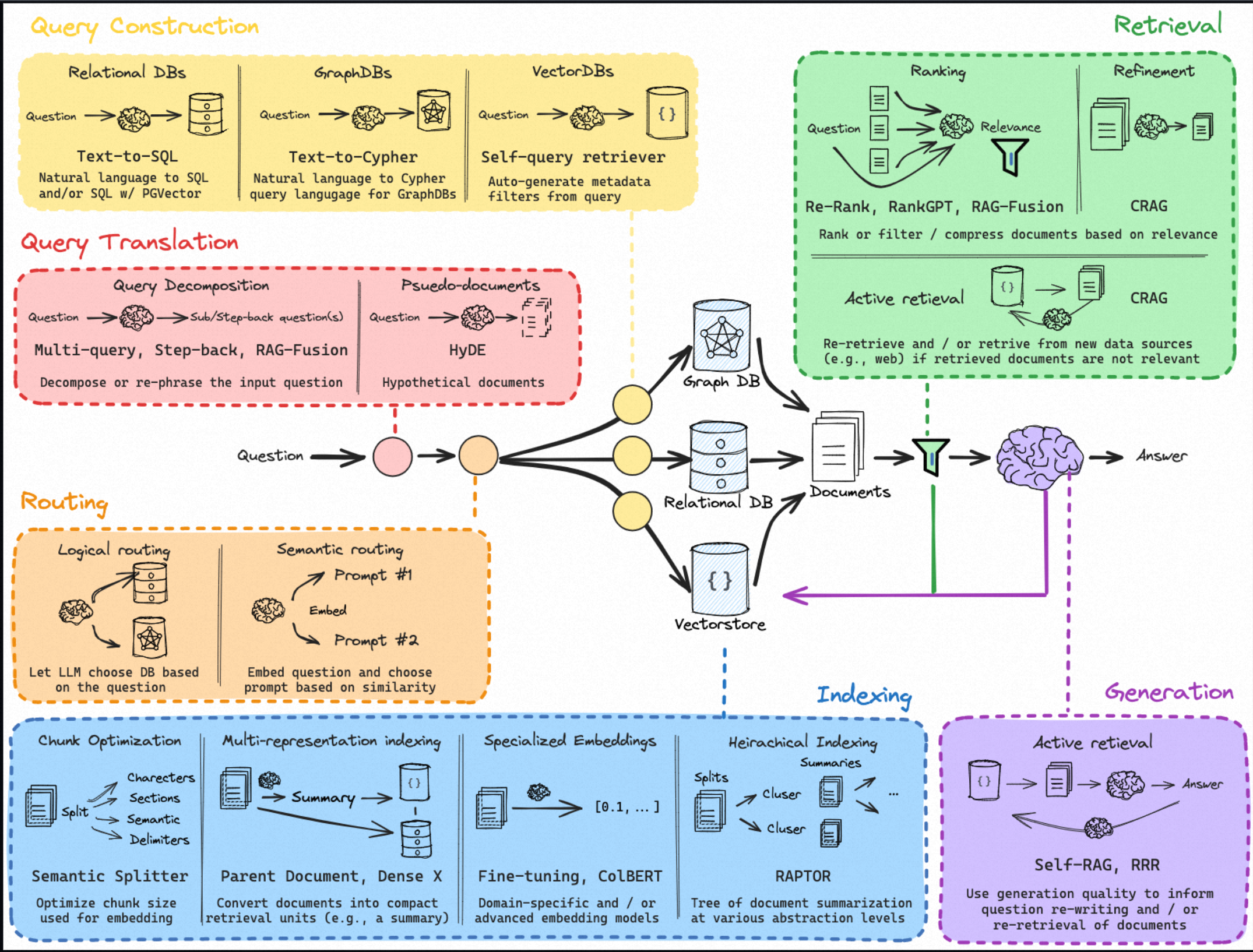
AutoResearch 不是搜索脚本
AutoResearch 框架页说得很直白:它不提供可执行代码,只提供一份自包含的 SKILL.md 协议。它处理的是长程 agent 为什么跑着跑着会坏掉。
框架把失败模式分成三类:
| 失败模式 | 现象 | 对应机制 |
|---|---|---|
| Cognitive Loop | 连续多轮都在相似方向里打转,收益递减 | 方向历史、强制差异、结构性 pivot |
| Stalling | 完成一块工作后总结并等待用户,外观看起来还活着,实际已停工 | zero-interaction 约束、停滞检测、nudge subagent |
| Runtime Fragility | 上下文压缩、会话关闭或定时器依赖导致循环无声死亡 | 文件状态、heartbeat watchdog、分层看护 |
它的工程选择很硬:
- 状态落在文件里,不依赖对话记忆。
- 每轮任务使用 fresh session,而不是 resume。
- 执行者不评价自己的进展,停滞判断交给编排层。
- guardian 只能做 liveness-check、restart、nudge,不能越权读写任务数据。
- 单轮工作有轮数和时间上限,停滞后改结构约束,而不是继续微调战术参数。
这套设计像是把“长程 agent 总会跑偏”当作事实前提,再围绕这个事实设计防线。它不迷信模型自律,而是靠状态、日志、看护和独立评估把自律变成外部约束。
paper_writing 的真正重点
paper_writing 页把论文生产拆成五个子 skill:
| 子 skill | 输入 | 输出 | 关键规则 |
|---|---|---|---|
| Literature Survey | 主题和 taxonomy 关键词 | references.bib、citation_plan.jsonl |
Recall → LQS 评分 → A/B/C/D 引用深度分类 → DBLP/OpenReview venue upgrade |
| Paper Structure & Logic | bib 和实验发现 | sections/*.tex |
章节架构、段落逻辑链、taxonomy、claim strength |
| Experiment Design | conjecture 或 gap | results.json、experiment_summary.md |
先定义假设、变量、统计方案,再执行实验 |
| Academic Figures & Tables | 结果和占位符 | figures/*.pdf、tables/*.tex |
高信息密度表格、向量图、caption 带结论 |
| Peer Review Simulation | 编译后的 PDF | 分数和弱点清单 | 多角色独立评分,把弱点路由回对应子 skill |
这里最有价值的部分是质量门禁:
- 文献先召回,再按 LQS 评分,再决定 A/B/C/D 引用深度。
- 每 20 条 citation 做一次 title、author、year、venue 检查,避免最后再批量补锅。
- claim strength 不能超过 evidence strength;默认用 conjecture / observation / remark,不轻易写 theorem。
- related work 不能只说“更近”,必须有结构性差异,例如新 taxonomy、新角度或新实验。
- 模拟审稿承担弱点路由功能:文献不够回 Literature,实验不严回 Experiment,结构不清回 Structure,图表不可比回 Figures。
这个模式和普通写作提示词的差别很大。普通提示词往往要求“写得像论文”;paper_writing 则规定“怎样一关一关把论文推进到可审稿状态”。
数字要谨慎读
Deli 的页面给了很多漂亮数字:四篇论文、1158 条引用、265 页、63+ subagents、约 44 小时、30 轮 review、8.5+ 平均分。这些数字适合用来观察产线规模,不适合直接推出论文质量结论。
评分来自 in-framework multi-persona simulated review。框架页也说明,这些分数只适合在同一协议内做纵向比较,不是外部同行评审结果。
论文索引页和 V2 博文的数据已经发生变化。V2 博文写三篇论文,论文索引页已经是四篇;V2 统计 941 条引用,索引页统计 1158 条。项目仍在更新,任何数字都需要带日期。
框架页还承认,伪造 citation 和数据 artifact 的错误来源仍然是 LLM 本身。框架只能把外部检查机械化,不能消灭错误源。
所以这件事的价值不在于“LLM 已经能独立产出可信论文”。更稳的结论是:当研究、写作、审稿、引用验证和长程状态都被 skill 化,agent 可以把综述型论文生产推进到一个可观察、可迭代、可审计的流程。
对本地研究 skill 的启发
本地 deep-research 已经有独立复核、反向搜索和最终报告全文重写,这些能力很强。AutoResearch / paper_writing 还能补几块工程化约束。
| 可吸收机制 | 放入 deep-research 的方式 |
|---|---|
| 证据账本 | 对每个核心结论记录 claim、source、verification、status、risk,最终报告只引用已过账的结论 |
| 分批引用复核 | citation-like 内容每 20 条做一次 title / author / year / venue / URL 存活检查,不等最后统一查 |
| 方向多样性 | Deep+ 研究中记录 tried directions;停滞时从反向假设、跨域类比、反例搜索切入 |
| 执行-评估分离 | 研究 agent 产出材料,独立 verifier 审计证据链,再进入综合报告 |
| 研究品味门 | 在大规模综述前先检查 scope、angle、audience、novelty,不让“资料很多”替代“问题值得研究” |
| 降级产物 | 网络、PDF、API 或登录墙失败时,输出 blocked claims 和 provenance,而不是把缺口藏进正文 |
其中“研究品味门”尤其重要。深度研究不是搜得越多越好,综述也不是引用越多越好。一个更好的研究 skill 应该在启动前问清楚三个问题:
| 问题 | 作用 |
|---|---|
| Scope:研究边界是什么 | 防止主题扩散到不可收敛 |
| Angle:新角度是什么 | 防止写成通用资料汇编 |
| Audience:给谁决策 | 决定证据深度、术语密度和输出形态 |
这三个问题的作用是避免把算力花在错误的问题上。
对本地写作 skill 的启发
本地 tech-writer 的核心是“把一个个问题变成一类类问题”。它默认服务技术文章、博客、教程、架构分析和观点文章,不应该被 paper_writing 带成论文腔。可吸收的是研究纪律:证据闸门、论断强度、弱点路由和回归检查。只有用户明确要论文、综述论文、学术写作或白皮书级研究时,才升级为 paper-like 模式。
| 可吸收机制 | 放入 tech-writer 的方式 |
|---|---|
| Topic Selection 三问 | 写综述或长文前确认 scope、angle、audience |
| Claim-Evidence-Implication | 每个强观点都必须有证据和“所以怎样”的推导,不只堆事实 |
| 论断强度 ≤ 证据强度 | 证据不足时降级为“观察”“推测”或“未决问题” |
| 同类内容差异化 | 写对比文章时说明结构差异,不用“更新”“更全”冒充贡献 |
| Review weakness routing | 审阅意见按文献、结构、实验、图表、论证、风格归类,直接路由到修订动作 |
| Regression check | 改完一轮后确认上一轮已修问题没有回退 |
这会让写作 skill 少一点“润色器”气质,多一点“技术编辑工作流”气质。写作质量不只来自句子顺,而来自材料分层、证据强度、论点约束和修订反馈闭环。
模式速查表
| 听到的需求关键词 | 对应模式 | 方案 |
|---|---|---|
| “帮我深度调研” | 证据账本 | 每个核心结论先入账,再进正文 |
| “做一个综述” | Scope-Angle-Audience | 先定义边界、角度、读者,再召回资料 |
| “资料很多,帮我整理” | A/B/C/D 引用深度 | 主角文献深入写,支撑文献只服务论点 |
| “这篇文章观点很强” | 论断强度闸门 | 证据不足就降级措辞,不硬写结论 |
| “长期自动跑研究” | State + Watchdog | 文件状态、心跳、停滞检测、强制 pivot |
| “审完帮我改” | Weakness routing | 把问题路由到文献、结构、实验、图表或风格 |
小结
Deli AutoResearch 值得追踪的地方,在于它把一组原本散落在提示词里的要求变成了可检查的流程:状态文件、心跳、停滞检测、文献评分、引用复核、结构写作、实验设计、模拟审稿、弱点路由。它还不能证明“AI 可以无人完成科学研究”,但已经给出了研究流水线工程化的样本。
这条线索可以放进更大的判断里:agent skill 的下一步不该停在“请认真一点”的提示词,而该把研究和写作拆成带状态、带门禁、带回归检查的工程流程。
难点仍落在 Deli 点出的那一层:研究品味。流程可以逼近稳定产出,但什么问题值得问,什么证据值得信,什么结论值得写,仍然是最难自动化的部分。
参考资料