oh-my-claudecode vs oh-my-openagent:两大 Agent 编排框架深度对比与实用教程
2026 年的 AI 编程工具生态中,单模型 CLI 已不再是终点。围绕 Claude Code 和 OpenCode 两大基座平台,不仅各自拥有原生的多 Agent 并行能力(Claude Code 的 Subagents 与 Agent Teams、OpenCode 的 Primary Agents 与 Subagents),还分别涌现出 oh-my-claudecode(OMC) 和 oh-my-openagent(OmO) 两个重量级多 Agent 编排插件。两者 GitHub star 数合计超过 9 万,代表了当前 Agentic Coding 编排层的两种核心思路:单模型深度增强 vs 多模型原生编排。
本文从基座原生能力讲起,逐步深入到插件层架构,对四种工作模式进行全维度对比,并提供可直接上手的实用教程与最佳实践决策指南。

TL;DR:日常命令选择指南
如果你只想知道"该用哪个命令",看这一节就够了。后面的章节是架构原理的深度解析。
OMC(Claude Code 生态)
1 | |
OmO(OpenCode 生态)
1 | |
日常实用命令速查
除了工作流命令,CC 和 OC 还有大量日常高频命令和快捷键。
Claude Code 单字符前缀:
| 前缀 | 功能 | 示例 |
|---|---|---|
/ |
斜杠命令 / 技能菜单 | /memory、/compact、/doctor |
! |
执行 shell,输出注入对话上下文 | ! git log --oneline -5 |
@ |
文件路径自动补全 | @src/config.ts 这个配置对吗? |
# |
快速保存持久记忆 | # 这个项目用 pnpm 不用 npm |
Claude Code 高频快捷键:
| 快捷键 | 功能 |
|---|---|
Shift+Tab |
轮转权限模式(default → acceptEdits → plan → auto) |
Option/Alt+P |
打开模型选择器 |
Option/Alt+T |
开关扩展思维 |
Option/Alt+O |
开关快速模式 |
Shift+Down |
Agent Teams 中切换队友 |
Esc |
中断当前响应;Esc Esc 清空输入或打开回退菜单 |
完整命令列表见后文"日常交互"章节,CC 记忆架构详解见"记忆与持久化"章节。
没装插件怎么办?
没有 OMC/OmO 时,你只能手动在 session 里写完整 prompt 描述每个步骤,手动检查结果,手动决定是否重试。插件的核心价值是把人工协调自动化——不提供基座做不到的底层能力,提供的是"不需要你盯着"的自动化流水线。
插件是否总跑得比原生更远? 是的。原生 CC/OC 执行完用户请求就停,插件增加了自动验证循环(verify/fix loop)和持久执行(ralph/autopilot)。这是插件层存在的核心理由:把"做完"升级为"做对"。
项目概览
| 维度 | oh-my-claudecode (OMC) | oh-my-openagent (OmO) |
|---|---|---|
| GitHub Stars | 33.7k | 57.6k |
| 基座平台 | Claude Code(Anthropic) | OpenCode |
| 主语言 | TypeScript 58% / JS 40% | TypeScript 93% |
| 许可证 | MIT | SUL-1.0 |
| 最新版本 | v4.13.7 (2026-05-09) | v4.1.1 (2026-05-13) |
| npm 包名 | oh-my-claude-sisyphus | oh-my-opencode / oh-my-openagent |
| 核心定位 | Teams-first Multi-agent orchestration for Claude Code | Multi-model agent harness for OpenCode |
| 创建者 | Yeachan Heo | code-yeongyu |
设计哲学对比
OMC:零学习曲线的 Claude 增强
OMC 的核心主张是 “Don’t learn Claude Code. Just use OMC.” 在 Claude Code 生态内部做深度增强,通过 19 个专业 Agent、智能模型路由(Haiku 处理简单任务,Opus 处理复杂推理)和魔法关键词触发机制,将多 Agent 编排的复杂性隐藏在自然语言交互之下。
设计假设:Claude 系列模型已足够强大,编排层的核心价值在于将单一模型的能力最大化——通过 Agent 专业化分工、持久化执行循环和自动验证机制来实现。
OmO:多模型原生编排
OmO 的 Ultrawork 宣言开宗明义:“human intervention during agentic work represents system failure”(人类在 Agent 工作中的干预代表系统故障)。设计理念建立在一个核心判断之上——没有任何单一 AI 供应商能在所有任务类型上保持最优,因此需要根据任务特征将工作路由到最合适的模型。
设计假设:不同模型有不同的认知特长(Claude 擅长结构化输出、GPT 擅长显式推理、Gemini 擅长视觉任务),编排层的核心价值在于跨模型协调——通过分类路由、后备链和累积学习来实现。
基座平台的原生编排能力
在深入 OMC 和 OmO 的架构之前,需要先理清它们各自基座平台的原生多 Agent 能力。这些能力是插件框架赖以存在的土壤,理解它们的优劣和边界,是判断"何时用原生、何时上插件"的前提。
Claude Code 原生能力:Subagents 与 Agent Teams
Claude Code 在 v2.1.32(2026 年 2 月)引入了实验性的 Agent Teams 功能,与已有的 Subagents 构成了两级并行工作体系。两者本质区别在于通信拓扑:
Subagents(子代理):主代理在工作流中临时派生一个独立会话,分配一个聚焦任务。子代理完成工作后,将结果摘要回报给主代理。子代理之间不能直接通信,只与主代理单向汇报。适合不需要横向协调的独立任务——比如并行搜索代码库、同时审查不同模块。Token 开销较低,因为结果被压缩为摘要后注入主上下文。
Agent Teams(代理团队):Team Lead(主会话)派生多个完全独立的 Claude Code 实例作为 Teammates。每个 Teammate 拥有自己的上下文窗口、加载相同的项目配置(CLAUDE.md、MCP、Skills),但不继承 Lead 的对话历史。关键差异在于:
- 共享任务列表:Lead 创建任务(pending → in progress → completed),Teammates 可以自领任务,支持任务间依赖和文件锁防竞态
- 同伴直接通信:Teammates 可以通过 Mailbox 系统互相发消息,不经过 Lead 中转
- 计划审批:可以要求 Teammate 先出计划,Lead 审核通过后再实施
- 显示模式可选:In-process(Shift+Down 切换队友)或 Split Panes(tmux/iTerm2)
1 | |
Agent Teams 的最佳场景是需要横向协作的复杂任务——比如多视角代码审查(安全/性能/测试各一个 Teammate)、竞争假设调试(各自验证不同根因,互相挑战对方的理论)、跨层协调(前端/后端/测试各一个 Teammate)。
与 Subagents 的选择决策:社区普遍认为 Subagents 覆盖约 90% 的并行需求,Agent Teams 覆盖剩下的 10%。如果你只需要"把活分出去,收结果回来",Subagents 就够了;如果你需要"队友之间互相讨论、互相挑战",才需要 Agent Teams。
关键限制:Agent Teams 当前仍是实验性功能——不支持会话恢复(/resume 后 Teammates 消失)、任务状态可能滞后、一次只能管理一个团队、Teammates 不能嵌套派生子团队、Lead 身份不可转移。
OpenCode 原生能力:Primary Agents 与 Subagents
OpenCode 的原生 Agent 体系比 Claude Code 更简洁但同样完整。它不区分"Agent Teams"和"Subagents"两种模式,而是统一通过 Agent 类型+权限系统 实现分级并行:
Primary Agents(主代理):通过 Tab 键切换。内置两个:
- Build:默认代理,所有工具可用,用于日常开发
- Plan:受限代理,文件编辑和 Bash 默认设为
ask(需确认),用于分析和规划而不实际修改代码
Subagents(子代理):可被主代理自动调用或通过 @mention 手动触发。内置三个:
- General:全工具访问(除 todo),适合多步骤复杂任务
- Explore:只读,用于快速探索代码库、搜索文件
- Scout:只读,用于外部文档和依赖研究(可克隆依赖仓库到托管缓存中检查源码)
OpenCode 的 Agent 系统刻在配置层提供了细粒度的控制:
- 权限模型:每个 Agent 可独立设置
permission(read/edit/bash/task/websearch 等),支持 glob 模式(如bash: {"git push": "ask", "grep *": "allow"}) - 模型绑定:每个 Agent 可指定不同模型(Build 用 Opus、Plan 用 Haiku、Review 用 Sonnet)
- Markdown 定义:支持通过
.md文件定义 Agent,放在~/.config/opencode/agents/或.opencode/agents/ - 温度/步数/颜色:每个 Agent 可独立配置 temperature、max steps、UI 颜色
与 Claude Code 的关键差异:OpenCode 的 Subagents 之间没有原生的直接通信能力(只有父子通信),没有共享任务列表,也没有 Agent Teams 那样的同伴协作机制。这也是为什么 OmO 这样的插件层需要自己实现团队模式。
值得注意:OpenCode 社区在 2026 年 2 月独立实现了自己的 Agent Teams(PR #12730-#12732),架构上参考了 Claude Code 但做了改进——事件驱动唤醒替代轮询、JSONL 追加写入替代 JSON 数组全量读写、完整的同伴直接通信。不过这个实现目前仍在 dev 分支,尚未进入主线。
架构对比

OMC 的双表面架构:Session 内编排 + CLI 进程隔离
OMC 在两个运行表面上提供能力:
1 | |
Session 内通过插件系统运行 Agent 编排(team 管道、ralph 循环等);CLI 层通过 tmux 进程隔离的方式启动 Codex、Gemini 等第三方 CLI 工作节点。两个表面共享 skill 系统和状态存储。
Team 模式的执行管道:plan → prd → exec → verify → fix(循环)。
为什么 OMC 需要两个表面? 根因是 Codex CLI 和 Gemini CLI 是独立的操作系统进程,它们不是一次 API 调用,而是各自拥有完整工具链(文件读写、bash 执行、自己的 context window)的独立 agentic coding 进程。这些进程无法跑在 Claude Code 的 Session 内部——就像你不能在一个 Chrome 标签页里启动一个 Firefox 实例。tmux 提供了进程隔离的基础设施:每个 CLI 跑在自己的 tmux pane 里,互不干扰,OMC 通过 tmux IPC 协调它们的输入输出。
为什么 OmO 不需要这种分离? 因为 OmO 调多模型的方式是 API 级别的——它给 GPT-5.5 发一个 API 请求拿到推理结果,给 Gemini 发一个 API 请求拿到视觉分析结果,然后在 OpenCode 的 Session 内部组装这些结果。API 调用不需要独立进程,不需要独立工具链,所以不需要第二个运行表面。代价是 OmO 拿到的只是模型的"大脑"(推理能力),没有独立 agent 进程的"手脚"(独立的 bash、独立的文件系统访问)——所有工具操作仍然由 OpenCode 本体执行。
一句话总结:OMC 的双表面 = "启动独立 CLI 进程"的必然代价;OmO 的单表面 = "只调 API 不启动进程"的自然结果。
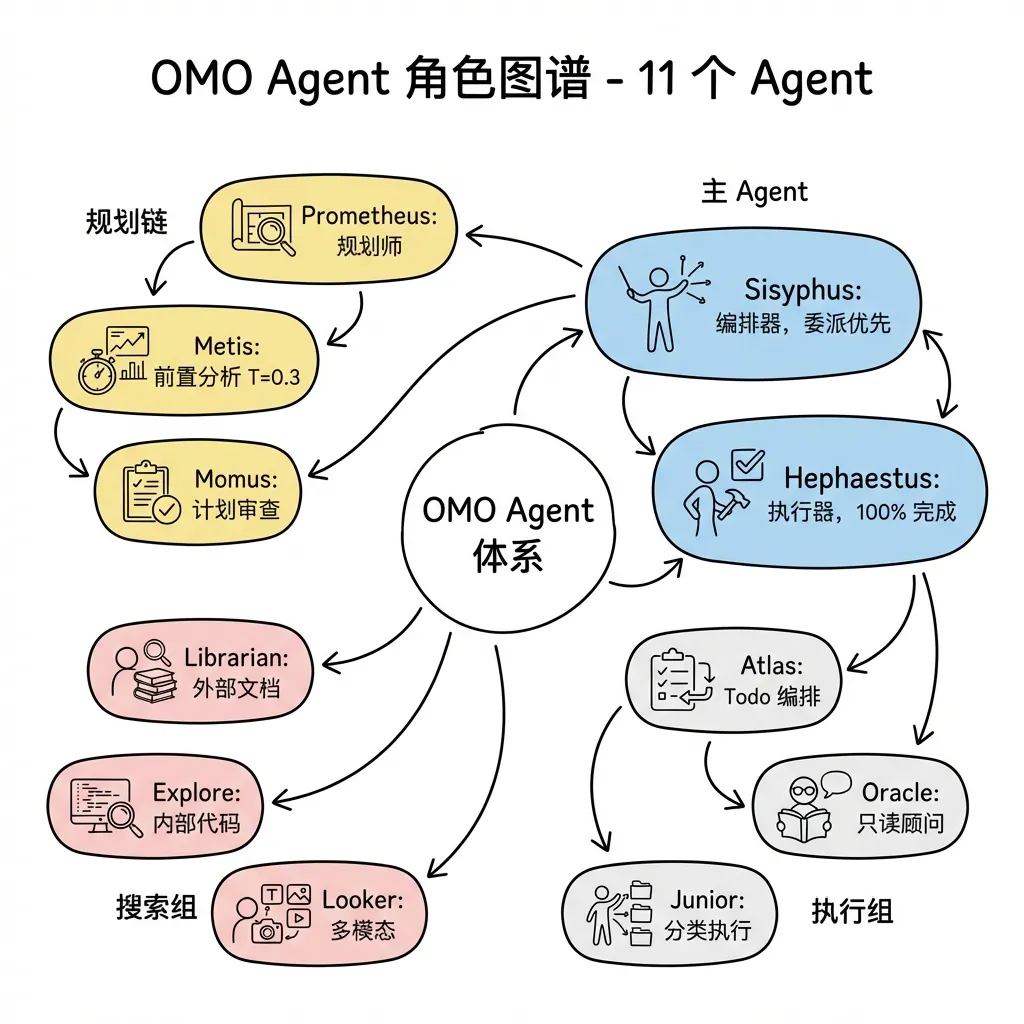
OmO 的三层架构:规划-调度-执行
OmO 采用规划-调度-执行三层分离的设计。注意这里的用词:中间层叫"调度"而非"执行"——Atlas 的职责是读计划、分任务、验结果,自己不写一行代码。真正写代码的是最底层的 Worker Agent(Sisyphus-Jr、Oracle、visual-engineer)。如果把中间层也叫"执行",就和底层的"干活"混为一谈了。
类比军事指挥链:参谋部(规划)→ 战场指挥官(调度)→ 士兵(执行)。参谋部出作战计划,指挥官在前线分配阵地、协调火力、验收战果,但指挥官不亲自冲锋——冲锋是士兵的事。
1 | |
关键设计约束:Prometheus 只能写 Markdown 计划,Atlas 不能写代码,Junior 不能委托——严格的角色隔离防止职责混淆。
为什么需要把"调度"从"执行"中独立出来? 因为 OmO 的多模型路由需要一个不偏不倚的裁判。Atlas 不绑定任何特定模型,它的工作是根据任务类型(visual/deep/quick)决定哪个 Worker 来接活,然后验收结果。如果 Atlas 自己也写代码,它就既是运动员又是裁判——无法客观评估 Worker 的产出质量。这是 OmO 三层架构存在的核心理由:规划者不调度,调度者不干活,干活者不自评。
OMC 也分计划和执行——只是分法不同
一个常见的误解是"OmO 分了三层所以更有纪律,OMC 没分层所以比较粗放"。事实上 OMC 也严格分离了计划和执行,只是用的是管道式分离(时间维度)而非 OmO 的层级式分离(权限维度)。
OmO 的层级式分离:三个永久角色同时存在,通过权限硬约束隔离——Prometheus 永远不能改代码,Atlas 永远不能写代码,Junior 永远不能委托别人。角色之间是上下级关系:规划者出计划 → 调度者分任务 → 执行者干活。类比军队的参谋部/指挥官/士兵。
OMC 的管道式分离:角色按时间阶段依次上场,同一时刻只有一个角色在工作——plan 阶段由 architect Agent 出方案,prd 阶段由 designer Agent 细化需求,exec 阶段由 executor Agent 写代码,verify 阶段由 verifier Agent 检查结果,fix 阶段由 executor 修复问题。类比工厂流水线:设计部画图纸 → 工艺部写工序 → 车间生产 → 质检部验收 → 返工。
1 | |
为什么 OMC 不需要层级式分离? 因为 OMC 运行在 Claude Code 的 Session 内——所有 Agent 共享同一个上下文窗口,管道的每个阶段能自然地读到上一阶段的产出。Atlas 式的"调度者"角色在这里是多余的:管道本身就是调度——plan 产出方案,exec 读方案执行,verify 验结果,不需要一个中间人转发。
为什么 OmO 需要层级式分离? 因为 OmO 要跨多个模型协调——Gemini 不知道 GPT 在做什么,GPT 不知道 Claude 写了什么计划。必须有一个"调度者"(Atlas)持有全局视图,把计划拆解后分发给不同模型的 Worker,再收集验证结果。如果没有 Atlas,各 Worker 只能各干各的,无法协调。
一句话:OMC 的管道本身就是调度机制,所以不需要单独的调度层;OmO 的多模型天然需要一个协调者,所以必须有调度层。
架构差异的本质
| 维度 | OMC | OmO |
|---|---|---|
| 模型策略 | Claude 为主,Codex/Gemini 为辅助 | 多模型平等,按分类路由 |
| Agent 命名 | 功能导向(executor, verifier) | 神话导向(Sisyphus, Prometheus) |
| 角色隔离 | 管道式软隔离(阶段区分:plan/exec/verify) | 层级式硬隔离(权限限制:规划/调度/执行) |
| 分离策略 | 时间维度(阶段串行,同一时刻一个角色) | 空间维度(三层并存,权限永久隔离) |
| 上下文管理 | Session 内压缩 + 技能注入 | 累积学习 + boulder.json 持久化 |
| 多模型实现 | 进程级(tmux 独立 CLI) | API 级(分类路由到不同模型) |
映射到 Multi-Agent 通信拓扑
将上述架构放到 Multi-Agent 理论的四种通信拓扑(Independent / Centralized / Decentralized / Hybrid)中,可以得到精确的定位:
| 模式 | 通信拓扑 | 映射理由 |
|---|---|---|
| Claude Code Subagents | Centralized | 主代理持有全局视图,分配任务、聚合结果;子代理只向主代理单向汇报,彼此不通信——教科书式的星型中心化架构 |
| Claude Code Agent Teams | Hybrid | Lead 层面是 Centralized(创建任务列表、审批计划、综合结论),Teammate 层面部分 Decentralized(Mailbox 系统允许同伴直接通信、自领任务,不经 Lead 中转) |
| OpenCode Subagents | Centralized | 与 CC Subagents 等价——父子星型通信,子代理之间无直接通道 |
| OMC 19 个 Agent(Session 内) | Hybrid(依托 CC Agent Teams 基础设施) | Team Pipeline 本身是 L3 Workflow(开发者控制流程),但底层 Teammates 之间通过 Mailbox 有横向通信能力 |
| OmO Team Mode | Hybrid(自建通信) | Atlas 作为 Centralized 指挥官分配任务,成员之间通过 tmux 可视化 + 插件自建协议实现横向通信 |
关键澄清:Subagents ≠ Decentralized。 Decentralized 的定义是"没有中央协调者,每个 Agent 自己决定何时与谁通信"(如 OpenAI Swarm 的 Handoff)。Subagents 恰恰有一个强力中央——主代理全程介入任务分配和结果聚合。正确的映射是 Subagents = Centralized。
Subagents 的 Scale-Out 特性
Subagents 模式天然支持横向扩展。其本质是"一个配置定义 = 一个 agent 实例":
- Claude Code:在
CLAUDE.md或 Skill 文件中定义角色 prompt + 工具权限 → 主代理按需派生任意数量的 subagent - OpenCode:在
~/.config/opencode/agents/*.md或.opencode/agents/*.md中放一个 Markdown 文件 → 自动注册为可调用的 subagent
这正是 Centralized 架构的工程优势:Orchestrator 只需要一个"注册表"来知道有哪些 subagent 可调,新增 agent 不需要改通信协议或编排逻辑——只需多放一个 .md 配置文件。OMC 的 19 个 Agent、OmO 的命名 Agent 体系,本质上都是在这个 scale-out 机制上叠加了预定义的角色 prompt。
这意味着:任何团队都可以基于 CC/OC 搭建自己的 agent 集群,门槛只是写 Markdown 或 JSON 配置。 不需要写代码、不需要理解内核——这是 Subagents 模式对开发者最友好的特征。
原生 Agent vs 插件 Agent:实现层差异
这是理解 OMC/OmO 定位的核心区分。两者的 Agent 运行在完全不同的抽象层:
1 | |
核心差异总结:
| 维度 | 原生 Agent | 插件 Agent |
|---|---|---|
| 类比 | 操作系统的 fork() + IPC |
用 fork() + IPC 搭建的 supervisor 进程池应用 |
| 调度权 | 模型自主决策(L4) | 插件编排代码调度(L3 Workflow) |
| 上下文隔离 | 物理隔离(独立 context window) | 逻辑隔离(同 Session 内 prompt 前缀区分,或 tmux 进程隔离) |
| 通信 | 内核功能(Mailbox、文件锁) | 应用层协议(Session 上下文传递 / boulder.json / tmux IPC) |
| 模型选择 | 受平台限制(CC 只能 Claude 系列) | 可跨供应商(tmux 启动 Codex/Gemini CLI 或 API 路由) |
简言之:原生 Agent 是平台提供的"计算原语",插件 Agent 是在这些原语之上搭建的"应用程序"。插件 Agent 本身不创造新的隔离机制或通信通道——它利用原生 subagent 原语,叠加预设 prompt + 编排逻辑,组合成更高层的自动化工作流。
OMC 和 OmO 各自额外做了什么(超越原生能力)
既然 CC 已有 Agent Teams、OC 已有 Subagents,为什么还需要插件层?
OMC 超越 CC Agent Teams 原生的部分:
| 能力 | Agent Teams 原生 | OMC 补充 |
|---|---|---|
| 工作流自动化 | 无——Teammates 是"白纸",需要手动描述角色和任务 | Team Pipeline(plan→prd→exec→verify→fix 闭环),无需手写 prompt |
| 跨供应商模型 | 只能用 Claude 系列 | tmux 启动 Codex/Gemini CLI 作为独立工作节点 |
| 持久执行循环 | 无内置"验证失败自动重试" | /ralph(verify/fix 无限循环)、/autopilot(无人值守) |
| 预定义角色库 | 每次需从头描述 | 19 个 Agent 开箱即用 |
| 智能模型路由 | 无——统一用配置的模型 | 简单任务→Haiku,复杂推理→Opus,自动切换 |
| 三模型合成 | 做不到 | /ccg(Claude+Codex+Gemini 交叉验证) |
OmO 超越 OC Subagents 原生的部分:
| 能力 | OC 原生 | OmO 补充 |
|---|---|---|
| 同伴通信 | ❌ Subagents 之间不能直接通信 | Team Mode(最多 8 个并行成员 + 自建通信协议) |
| 多模型路由 | 每个 Agent 可配不同模型,但需手动指定 | 按任务类型自动分类路由(visual→Gemini, deep→GPT, quick→Mini) |
| 累积学习 | 无跨任务经验传递 | boulder.json 持久化 conventions/gotchas,跨任务传递 |
| 对抗性审查 | 无 | hyperplan(5 个敌对 Agent 审查计划)、security-research |
| 编辑可靠性 | 依赖原生编辑工具 | Hashline 哈希锚定编辑(编辑成功率 6.7%→68.3%) |
关键事实:OMC 和 OmO 都能调多模型,也都能调多 agent——差异在于实现方式(进程级 vs API 级),而非能力有无。OmO 不是"只能调多模型"——它的 Team Mode 成员都是带角色 prompt 和独立身份的 agent 实例。
OMC 能调"多 Agent CLI",OmO 只能调"多模型 API"——这是基座架构决定的。 这里的"多 Agent"不是指抽象的 subagent 实例,而是指 Gemini CLI、Codex CLI 这样独立的 agentic coding 进程——它们各自是一个完整的编码 agent(有自己的 context、工具链、执行循环),不是一次 API 调用。OMC 通过 tmux 启动这些独立 CLI 进程作为工作节点(omc team 2:codex "..."、omc team 2:gemini "..."),每个进程是一个完整的、可独立运行的编码 agent 实例。OmO 则只能通过 API 调用不同模型的推理能力——它拿到的是模型的"大脑",但没有一个独立运行的 agent 进程(没有独立的工具循环、没有独立的文件系统访问、没有独立的 bash 执行能力)。
为什么 OmO 做不到这一点?根因在 OC 的架构:OC 没有原生的进程级 agent 编排能力(不像 CC 有 tmux worker pane 的设计),所以 OmO 只能在 API 级别做模型路由——调不同模型的接口,但无法启动一个独立的 Codex CLI 或 Gemini CLI 进程让它自主跑任务。这是 CC 生态独有的能力:CC 的 tmux 架构允许在同一终端里启动任意数量的独立 CLI agent 进程,每个进程有自己的工具链和执行权限,OMC 利用了这个基础设施。
两者的共同架构本质:OMC 和 OmO 最终都落在 Hybrid 架构——高层 Centralized(OMC 的 Lead / OmO 的 Atlas 作为指挥官),底层部分 Decentralized(Teammates / 成员之间有横向通信能力)。两者的同伴通信都有"自建"成分:OMC 利用了 CC 原生 Mailbox 但 pipeline 状态传递是插件自建的;OmO 则完全自建(因为 OC 原生不支持同伴通信)。差异只在于自建比例——OMC 约 30% 自建 + 70% 原生基础设施,OmO 约 90% 自建 + 10% 原生(仅复用 OC 的 subagent 派生机制)。
日常交互:命令、快捷键与权限模式
前面几章讨论的是"编排怎么跑"——Team Pipeline、Atlas 调度、Ralph 循环。但日常开发中,更多时间花在基础交互上:切模型、存记忆、管权限、看开销、压上下文。这些操作在 CC 和 OC 中有不同的入口。
CC 命令体系
Claude Code 的交互入口由三部分组成:斜杠命令(/)、单字符前缀(!、@、#)和快捷键。
斜杠命令
CC 的斜杠命令按功能分为六类。
会话管理
| 命令 | 别名 | 功能 |
|---|---|---|
/resume |
/continue |
恢复历史会话 |
/clear |
/reset、/new |
清空上下文开新会话 |
/branch <name> |
/fork |
复制当前会话为新分支 |
/rewind |
/checkpoint、/undo |
回滚到历史 checkpoint |
/compact [指令] |
— | 压缩上下文释放窗口,可带聚焦指令 |
/rename <name> |
— | 重命名当前会话 |
/background |
/bg |
将当前会话转入后台运行 |
/export [filename] |
— | 导出对话为纯文本 |
模型与推理
| 命令 | 功能 |
|---|---|
/model [model] |
设置模型,无参数打开选择器(含 effort 滑块),按 d 保存为默认 |
/effort [level] |
设置推理 effort:low / medium / high / xhigh / max |
/plan [描述] |
直接进入 plan 模式 |
监控与诊断
| 命令 | 别名 | 功能 |
|---|---|---|
/cost |
/usage、/stats |
查看 token 开销和累计费用 |
/status |
— | 版本、模型、账户、连接状态(响应中也可用) |
/doctor |
— | 诊断安装和设置问题,按 f 自动修复 |
/context [all] |
— | 可视化上下文占用(彩色网格 + 优化建议) |
/diff |
— | 交互式 diff 查看器 |
配置与权限
| 命令 | 别名 | 功能 |
|---|---|---|
/config |
/settings |
打开设置 UI |
/permissions |
/allowed-tools |
管理 allow/ask/deny 规则 |
/memory |
— | 浏览所有 CLAUDE.md 和 auto memory,可开关 auto memory |
/init |
— | 生成初始 CLAUDE.md |
/mcp |
— | 管理 MCP 服务器连接 |
/login / /logout |
— | 登录/登出 Anthropic 账户 |
高级执行
| 命令 | 功能 |
|---|---|
/goal [条件] |
设定目标,Claude 持续工作直到满足 |
/loop [间隔] [指令] |
定时循环执行指令 |
/batch <指令> |
大规模并行变更(5-30 个 worktree) |
/btw <问题> |
旁白提问,不写入主对话历史 |
审查
| 命令 | 功能 |
|---|---|
/code-review |
审查当前 diff 的正确性 |
/security-review |
分析待提交变更的安全漏洞 |
单字符前缀
CC 有四个单字符前缀,各自进入不同的交互语境:
| 前缀 | 名称 | 功能 | 使用示例 |
|---|---|---|---|
/ |
命令 | 触发斜杠命令或 skill | /memory、/team |
! |
Shell | 在当前终端执行 shell 命令,输出注入对话上下文 | ! git status |
@ |
文件引用 | 自动补全文件路径,将文件内容注入上下文 | @src/config.ts 这个 timeout 值对吗? |
# |
记忆 | 快速保存一条持久记忆 | # API 测试需要本地 Redis |
! 和"在另一个终端跑命令"的区别在于上下文注入。! cat error.log | tail -20 的输出会进入 Claude 的对话上下文,Claude 可以直接基于输出推理。如果你在另一个终端跑同样的命令,Claude 完全看不到结果——你得手动把输出粘贴过来。! 让"跑命令"和"讨论结果"在同一个上下文里完成。
快捷键
模型与模式切换
| 快捷键 | 动作 | 解决的问题 |
|---|---|---|
Shift+Tab |
轮转权限模式 | 在 default / acceptEdits / plan / auto 之间一键切换 |
Option/Alt+P |
打开模型选择器 | 快速换模型(如 Sonnet → Opus) |
Option/Alt+T |
开关扩展思维 | 复杂推理时打开,简单任务时关闭 |
Option/Alt+O |
开关快速模式 | Fast mode 用更快的输出配置 |
中断与回退
| 快捷键 | 动作 |
|---|---|
Esc |
中断 Claude 当前正在生成的响应 |
Esc Esc |
清空输入草稿;输入为空时打开回退菜单 |
Ctrl+C |
中断 / 清空输入 / 退出 |
Ctrl+D |
退出会话 |
界面与上下文
| 快捷键 | 动作 |
|---|---|
Ctrl+O |
打开 transcript 查看器(查看工具调用的完整输出) |
Ctrl+T |
切换任务列表显示 |
Ctrl+R |
反向搜索命令历史 |
Ctrl+V / Cmd+V |
粘贴剪贴板中的图片 |
Ctrl+S |
暂存当前输入草稿 |
编辑器与换行
| 快捷键 | 动作 |
|---|---|
Ctrl+G 或 Ctrl+X Ctrl+E |
在外部编辑器中编辑当前输入 |
\ + Enter |
换行(所有终端通用) |
Ctrl+J |
换行(替代方案) |
Shift+Enter |
换行(iTerm2、WezTerm、Ghostty、Kitty 等原生支持) |
Agent Teams 专用
| 快捷键 | 动作 |
|---|---|
Shift+Down |
切换到下一个队友(In-process 模式专用) |
Enter |
查看选中队友的会话 |
Ctrl+X Ctrl+K |
终止所有后台 subagent |
Shift+Tab 解决什么问题
CC 的权限系统有多个模式,控制 Claude 对工具的自主权:
| 权限模式 | 行为 |
|---|---|
default |
读文件放行,写文件和 bash 需要确认 |
acceptEdits |
文件编辑放行,bash 仍需确认 |
plan |
只分析不改代码,编辑和 bash 需确认 |
auto |
所有工具自动放行(最大自主权) |
日常开发中这些模式的切换非常频繁:先用 plan 让 Claude 分析方案,确认后切到 acceptEdits 改代码,改完切回 default 防止误操作。如果每次都进 /config 改设置,思路就被打断了。Shift+Tab 一键轮转,让权限切换和思考切换一样自然。
这和 OpenCode 的 Tab 切换 Primary Agent 思路相似:OC 用 Tab 在 Build(全工具)和 Plan(受限)之间切换,解决的是同一个问题——在分析和执行之间快速切换。区别在于 CC 切的是"权限级别",OC 切的是"Agent 角色"。
Esc 系列:中断与回退
Esc 解决的是"Claude 正在说的话不对,我要立刻打断它"。不需要等它说完再纠正,按 Esc 中断后直接给新指令。这在 Agent 长链路执行时尤其有用——看到 Claude 开始改错文件、走错方向,立刻中断比等它犯完错再回滚成本低得多。
Esc Esc(双击)的行为取决于输入框状态:有内容时清空它(相当于"算了换个说法"),空的时候打开回退菜单(和 /rewind 等价,让你回到之前的 checkpoint)。
OC / OmO 对应命令
OpenCode 的命令体系更简洁。核心对应关系:
| CC 命令/快捷键 | OC 等价操作 | 说明 |
|---|---|---|
Shift+Tab 切权限模式 |
Tab 切 Primary Agent |
OC 用 Agent 切换代替权限模式切换 |
/model |
Agent 配置中 model: 字段 |
OC 每个 Agent 绑定一个模型 |
/memory |
无直接等价 | OC 没有原生 auto memory |
/compact |
/compact |
同样支持上下文压缩 |
/doctor |
bunx oh-my-opencode doctor |
OmO 提供环境诊断 |
@ 文件引用 |
@mention 文件或 Agent |
OC 的 @ 同时支持文件和 Agent |
! shell 执行 |
终端直接执行 | OC 的 TUI 可直接访问终端 |
# 记忆 |
无直接等价 | OmO 走不同的知识持久化路线(见下节) |
OmO 增加的命令主要是工作流级别的(ulw、hyperplan、@plan、/start-work),日常实用命令沿用 OC 原生。
记忆与持久化:跨会话的知识管理
一次 Agent 会话有终点,但项目知识不应该随 session 结束而消失。CC 和 OmO 在跨会话知识管理上走了不同路线:CC 构建了面向人和偏好的记忆系统,OmO 构建了面向代码和经验的学习系统。
CC 的三层记忆架构
Claude Code 的记忆系统由三个机制组成:
1 | |
三层的分工:CLAUDE.md 告诉 Claude 该怎么做,Rules 告诉它什么条件下该怎么做,Memory 告诉它关于你和你的项目的已知事实。
CLAUDE.md 多层级加载
CLAUDE.md 按从宽到窄的顺序叠加,内容拼接而非覆盖:
- 组织级(macOS:
/Library/Application Support/ClaudeCode/CLAUDE.md)——不可跳过 - 用户级(
~/.claude/CLAUDE.md)——个人全局偏好 - 从文件系统根到当前工作目录的每一级
CLAUDE.md+CLAUDE.local.md - 子目录 CLAUDE.md 在 Claude 读取该目录文件时按需加载
CLAUDE.local.md 是 .gitignore 友好的个人覆盖文件。关键限制:每个 CLAUDE.md 建议不超过 200 行——过长会挤压实际工作的上下文空间。
.claude/rules/ 模块化规则
Rules 解决两个问题:“CLAUDE.md 太长"和"有些规则只在特定文件里才需要”:
1 | |
无 paths: 的规则在 session 启动时全量加载;有 paths: 的规则只在 Claude 读取匹配文件时注入——大幅减少上下文占用。
Auto Memory 自动记忆
Auto Memory 是 CC 最独特的设计:Claude 自动决定什么值得记住。
触发方式有三种:
- 自然语言:“记住这个项目用 pnpm” 或 “remember the API needs Redis”
#前缀:# 测试必须用真实数据库不能 mock——快速保存,不触发完整对话- Claude 主动:用户纠正做法(“不要这样”“别用那个库”)或确认非显而易见的做法时自动保存
记忆分四种类型:
| 类型 | 记什么 | 示例 |
|---|---|---|
user |
用户角色、知识水平、偏好 | “后端资深但 React 新手” |
feedback |
用户对做法的纠正或确认 | “不要 mock 数据库” |
project |
项目动态、截止时间 | “3月5日开始合并冻结” |
reference |
外部资源位置 | “pipeline bugs 在 Linear INGEST 项目” |
每条记忆是一个独立 .md 文件,带 YAML frontmatter:
1 | |
MEMORY.md 是索引文件:每行一条摘要链接,前 200 行(或 25KB)在 session 启动时加载,超出部分不加载。因此 MEMORY.md 必须保持精简——详细内容放在各记忆文件里。
记忆加载顺序
Session 启动时完整的加载链:
- 组织级 CLAUDE.md
- 用户级
~/.claude/CLAUDE.md - 用户级规则
~/.claude/rules/ - 从根到工作目录的每级 CLAUDE.md + CLAUDE.local.md
- 项目
.claude/rules/中无paths:的规则 - MEMORY.md 前 200 行 / 25KB
- 子目录 CLAUDE.md 和带
paths:的规则 → 按需加载
/compact 后项目根的 CLAUDE.md 会重新从磁盘读取注入;子目录的不会自动重注入。
CC 记忆使用技巧
精简 CLAUDE.md:把编码细节拆到 .claude/rules/,CLAUDE.md 只写"不看规则文件就会犯的错误"。
用 path-scoped rules 减噪:前端规则不需要在改后端代码时加载。加 paths: 让规则条件触发。
写可验证的指令:“用 2 空格缩进"而不是"格式化好代码”。“API 返回用 snake_case"而不是"保持一致风格”。
用 # 随手保存发现:调试中发现"这个模块的测试必须串行跑"——立即 # 这个模块测试必须串行 保存。下次会话不需要重新发现。
同一 Git 仓库共享记忆:auto memory 目录基于 Git 仓库根路径派生,所有 worktree 和子目录共享同一份记忆。
/memory 是记忆的入口:它列出当前加载的所有 CLAUDE.md、rules 和 auto memory,可以直接打开编辑或开关 auto memory。
OmO 的知识持久化
OmO 没有 CC 那样的 auto memory——不会自动记住"用户偏好 tabs"。OmO 的持久化面向代码和任务经验,而非人和偏好。
AGENTS.md
OpenCode 的 AGENTS.md 功能上等价于 CLAUDE.md——项目级指令文件,所有 Agent 启动时加载。区别是 OC 没有多层级叠加(没有用户级、组织级、子目录级),也没有 CLAUDE.local.md 式的个人覆盖。
boulder.json 与累积学习
OmO 的核心持久化机制是 boulder.json(取名自 Sisyphus 推的巨石)。它记录的不是"用户是谁",而是代码和任务中学到的经验:
| 字段 | 记什么 | CC 近似 |
|---|---|---|
conventions |
代码约定:“API 返回用 camelCase” | CLAUDE.md / rules |
gotchas |
踩过的坑:“migration 文件不能直接改” | feedback 类型 memory |
notes |
执行观察:“auth 模块正在重写” | project 类型 memory |
progress |
任务进度、已完成步骤 | 无直接对应 |
关键差异在于累积方向。CC 的 auto memory 向内累积——记住关于用户和交互的经验。OmO 的 boulder 向外累积——记住关于代码和任务的经验。每完成一个子任务,Atlas 把学到的 convention 或 gotcha 写入 boulder,下一个 Worker 启动时读取,不需要重新发现。
这在多模型环境下尤其重要。GPT-5.5 刚发现"这个项目 migration 用 timestamp 命名"——如果不写入 boulder,下一个被路由到 Gemini 的任务会犯同样的错误。boulder 是跨模型的经验传递通道。
CC 记忆 vs OmO 知识持久化
| 维度 | CC Auto Memory | OmO boulder + conventions |
|---|---|---|
| 记住关于谁 | 人(用户角色、偏好、纠正) | 代码(约定、陷阱、进度) |
| 谁来写 | Claude 自动 + 用户 # 触发 |
Atlas 在子任务验证后写入 |
| 存储格式 | YAML frontmatter + Markdown | JSON(boulder.json) |
| 加载时机 | session 启动自动加载索引 | 每个子任务启动时读取 |
| 跨会话 | ✅ 永久保留 | ✅ 文件持久化 |
| 跨模型 | 不涉及(CC 只用 Claude) | ✅ GPT 的发现传给 Gemini |
| 类型系统 | user / feedback / project / reference | conventions / gotchas / notes / progress |
两者互补而非替代。 CC 的 auto memory 保存"你是谁、你怎么工作",OmO 的 boulder 保存"代码有什么规矩、做到哪了"。如果在 CC + OMC 生态里工作,CC 记忆和 OMC 的 skill/状态系统分别覆盖这两个维度。OmO 用 boulder 同时覆盖了部分 CC auto memory 的功能(project 和 feedback 类信息),但缺少 user 类型的个性化记忆。
会话管理:Fork、Resume 与上下文生命周期
讨论 OMC、OmO、OC、CC 时,容易把 fork 和 subagent、team、workflow 混在一起。它们解决的不是同一个问题。
Subagent / Team / OMC / OmO 解决的是"怎么把活分出去"。 Fork 解决的是另一件事:当前这条对话线要不要复制出一条新分支。它不直接提高模型能力,也不自动多开 worker,而是保护会话历史和上下文,让同一个任务可以从某个中间点走出不同路线。
可以把一次 AI 编程会话想成一条 Git 分支:
1 | |
fork 的价值主要有三类。
第一,保留原路线。如果一个会话已经完成了需求澄清、代码阅读、约束总结,这些上下文很贵。直接在原会话里说"换个方案试试",后续上下文会混入失败尝试;fork 则复制当前上下文,在新分支里试错,原会话仍然干净。
第二,防止两个终端写进同一条会话。Claude Code 官方文档明确提醒:如果在两个终端里恢复同一个 session,消息会交错写入同一份 transcript。fork 后再继续,相当于给第二个终端一份独立副本,不会把两边的对话搅在一起。
第三,给 OMC / OmO 这类长流程留退路。例如准备运行 /team、/ralph、ulw、hyperplan 之前,先 fork 一条实验分支。插件可以在分支里跑完整流水线;如果结果不满意,原来的分析会话还在,不需要从头向模型解释项目背景。
Claude Code 里怎么找回会话
Claude Code 的会话是按项目目录保存的。命令行最常用的入口有三个:
1 | |
在已经打开的 Claude Code 会话里,也可以输入:
1 | |
会话选择器里几个快捷键最实用:
| 快捷键 | 用途 |
|---|---|
↑ / ↓ |
上下选择会话 |
Space |
预览会话内容 |
Enter |
恢复选中的会话 |
Ctrl+R |
给选中的会话改名 |
Ctrl+B |
只看当前 Git 分支的会话 |
Ctrl+W |
扩大到当前仓库所有 worktree 的会话 |
Ctrl+A |
扩大到本机所有项目的会话 |
→ / ← |
展开或折叠 fork 出来的会话组 |
如果经常同时做几件事,最好给会话命名:
1 | |
这比靠时间和摘要找会话稳定得多。
Claude Code 里怎么 fork
在会话内分叉:
1 | |
从命令行分叉最近会话:
1 | |
从命令行恢复某个会话并分叉:
1 | |
fork 后,原会话不变,新会话继承 fork 之前的上下文。/branch 会打印新分支会话 ID 和原会话 ID;想回到原会话,可以用 /resume 选择器,也可以用 /resume <original-name> 或 session ID 恢复。会话选择器会把 fork 出来的分支归在根会话下面,用 → 展开即可。
/rewind 和 fork 也要分清。/rewind 是在同一条会话里回到旧 checkpoint,可选择恢复代码、恢复对话或压缩上下文;fork 是复制一条新会话,原会话继续保留。要撤销走错的几步,用 /rewind;要试一条新路线,用 fork。
OpenCode 里的对应关系
OpenCode 也有类似概念,只是命令名不同。CLI 层明确支持:
1 | |
因此,OC / OmO 里的 fork 仍然是会话级能力,不是 OmO 的 Atlas、Prometheus、Sisyphus 这些 agent 角色本身。OmO 负责把任务拆给不同 agent / 模型;fork 负责在运行这些编排之前,把当前上下文复制成一条可试错的新线。
多个会话并存时怎么互相切换
fork 出新分支后,原会话和分支会话同时存活,下一个问题就是切换。Claude Code 没有"会话标签页"这类原生 UI,切换落在两类机制上:多终端进程,或后台会话面板。
多终端窗口或 tmux pane 是最朴素的方式。每条 claude 命令启动独立进程,原会话留在终端 A,新分支跑在终端 B,物理隔离最直观。配合 tmux split-pane 或 iTerm2 的 split,可以在一屏里同时盯两条线。为此命名会话很关键:claude -n "feature-A"、claude -n "fix-X",回头 claude --resume "feature-A" 按名字找回,比靠 sessionId 或时间戳稳定。
claude --bg 配 claude agents 面板 为"同时跑 N 条独立任务"提供了官方的并行会话模型:
1 | |
claude attach 不是"切换会话",而是把一条后台会话拉进当前终端接管。退出 attach 后会话仍在后台运行,可以从另一个终端再次 attach。claude respawn <id> 能重启停止的会话并保留对话历史,适合在 Claude Code 更新后让旧任务接着跑新二进制。从 v2.1.144 起,后台会话也会出现在 /resume 选择器里,带 bg 标记。
第三种是通过文件系统隐式协同。Claude Code 的 skill 系统支持 live change detection:fork 出去的分支会话修改了 ~/.claude/skills/<name>/SKILL.md,原会话不需要重启就能看到新版。可以专门 fork 一条分支去调 skill 元数据,调好后回原会话立刻试触发,省掉重启上下文的成本。
会话之间共享什么、隔离什么
除了切换姿势,还要理解多个会话同时活动时各自能看见什么、动什么。Claude Code 的状态边界不是按"会话"切,而是按"目录"和"用户主目录"切:
| 资源 | 作用域 | 多会话效果 |
|---|---|---|
~/.claude/settings.json |
用户级 | 所有会话共享,任一改动立即影响其他 |
.claude/settings.json |
项目级 | 同目录所有会话共享 |
.claude/skills/、~/.claude/skills/ |
项目级 + 用户级 | 共享,含 live change detection |
| Hooks | 跟 settings 同源 | 同目录会话使用同一套 hooks |
CLAUDE.md / AGENTS.md / MEMORY.md |
文件即作用域 | 共享,会话独立读取 |
| 会话 transcript | sessionId 级 | 完全隔离,每条会话写自己的 jsonl |
| 业务代码文件 | 文件系统 | 无锁,后写覆盖先写 |
transcript 在 macOS 下落在 ~/.claude/projects/<目录路径转义>/<sessionId>.jsonl,目录路径里的 / 会被替换成 -。claude project purge [path] 可以清掉某个项目的全部本地状态(transcripts、task lists、debug logs、prompt history 一起删),操作前最好先加 --dry-run 看影响范围。
最容易踩的坑是同目录两会话并发改同一份业务代码。Claude Code 没有文件锁,两条 agent 同时编辑会出现后写覆盖先写、丢失彼此修改的情况。规避方式有两条:
- 任务隔离:让两条会话天然不碰同一批文件——一条调 skill 元数据、一条改业务代码,或一条改前端、一条改后端。
- 物理隔离:用
claude -w <name>启动 worktree 模式,把第二条会话放到<repo>/.claude/worktrees/<name>独立工作树里,git 层面就分开了,配--tmux还能直接给 worktree 起 tmux pane。
hooks 同样按目录共享:同目录两条会话会触发同一套 hooks。这通常没问题,但如果 hook 本身有 side effect(写文件、推消息、起进程),并发触发可能产生重复或竞态,需要 hook 脚本自己保持幂等。
什么时候该 fork
适合 fork 的场景很明确:
| 场景 | 是否 fork | 原因 |
|---|---|---|
| 只是继续昨天没做完的任务 | 不需要,--continue / --resume 即可 |
仍然沿着同一条路线走 |
| 要试两个互斥方案 | 需要 | A/B 两条路线不要污染彼此上下文 |
准备让 /team、/ralph、ulw 长时间自主执行 |
建议 | 保留人工分析过的干净母会话 |
| 两个终端要基于同一背景并行工作 | 需要 | 避免两边消息写进同一 transcript |
| 只是想撤回刚才几步 | 不需要,用 /rewind |
rewind 是回滚,fork 是分支 |
| 上下文太长,只想压缩 | 不需要,用 /compact 或 checkpoint summarize |
fork 不负责压缩上下文 |
一个安全的日常工作流是:先用普通会话读代码、澄清需求、形成计划;计划稳定后给会话命名;真正让 OMC / OmO 跑长流程前 fork 一条执行分支。这样即使自动化执行走偏,也只是执行分支变脏,原来的理解和计划仍然可以复用。
什么时候摘要后开新会话,什么时候留在本窗口
fork 解决的是“从同一段历史复制一条分支”。但还有另一种更常见的痛点:一个上下文执行到一半,模型和人都开始厌倦不断重复填充背景。每次都要提醒“刚才已经说过”“这个约束别忘了”“不是这个文件”,说明窗口里已经混入了太多噪声。
这时有四种选择:
| 操作 | 本质 | 适合场景 |
|---|---|---|
| 留在当前会话 | 继续使用完整上下文 | 当前推理链还没断,最近几轮细节仍然关键 |
/compact 或 checkpoint summarize |
在同一会话里压缩历史 | 任务没换,但早期铺垫太长,需要释放窗口 |
| 摘要后开新会话 | 把稳定结论写成 handoff,再重启上下文 | 任务阶段已经切换,旧会话的噪声比信息更重 |
| fork | 复制当前会话,走另一条路线 | 要试方案 B,同时保留方案 A 的完整历史 |
判断标准不是“上下文多长”,而是旧上下文还在不在帮忙。如果它主要提供的是稳定事实,摘要就够了;如果它还包含大量刚刚发生、尚未凝固的推理链,最好留在本窗口。
适合“摘要后开新会话”的信号有几个。
第一,阶段已经切换。例如探索阶段已经结束,接下来只需要执行计划;排查阶段已经定位根因,接下来只需要改代码;文章审阅已经形成结构判断,接下来只需要落笔改写。这类场景里,旧会话的大量搜索过程、试错路径、被否掉的假设都可以丢弃,只保留结论。
第二,上下文开始反复污染模型判断。如果模型总是回到已经废弃的方案、反复引用旧文件、把早期假设当成当前事实,说明旧上下文不再是资产,而是干扰源。继续留在本窗口,相当于让模型带着一堆过期缓存工作。
第三,人类已经能用一页纸讲清楚当前状态。一个好的交接摘要应该能覆盖:目标、已确认事实、当前决策、后续动作、禁止重复的坑、关键文件、验证方式。如果这些信息可以浓缩成 30 到 80 行,开新会话通常更划算。
第四,后续任务更像“执行”而不是“继续思考”。执行类任务依赖的是清晰约束和检查清单,不依赖长篇对话历史。此时新会话反而更稳定,因为模型不会被早期讨论里的分叉观点拖走。
适合“留在本上下文窗口”的场景也很明确。
第一,当前结论还没稳定。如果几个假设仍在竞争,或者刚刚得到的线索还没有合并成判断,过早摘要会丢掉推理的细枝末节。摘要擅长保存结论,不擅长保存犹豫、反证、语气和尚未收束的判断。
第二,最近几轮对话本身就是关键证据。例如用户刚做了偏好选择、刚否掉一个方案、刚给出一句非常具体的约束。这些信息虽然可以摘要,但压缩后容易丢失强度。留在原窗口更安全。
第三,工作现场还没收干净。如果终端里有正在跑的进程,文件改了一半,测试失败原因还没读完,或者工具输出刚返回但还没被消化,此时开新会话会制造新的断点。先把现场收束成“已知事实 + 下一步”,再考虑摘要。
第四,需要完整 transcript 来追责或复盘。安全审计、线上故障、复杂技术选型这类任务里,为什么排除了某个方案和最后选择了什么同样重要。此时 fork 或留在当前会话比新会话更合适。
可以用一个简单的判断表:
| 问题 | 如果答案是“是” | 更适合 |
|---|---|---|
| 旧会话里多数内容已经变成稳定结论了吗? | 是 | 摘要后开新会话 |
| 后续只需要按清单执行吗? | 是 | 摘要后开新会话 |
| 模型开始被旧假设带偏了吗? | 是 | 摘要后开新会话 |
| 最近几轮还有未凝固的判断吗? | 是 | 留在本窗口 |
| 当前文件或终端状态还没收束吗? | 是 | 留在本窗口 |
| 要同时试两个互斥方案吗? | 是 | fork |
| 只是窗口太长但任务没换吗? | 是 | /compact 或 summarize |
一个可复用的 handoff 摘要模板如下:
1 | |
真正有用的摘要不是”聊天记录压缩版”,而是”下一位执行者的任务卡”。如果摘要里还充满”可能””大概””前面提到过”,说明上下文还没沉淀好,不适合换会话;如果摘要已经能独立指导下一步行动,就可以放心开新会话。
Rewind、Fork、Branch、Bg:四个易混词的最终澄清
到这里 Claude Code 关于”非线性会话操作”的几个能力都出现过了,集中放一张表能避免后续混淆:
| 操作 | 命令 | 本质 | 典型用法 |
|---|---|---|---|
| 回滚 | /rewind(别名 /checkpoint、/undo) |
同一条会话内回到旧 checkpoint,可选恢复代码 | 撤回刚才几步走错的操作 |
| 分叉 | /branch <name> 或 /fork(同义) |
复制当前会话,新会话从分叉点继承上下文,原会话保留 | 试 A/B 两条方案、给长流程留退路 |
| CLI 分叉 | claude --resume <id> --fork-session |
/branch 的 CLI 等价物,在新终端进程里启动分叉 |
不打断原会话的前提下另开终端起分支 |
| 新空会话 | /clear(别名 /new、/reset) |
清空上下文开新会话,旧会话进 /resume |
阶段切换、彻底换任务 |
| 后台会话 | claude --bg “...” |
起一条 detached 会话,不占当前终端 | 并行 N 条独立任务,事后 attach 看结果 |
| 接管后台 | claude attach <id> |
把后台会话拉进当前终端 | 查看进度、人工接管 |
/fork 还有一个隐藏行为需要留意:环境变量 CLAUDE_CODE_FORK_SUBAGENT 被设置时,它的含义会变——不再是 /branch 的别名,而是 spawn 一个 forked subagent(子会话,不是新主会话)。该变量启用时要用 /branch 而不是 /fork,否则行为不一致。
从 Vibe Coding 到 Agent Harness:OmO 的工程化视角
单独看 OmO,很容易把它理解成“OpenCode 的多模型插件”。这个说法没有错,但不完整。旧文《告别 Vibe Coding:用 OmO 构建可靠的 AI 工程系统》真正讨论的是另一件事:为什么 AI 编程不能长期停留在“一个人盯着一个聊天窗口修修补补”的工作方式里。
OmO 的基本判断是,Vibe Coding 的问题不只是模型偶尔写错代码,而是工作方式本身无法支撑复杂工程。原型阶段可以靠即时反馈和人工接管快速推进;一旦进入存量系统、跨模块变更、长周期任务、可回归交付,单窗口对话会暴露出上下文接力、角色分工、验收标准、历史知识和自动纠偏五类结构性缺口。
OmO 解决的是工程交付,而不是对话回答
传统 AI 编程工具常被按“会不会答”“代码片段写得像不像”来评价。OmO 的评价口径更接近工程交付:输入一段 Markdown 任务描述,输出一组能通过验证的工程变更。这个差异很关键。对话回答只需要在当前窗口里自洽;工程交付必须能经得起 build、test、LSP diagnostics、性能指标、业务断言和后续维护。
旧文里把这个转变概括成一条流水线:任务描述进入系统后,先经过意图判断,再组织并行搜索、资料研究、执行器和验证器,最后回到可运行、可验证的工程输出。这个视角比“多 Agent 更热闹”更接近 OmO 的设计初衷。
1 | |
这里的重点不是“让 AI 更像人”,而是让 AI 进入一个更像工程系统的运行环境。人类不再持续盯盘、补 prompt、临场兜底,而是在任务开始前定义目标、边界、验收标准和不可破坏的约束。
Vibe Coding 的五个工程困境
旧文把 Vibe Coding 的局限拆成五个问题,这部分是当前横评文章原先缺失最多的内容。
第一是上下文窗口与 SDLC 的时间尺度不匹配。LLM 的工作单元是 session,软件开发的工作单元是 project。长周期项目无法假设所有背景都能一直留在一个上下文窗口里。Anthropic 在 long-running agents 相关工程文章里也提到过类似问题:长任务必须在离散 session 之间接力,每个新 session 如果没有可靠状态,就像换班工程师完全不知道上一班发生了什么。
Thoughtworks 对 brownfield 场景的实验也指向同一个结论:即使有 MCP 和工具接入,跨会话的持久上下文仍然脆弱。没有 harness、checkpoint、计划文件和状态记录,人类就会被迫充当“上下文接力员”。这不是人类监督的优势,而是系统设计把状态管理成本转嫁给人。
第二是单窗口无法支撑多角色协作。传统 Vibe Coding 是一个通用模型在一个会话里串行扮演所有角色:架构师、实现者、测试者、审查者、文档员。多 Agent 的价值不只是并发,而是关注点分离。Microsoft Azure 的多 Agent 架构指南也强调过责任拆分、模块化和可扩展性。OmO 通过 Sisyphus、Prometheus、Atlas、Oracle、Librarian、Explore、Hephaestus 等角色,把“一个全能模型”拆成“有边界的团队”。
第三是缺少工程契约。Vibe Coding 里的 done 往往是“看起来差不多”。工程交付里的 done 必须能被机器和人共同判断:测试是否通过,LSP 是否还有错误,关键接口是否兼容,性能是否退化,业务规则是否保持。没有 acceptance criteria,Agent 就只能猜目标;猜对了是运气,猜错了就是返工。
第四是缺少历史架构知识。代码能说明“现在是什么样”,但很难说明“为什么这样设计”“哪些地方不能动”“未来应该往哪走”。这在 legacy 项目里尤其危险。Val Town 曾把 vibe coding 与技术债的积累联系起来,SonarSource 的行业调查也指出,AI 生成代码可能看起来正确但并不可靠。根因通常不是模型不会写语法,而是它不知道历史约束、隐性业务规则和架构演进路径。
第五是缺少自动纠偏。Vibe Coding 的纠偏机制主要靠人盯着输出。复杂系统不能只靠单点人工监督保证正确性,它需要多重校验、异常检测、约束传播和 peer review。OmO 把这件事做成系统机制:Intent Gate 防止入口意图错位,Metis 捕获计划缺口,Momus 审查计划可执行性,执行阶段再用 LSP/build/test 做硬验证。

认知边界:为什么“人盯着”不是可靠解法
旧文里有一个值得保留的论证:人类并不能无限纠正复杂度的混乱。George Miller 关于工作记忆容量的经典结论常被概括为 7±2 个信息块;Cowan 后续研究进一步把复杂推理场景下的有效容量压到约 4±1。这个数字不需要被当成机械上限,但它提醒了一件事:人类也有上下文窗口,也会被局部注意力和任务切换成本限制。
所以,LLM 的上下文窗口限制不是“AI 独有缺陷”,而是复杂系统的共性。人类和模型都无法在单次认知活动里处理无限复杂度。工程化解法不是让某个单体变得无限聪明,而是把任务拆小,把工作集控制在可理解范围内,让每个局部变更都有快速反馈和清晰边界。
这也是 OmO 的 harness 视角:把“无限复杂度的项目”拆成“有限复杂度的任务流”。任务被切成可验证的单元,错误被限制在局部,反馈周期由 build/test/LSP 缩短到分钟级甚至秒级,治理成本才不会随着项目规模失控。
Harness:状态、验证与失败恢复
OmO 自称 agent harness,核心不是包装几个漂亮命令,而是把长任务运行所需的状态管理和恢复机制补齐。旧文提到的 TODO 跟踪、后台任务 ID、boulder 状态、plan 文件、notes、conventions/gotchas,本质上都是同一类东西:让任务状态离开单个聊天窗口,变成可恢复、可审计、可继续消费的工程资产。
这和 fork、resume、compact 解决的问题不同。fork 保护的是会话分支;harness 管的是任务执行状态。fork 能让一条上下文复制出方案 B,但不能告诉下一个执行者 wave 2 做到了哪里、哪些测试失败、哪些约束不能破坏。harness 需要把这些信息写入计划、任务列表、状态文件或项目规则中。
1 | |
旧文中对 boulder 的解释也应该保留:它是 OmO 用来跨会话持久化任务状态的文件,记录当前进度、已完成步骤和待续工作。它的价值不在于格式本身,而在于把“任务做到哪了”从人脑和聊天窗口里搬出来。
Intent Gate 与 Checkpoint 不是一回事
旧文有一节专门澄清 Intent Gate 与 Checkpoint 的区别,这一点在横评里也很重要。Intent Gate 位于任务入口,解决“要做什么”的问题;Checkpoint 位于阶段结束,解决“是否做对”的问题。
| 概念 | 位置 | 作用 | 时机 |
|---|---|---|---|
| Intent Gate | 任务入口 | 判断真实意图、任务类型和路由策略 | Phase 0,执行前 |
| Checkpoint | 执行过程 | 强制验证阶段成果,不通过就不算完成 | 每个阶段结束后 |
例如“优化登录流程”这句话,字面上可以是重构、性能优化、体验改造、安全修复,也可能是新增登录方式。Intent Gate 的职责是先判断意图并选择路径。如果这一步做错,后面再努力也可能是在错误目标上优化。
Checkpoint 处理的是另一类问题。代码写完后,必须通过 LSP diagnostics(lsp_diagnostics)、build、test、性能指标或业务断言确认结果。LSP diagnostics 是语言服务器提供的即时静态反馈,包括语法错误、类型错误、未定义引用、参数不匹配、未使用变量和潜在空指针等。它比完整 build 更轻,比肉眼检查更稳定,适合作为 Agent 写完代码后的第一层机器校验。
OmO 的多层 gate 体系可以被理解为一条质量链:Sisyphus 的 Intent Gate 做入口分类,Metis 在计划前做 gap analysis,Prometheus 生成计划,Momus 审查计划,执行 Agent 在阶段末通过 verification checkpoint。这样设计的目的,是避免“自己计划、自己执行、自己宣布成功”的闭环幻觉。
1 | |
SDD、Rules 与历史知识沉淀
旧文把 OmO 放进了更大的 SDD/SDLC 语境里,这一点也需要补回。Spec-Driven Development 的核心不是“多写点文档”,而是把意图放到比代码更高的一层,让 spec 成为人和 AI 共同遵守的事实来源。Martin Fowler 对 SDD 的讨论强调 documentation first;GitHub 的相关工程文章则把维护软件描述为演进 specification,代码只是最后一公里。OmO 宣言里的 “minimum intervention, not constant supervision” 也落在这个语境里:人的职责不是持续监督,而是让系统具备可持续推进的规则、状态和验收机制。
这和 OmO 的 AGENTS.md、项目 rules、plan、acceptance criteria 是同一条线:把过去、现在、未来都写进系统。
- 过去:架构决策、历史约束、不能破坏的兼容性、曾经踩过的坑。
- 现在:当前需求边界、验收标准、测试范围、性能要求。
- 未来:演进方向、禁止引入的反模式、后续任务需要继承的 conventions/gotchas。
Rules 体系的价值在这里显现出来。Vibe Coding 里的很多规则是工程师脑子里的隐性经验,比如“不要改 public/”“不要删 .deploy_git/”“这个模块不能绕过缓存”“这个接口要保持兼容”。如果这些规则没有显式进入 AGENTS.md、CLAUDE.md、项目 rules 或任务验收标准,Agent 就只能从当前代码表面结构猜测。
真正稳定的 Agentic Engineering 需要两层纠偏同时存在:一层是专门角色之间的互相监督,例如 Sisyphus 验收、Momus 审查计划、Oracle 只读架构分析;另一层是项目级 Rules,把团队经验固化成所有 Agent 都必须遵守的硬约束。模型输出变稳定,不是因为模型突然变得完美,而是因为系统让错误更难发生、更容易被发现。
三种协作模式:Hephaestus、Sisyphus、Prometheus + Atlas
旧文对 OmO 的三种使用姿态有更细的区分,横评文章原先只保留了 Prometheus/Atlas 这条线,遗漏了 Hephaestus 和 Sisyphus 的边界。
Hephaestus 适合 hard problem、复杂架构推理和长链路 debug。它的使用方式不是 micromanagement,不是告诉它“先做 A、再做 B、然后做 C”,而是给出 north star 级别的目标和边界。例如“让这个模块支持并发访问,同时保持向后兼容”。这类 Agent 的价值在于深度推理和自主探索;给太细的 recipe,反而是在用人的局部推理限制模型的搜索空间。
Sisyphus 是多数复杂任务的默认入口,更像编排器或项目经理。它负责理解意图、并行委托 Explore、Librarian、Oracle 等后台任务,聚合代码证据、文档证据和架构建议,再把工作路由到合适的 category。旧文里提到的 ulw / ultrawork,就是激活这种并行证据收集、分类路由和强制验证的入口。

Prometheus + Atlas 适合高风险、跨天、需要审计和断点续传的长任务。Prometheus 先访谈、识别范围、消除歧义,把隐含需求和关键约束固化到 .sisyphus/plans/*.md;Atlas 再按 wave 执行、验证、记录 learnings。这里的关键不是“多一个计划 Agent”,而是把规划与执行分离,把计划审查、执行调度和结果验证拆开。

这三种模式对应三种任务形态:Hephaestus 处理深水区,Sisyphus 处理大多数复杂任务,Prometheus + Atlas 管长周期高风险任务。它们不是强弱关系,而是不同的治理粒度。
| 模式 | 适用场景 | 输入方式 | 成功条件 |
|---|---|---|---|
| Hephaestus | hard problem、架构、深度 debug | north star + 边界,不给 recipe | 自主探索后给出可验证结果 |
| Sisyphus | 多数复杂任务 | ulw / ultrawork |
并行证据充分,任务全部闭环 |
| Prometheus + Atlas | 跨天、高风险、可审计任务 | @plan + /start-work |
计划固化、按 wave 执行、可断点恢复 |
ATDD:把 done 写成机器能判断的条件
旧文最后给出的实践建议是 ATDD。这里的 ATDD 不是一定要先写完整自动化测试套件,而是用 acceptance criteria 驱动计划、实现和完成判断。越 autonomous 的 Agent,越需要清晰边界和可量化验收标准。
坏输入通常长这样:“把登录流程优化一下”“重构这个模块”“把体验做好”。这类描述会把大量判断空间留给模型。一个好输入则会把行为、边界、指标和回归范围写清楚:保留现有 SSO 行为;新增邮箱登录;登录关键路径 E2E 通过;LSP 0 error;关键 API p95 小于 200ms;旧用户会话不失效;异常登录仍然记录审计日志。

旧文的四步实践可以压缩成一条规则:先写验收标准,再让 Prometheus 把模糊点问清,随后准备可执行的判断依据,最后才选择 Hephaestus、Sisyphus 或 Prometheus + Atlas 推进实现。
| 步骤 | 目的 | 典型产物 |
|---|---|---|
| 写 AC | 明确 done 的机器可判断条件 | 测试、性能阈值、业务断言、回归范围 |
| 让 Prometheus 澄清 | 消除歧义和隐含需求 | plan、风险、边界、非目标 |
| 准备判断依据 | 让验证不依赖肉眼 | LSP/build/test/perf/日志/业务检查 |
| 选择执行模式 | 匹配任务复杂度和风险 | Hephaestus / Sisyphus / Prometheus+Atlas |
这部分也能反过来校准 OMC 与 OmO 的差异。OMC 更像把 Claude Code 的执行能力封装成自动流水线,适合“已经知道要做什么,交给它 plan→exec→verify”。OmO 更像把任务治理体系搭起来,适合“目标复杂、模型多、风险高,需要把意图、计划、执行、验证、状态和规则分层治理”。如果任务只是单文件修复,OmO 的 harness 是负担;如果任务需要跨天推进、跨模型协作、保留上下文和验收证据,harness 才是它真正的价值。
核心功能特性对比
Agent 系统
OMC 提供 19 个专业 Agent,按层级变体覆盖架构、研究、设计、测试、数据科学等领域。通过智能模型路由自动选择 Haiku(轻量任务)或 Opus(复杂推理),官方声称节省 30-50% token 开销(此数据来自项目方自身,未经第三方验证)。
OmO 采用命名 Agent 体系,每个 Agent 绑定特定模型并调优:
| Agent | 绑定模型 | 职责 |
|---|---|---|
| Sisyphus | Claude Opus 4-7 / Kimi K2.6 / GLM-5.1 | 主编排器 |
| Hephaestus | GPT-5.5 | 自主深度执行 |
| Prometheus | Claude Opus 4-7 / Kimi K2.6 | 战略规划 |
| Oracle | — | 架构与调试(只读) |
| Atlas | — | 执行指挥与验证 |
编辑系统
OMC 使用 Claude Code 原生的编辑工具。
OmO 独创了 Hashline 哈希锚定编辑 系统——每行代码标记内容哈希(LINE#ID),Agent 编辑时引用这些标记,如果文件已变更则哈希不匹配、编辑被拒绝。官方基准测试显示 Grok Code Fast 1 模型的编辑成功率从 6.7% 提升到 68.3%(此数据来自 OmO 项目 README,属单一来源)。
团队模式
OMC Team 管道(v4.1.7 起为标准编排模式):
- 分阶段执行:plan → prd → exec → verify → fix(循环)
- 支持 Claude/Codex/Gemini CLI 混合工作节点
- 需要启用实验性 Agent Teams 功能
OmO Team 模式(v4.0,可选启用):
- 最多 8 个并行成员
- tmux 实时可视化(focus + grid 窗口布局)
- 内置团队技能:
hyperplan(5 个敌对 Agent 审查计划)、security-research(3 个漏洞猎手 + 2 个 PoC 工程师)
Skill 系统
两者都支持可复用的 skill 机制:
| 维度 | OMC | OmO |
|---|---|---|
| 存储路径 | .omc/skills/ (项目) / ~/.omc/skills/ (用户) |
.opencode/skills/*/SKILL.md |
| 触发方式 | 关键词自动注入 + 斜杠命令 | 关键词自动注入 |
| 内置 skill | git-master, frontend-ui-ux 等 | playwright, git-master, frontend-ui-ux |
| 特色 | /skillify 自动提取模式 |
skill 自带 MCP 服务器(按需启停) |
| 管理命令 | /skill list|add|remove|edit|search |
类似 |
OmO 的 skill-embedded MCP 是一个差异化设计:每个 skill 可以携带自己的 MCP 服务器,按需启动、任务结束后关闭,避免常驻 MCP 占用上下文窗口。
内置 MCP 与工具链
OMC 在 v4.4.0 移除了 Codex/Gemini MCP 服务器,转向 tmux CLI 工作节点方案。内置 LSP 工具(rename、goto definition、find references、diagnostics)和 AST-Grep。
OmO 默认启用三个 MCP 服务器:
| MCP | 功能 |
|---|---|
| Exa | Web 搜索 |
| Context7 | 官方文档查询 |
| Grep.app | GitHub 代码搜索 |
同样内置 LSP 和 AST-Grep 工具。
执行模式汇总
| 模式 | OMC | OmO |
|---|---|---|
| 团队编排 | /team(分阶段管道) |
Team Mode(并行成员) |
| 持久执行 | /ralph(verify/fix 循环) |
Ralph Loop / ulw-loop |
| 最大并行 | /ultrawork |
ultrawork / ulw |
| 自主执行 | /autopilot |
内置于 ultrawork |
| 三模型合成 | /ccg(Claude+Codex+Gemini) |
通过分类路由实现 |
| 需求澄清 | /deep-interview(苏格拉底式提问) |
Prometheus 访谈模式 |
| 计划共识 | /ralplan |
hyperplan(5 Agent 对抗审查) |
安装与配置教程
OMC 安装
前置条件
- Claude Code CLI(需要 Claude Max/Pro 订阅或 Anthropic API key)
- tmux(Team 模式和限流检测必需)
- 可选:Gemini CLI、Codex CLI(多模型编排)
方法一:插件市场(推荐)
在 Claude Code session 中依次执行:
1 | |
方法二:npm 全局安装
1 | |
初始化设置
1 | |
启用 Team 模式
编辑 ~/.claude/settings.json:
1 | |
可选:多模型支持
1 | |
三个 Pro 计划(Claude + Gemini + ChatGPT)月费约 $60。
OmO 安装
前置条件
- OpenCode(OmO 是 OpenCode 的插件)
- tmux(Team Mode 和交互式终端必需)
- 推荐订阅:ChatGPT ($20) + Kimi Code ($19) + GLM Coding ($10)
安装方式
将以下提示粘贴到 LLM Agent 中(Claude Code、AmpCode、Cursor 均可):
1 | |
手动安装参考 docs/guide/installation.md。
诊断检查
1 | |
验证插件注册、配置、模型和环境是否正常。
配置文件位置
| 作用域 | 路径 |
|---|---|
| 用户级 | ~/.config/opencode/oh-my-openagent.jsonc |
| 项目级 | .opencode/oh-my-openagent.jsonc |
支持 JSONC 格式(允许注释和尾逗号)。
分类路由配置示例
1 | |
实际使用场景对比
场景一:修复 TypeScript 类型错误
OMC 方式:
1 | |
Team 管道自动执行:分析错误 → 制定修复计划 → 并行执行 → 验证通过。
OmO 方式:
1 | |
Sisyphus 按错误复杂度分类,简单类型错误路由到 GPT-5.4 Mini(快速),复杂架构级类型问题路由到 GPT-5.5 xhigh(深度推理)。
场景二:全栈功能开发
OMC 方式:
1 | |
执行流程:deep-interview 暴露隐藏假设 → team plan 阶段生成执行计划 → executor Agent 并行实现 → verifier 自动验证。
OmO 方式:
1 | |
场景三:代码审查与安全审计
OMC 方式:
1 | |
OmO 方式:
1 | |
原生 vs 插件:四者全维度对比
理解了两大基座的原生能力和两大插件的增强能力后,将它们放在同一张对比表中有助于看清各层级的定位:
| 维度 | Claude Code 原生 | OMC(插件层) | OpenCode 原生 | OmO(插件层) |
|---|---|---|---|---|
| 并行模式 | Subagents(单向回报)+ Agent Teams(同伴通信) | Team Pipeline(plan→prd→exec→verify→fix) | Primary Agents(Tab 切换)+ Subagents(@mention 调用) | Atlas 指挥 + 分类路由 + Team Mode |
| 通信拓扑 | Subagents: 星型;Agent Teams: 全网格 | Session 内星型 + CLI 进程间 tmux 隔离 | 父子星型(Subagents 之间不通信) | 全网格(同伴直接通信) |
| 多模型 | 仅 Claude 模型族(Haiku/Sonnet/Opus) | 通过 tmux 启动 Codex/Gemini CLI(进程级) | 每个 Agent 独立绑定模型(Build/Plan/自定义) | API 级分类路由(visual→Gemini, deep→GPT, quick→Mini) |
| 角色隔离 | Agent Teams: Lead 可写代码;Subagents: 无强制隔离 | 软隔离(Agent 类型区分:architect/executor/verifier) | Plan=只读/Build=全工具,按 permission 控制 | 硬隔离(Prometheus 只写计划,Atlas 不写代码,Junior 不委托) |
| 任务协调 | Agent Teams: 共享任务列表 + 文件锁防竞态 | 管道式(分阶段串行 + 阶段内并行) | 无原生共享任务列表 | boulder.json 持久化 + 累积学习 |
| 会话恢复 | Subagents: ✅;Agent Teams: ❌ | ✅(插件自主管理) | ✅(Agent 切换保留历史) | ✅(OmO 独立管理状态) |
| 上下文管理 | 每个 Teammate 独立上下文,不继承 Lead 历史 | Session 内压缩 + 技能注入 | 每个 Agent 独立上下文 | 累积学习(conventions/gotchas 跨任务传递) |
| 安装成本 | 开箱即用(启用 flag 即可) | 插件安装 + 可选 Gemini/Codex CLI | 开箱即用 | 插件安装 + 多模型 API key 配置 |
| Token 开销 | 低(Subagents)/ 高(Agent Teams,每个 Teammate 独立计费) | 中(19 个 Agent 的 prompt 负载 + 管道各阶段) | 低(子代理结果摘要注入) | 中高(三层架构各层均有 prompt 开销) |
| 成熟度 | Subagents: 稳定;Agent Teams: 实验性 | 成熟(v4.13.7,33.7k stars) | 稳定 | 成熟(v4.1.1,57.6k stars) |
这张表揭示了一个关键事实:插件层不是在"替代"原生能力,而是在"填补"原生能力的空白。OMC 填补的是 Claude Code 在多模型访问和工作流自动化上的空白;OmO 填补的是 OpenCode 在同伴协作、任务协调和累积学习上的空白。
工作模式选择:最佳实践决策树
面对四种模式,如何根据任务特征选择最合适的方式?以下是基于任务类型的决策指南。

决策框架
1 | |
按任务类型推荐
代码审查与安全审计
| 场景 | 推荐模式 | 理由 |
|---|---|---|
| 快速 CR,关注一个维度 | Claude Code Subagents / OpenCode @general | 开销最低,秒级响应 |
| 多维度并行审查(安全+性能+测试各一人) | Claude Code Agent Teams 原生 | 同伴可互相挑战发现交叉问题,3 个 Teammate 刚好 |
| 需要 Gemini+GPT+Claude 三模型交叉审查 | OmO Team Mode + security-research skill | 多模型互补 + 内置攻击性安全审计流水线 |
| Claude 生态内需要自动化审查流水线 | OMC /team 管道 | 分阶段 verify/fix 循环,适合 CI/CD 集成 |
全栈功能开发
| 场景 | 推荐模式 | 理由 |
|---|---|---|
| 单一模块新功能,前后端不拆分 | Claude Code / OpenCode Build 单 Agent | 上下文连续,避免协调开销 |
| 前后端分离,各模块独立 | Claude Code Agent Teams(前端+后端+测试各一个 Teammate) | 各 Teammate 拥有独立上下文,避免上下文污染 |
| 前端用 Gemini 做 UI、后端用 GPT 做逻辑 | OmO | 分类路由自动分配,Atlas 统一指挥 |
| 需要完整 PRD→计划→执行→验证流水线 | OMC /deep-interview + /team | 需求澄清 + 分阶段执行的完整闭环 |
Bug 调试
| 场景 | 推荐模式 | 理由 |
|---|---|---|
| 单一明确 bug | 单 Agent 会话 | 最快,零协调开销 |
| 根因不明,多个假说 | Claude Code Agent Teams(竞争假设模式) | 各自验证不同根因,互相挑战理论,避免锚定偏差 |
| 需要跨模块追踪调用链 | OpenCode Explore Agent(只读) | 快速搜索代码库,不修改文件 |
| 复杂 bug 需要持久化修复循环 | OMC /ralph 或 OmO Ralph Loop | 自动 verify/fix 循环直到问题解决 |
架构设计与技术调研
| 场景 | 推荐模式 | 理由 |
|---|---|---|
| 快速调研一个库/方案 | Claude Code Subagents / OpenCode Scout | 聚焦研究,只读安全 |
| 多角度架构评审 | OMC /ccg(Claude+Codex+Gemini 三模型合成) | 三个模型从不同视角审查架构 |
| 需要 5 个敌对 Agent 挑战计划 | OmO hyperplan | 5 个 Agent 从不同角度攻击计划,计划更健壮 |
| 需要输出详细设计文档 | OpenCode Plan Agent | 只读分析、只写 Markdown,不会误改代码 |
成本效益速查
| 模式 | Token 开销 | 最适合任务规模 | 学习曲线 |
|---|---|---|---|
| 单 Agent 会话 | ★☆☆☆☆ | 单文件/单模块 | 无 |
| Subagents(Claude Code) | ★★☆☆☆ | 3-5 个独立子任务 | 低 |
| Agent Teams(Claude Code 原生) | ★★★★☆ | 3-5 个需要协作的子任务 | 中 |
| OpenCode Primary+Subagents | ★★☆☆☆ | 分析+编码分离 | 低 |
| OMC | ★★★☆☆ | 中大型功能开发,需要流水线 | 中 |
| OmO | ★★★★☆ | 跨模型协作,大型项目 | 中高 |
关键原则:Token 开销最低的方案不一定是总成本最低的方案。一个任务被错误分配到简单模式导致返工,其总成本可能远超直接用更强大的编排模式一次做对。选择模式时优先考虑"是否能一次性高质量完成",其次考虑"每步的 token 消耗"。
选型决策指南
选 OMC 的场景
- 已经深度使用 Claude Code:OMC 是 Claude Code 的原生插件,零迁移成本
- Claude 模型满足需求:如果项目主要需要的能力(代码生成、推理、测试)Claude 都能覆盖,OMC 的深度增强比多模型切换更高效
- 追求简单上手:插件市场一键安装,魔法关键词即用,不需要配置多个 API key
- MIT 许可证需求:OMC 采用 MIT 许可,对商业使用更友好
- 需要 Telegram/Discord/Slack 通知:OMC 内置完整的通知系统
- 需要完整工作流自动化:需求澄清→计划→执行→验证→修复的闭环流水线
选 OmO 的场景
- 需要真正的多模型编排:前端用 Gemini、逻辑用 GPT、文档用 Claude——按任务特征自动路由
- 已经使用 OpenCode:OmO 是 OpenCode 的原生增强
- 对编辑可靠性要求高:Hashline 哈希锚定编辑显著减少了编辑失败率
- 需要跨模型后备链:当首选模型不可用时,自动切换到下一个可用模型
- 需要累积学习:每个子任务的经验教训自动传递给后续任务,避免重复犯错
- 更大的社区生态:57.6k stars,66+ 衍生项目,多语言 README
什么时候直接用原生就够了
- 简单并行任务:Claude Code Subagents 或 OpenCode @general 就够,无需插件
- 多视角审查但模型单一:Claude Code Agent Teams 原生覆盖,OMC 反而增加复杂度
- 快速探索代码库:OpenCode Explore/Scout Agent 开箱即用
- 分析与编码分离:OpenCode Plan + Build 切换即可,不需要 OmO 的规划-调度-执行三层分离
- 预算敏感:原生模式无额外插件层的 prompt 开销
四者的共同局限
- 复杂性税:多 Agent 编排引入额外的 token 消耗和延迟。简单任务直接使用基座工具可能更高效
- 平台绑定:OMC 绑定 Claude Code,OmO 绑定 OpenCode。选择任一都意味着一定程度的平台锁定
- 性能数据缺乏第三方验证:OMC 的 “30-50% token 节省”、OmO 的 “6.7%→68.3% 编辑成功率”、Claude Code Agent Teams 的 token 成本数据,多为项目方自我宣称
- tmux 依赖:四种方案的高级功能(OMC 多模型、OmO Team Mode、Claude Code Agent Teams 的 split-pane)都依赖 tmux,在纯 IDE 集成场景下存在摩擦
- 实验性风险:Claude Code Agent Teams 目前仍是实验性功能,OpenCode 的 Agent Teams 尚在 dev 分支,API 和行为可能变化
结论
回顾全文,我们实际上面对的是一个四层金字塔而不是简单的二选一:
1 | |
从下往上是"复杂度递增、能力递增"。关键在于在合适的层级解决合适的问题:
- 90% 的日常开发在基础层和原生并行层就足够——Claude Code 的 Subagents 或 OpenCode 的
@general处理并行搜索/测试/审查,OpenCode 的 Plan Agent 做只读分析 - 需要同伴协作的复杂任务上升到原生协作层——Claude Code Agent Teams 的多视角审查、竞争假设调试,3-5 个 Teammate 互相挑战
- 需要工作流自动化或跨模型能力才上插件编排层——OMC 的 Team Pipeline + Ralph Loop 实现无人值守的 verify/fix 循环,OmO 的分类路由让前端用 Gemini、逻辑用 GPT、文档用 Claude
OMC 和 OmO 不是要取代基座原生能力,而是在原生能力够不到的地方提供增强。最佳实践不是"选 OMC 还是选 OmO",而是"这个任务在金字塔的哪一层解决最合适"——能用原生 Subagents 的不用 Agent Teams,能用原生 Agent Teams 的不上插件层,只在真正需要工作流自动化或跨模型调度时才启用 OMC 或 OmO。
对于已经在 Claude Code 生态中的团队,OMC 是阻力最小的增强路径;对于追求模型多样性和自动路由的团队,OmO 提供了更完整的多模型编排方案。但无论选择哪个生态,理解基座原生能力的边界,是做出正确技术决策的前提。
参考来源
- oh-my-claudecode GitHub — v4.13.7, 33.7k stars, 2026-05-09
- oh-my-openagent GitHub — v4.1.1, 57.6k stars, 2026-05-13
- Claude Code Agent Teams 官方文档 — Anthropic, 2026-02
- Claude Code Sessions 官方文档 — 会话恢复、命名与分叉
- Claude Code Checkpointing 官方文档 — rewind、checkpoint 与 fork 的边界
- OpenCode Agents 官方文档 — SST, 2026
- OpenCode CLI 官方文档 —
--continue、--session、--fork - Building Agent Teams in OpenCode — Uenyioha, 2026-02, PR #12730-#12732
- Anthropic Engineering: Effective Harnesses for Long-Running Agents — long-running agents 与 harness 机制
- Thoughtworks:AI 辅助 brownfield 开发实验 — 跨会话上下文与工程纪律相关观察
- Val Town: Vibe Coding is Tech Debt — Vibe Coding 与技术债讨论
- Martin Fowler: Understanding Spec-Driven Development — SDD 与 documentation first
- GitHub Blog: Spec-driven development with AI — spec 作为更高层开发语言
- OmO Orchestration Guide
- OmO Configuration Reference
- OmO Ultrawork Manifesto
- Claude Code Memory 官方文档 — CLAUDE.md、rules、auto memory 三层架构
- Claude Code Interactive Mode 官方文档 — 单字符前缀、权限模式、输入方式
- Claude Code Keybindings 官方文档 — 快捷键配置与默认映射
- Claude Code Commands 官方文档 — 完整斜杠命令列表