《高可用恢复思路》笔记
遇到线上问题,经常陷入一个误区:一定要找到问题的根因(root cause)。但实际上对线上应用而言,最重要的是恢复可用性,所以在开发设计环境除了完成功能性需求以外,还需要加入非功能性设计的需求:
- 限流保护。抵挡来自突发流量冲垮整个集群。
- 降级保护,对调用的服务接口保持警惕,其各种因素导致不可用,可以对齐降级,从而确保核心功能可用。
- 削峰填谷(traffic shaping),不因突发数据来袭,造成任务消费陡增,造成调用系统的连串抖动。
这些基本的系统保护,是应对未来的各种突发不确定事件的高可用思考。
以上描述的是问题的应对机制设计,问题的发现机制,也需要结构化地考虑,体系化地建设:
- 发现机制,是我们的眼睛,也是基础。
- 监控主指标,需要找对业务的主要指标,常见的主指标一般是:RT(响应时间)、总量、成功量、失败量、成功率。
- 主指标有异常,还要有细分维度(即结果还可以内部 group by aggregation)。
- 快速恢复
- 根据监控快速寻找问题发生的方向和位置。
- 找对恢复的人、恢复的预案。
- 倾向于选择成本低的恢复手段。---- 并不是所有的恢复都用大招(熔断、限流),大招一定有损且有风险
- 最后执行恢复
- 一般我们都会对恢复预案做演练,避免恢复预案失效。或者因执行了预案产生更大的问题。
- 执行恢复动作要谨慎。一切线上操作都为变更,都有风险。
经验告诉我们:线上问题70%来自变更,找到变更快速回滚是第一优先级,其余30%的问题需要做好预案及防护,快速对应不同的线上突然事件。

All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2023-02-13
推荐系统相关
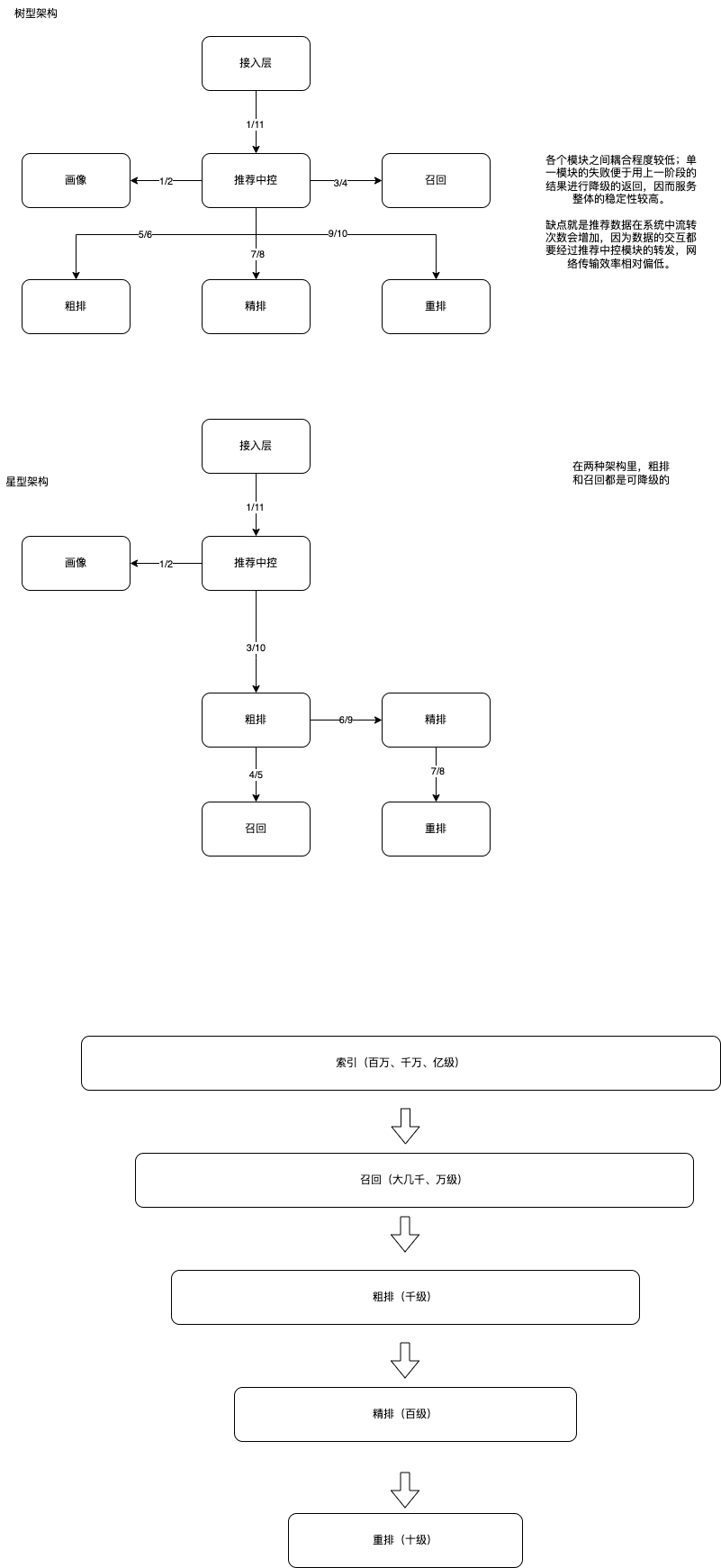
新闻的推荐系统是为了给信息流的用户推荐资讯 feed。接口返回的信息不一定会被外显曝光。 在瀑布流式的外显曝光场景下,重排能够减少用户的疲劳度。 这就涉及到推荐系统的设计,流量要经过什么样的链路呢? 接入层、推荐中控、画像、召回、粗排、精排、重排。这些系统会形成星型架构和树形架构。 不同的架构之间有一个典型的优缺点需要取舍:链路长度会影响网络传输的最终效率,也会影响推荐系统的性能。 feeds推荐引擎典型架构.drawio

2019-09-05
《应用架构之道》笔记
架构师的职责 化繁为简。架构师是职责就是把复杂的问题简单化,使得其他人能够更好地在架构里工作。 架构师要努力训练自己的思维,用它去理解复杂的系统,通过合理的分解和抽象,做出合理的设计。 软件架构 软件架构是一个系统的草图。软件架构描述的对象是直接构成系统的抽象组件。各个组件的链接则明确和相对细致地描述组件之间的通信。 软件架构为软件系统提供了结构、行为和属性的高级抽象。,由构件的描述、构件的相互作用、指导构件集成的模式以及这些模式的约束组成。软件架构不仅显示了软件需求和软件结构之间的对应关系,而且指定了整个软件系统的组织和拓扑结构,提供了一些设计决策的基本原理。 软件架构的核心价值应该只围绕一个核心命题:控制复杂性。 软件架构分类 业务架构:由业务架构师负责,也可以称为业务领域专家、行业专家。业务架构属于顶层设计,其对业务的定义和划分会影响组织结构和技术架构。 应用架构:由应用架构师负责,他需要根据业务场景的需要,设计应用的层次结构,制定应用规范、定义接口和数据交互协议等。并尽量将应用的复杂度控制在一个可以接受的水平,从而在快速的支撑业务发展的同时,在保证系统的可用性和可维...
2022-03-18
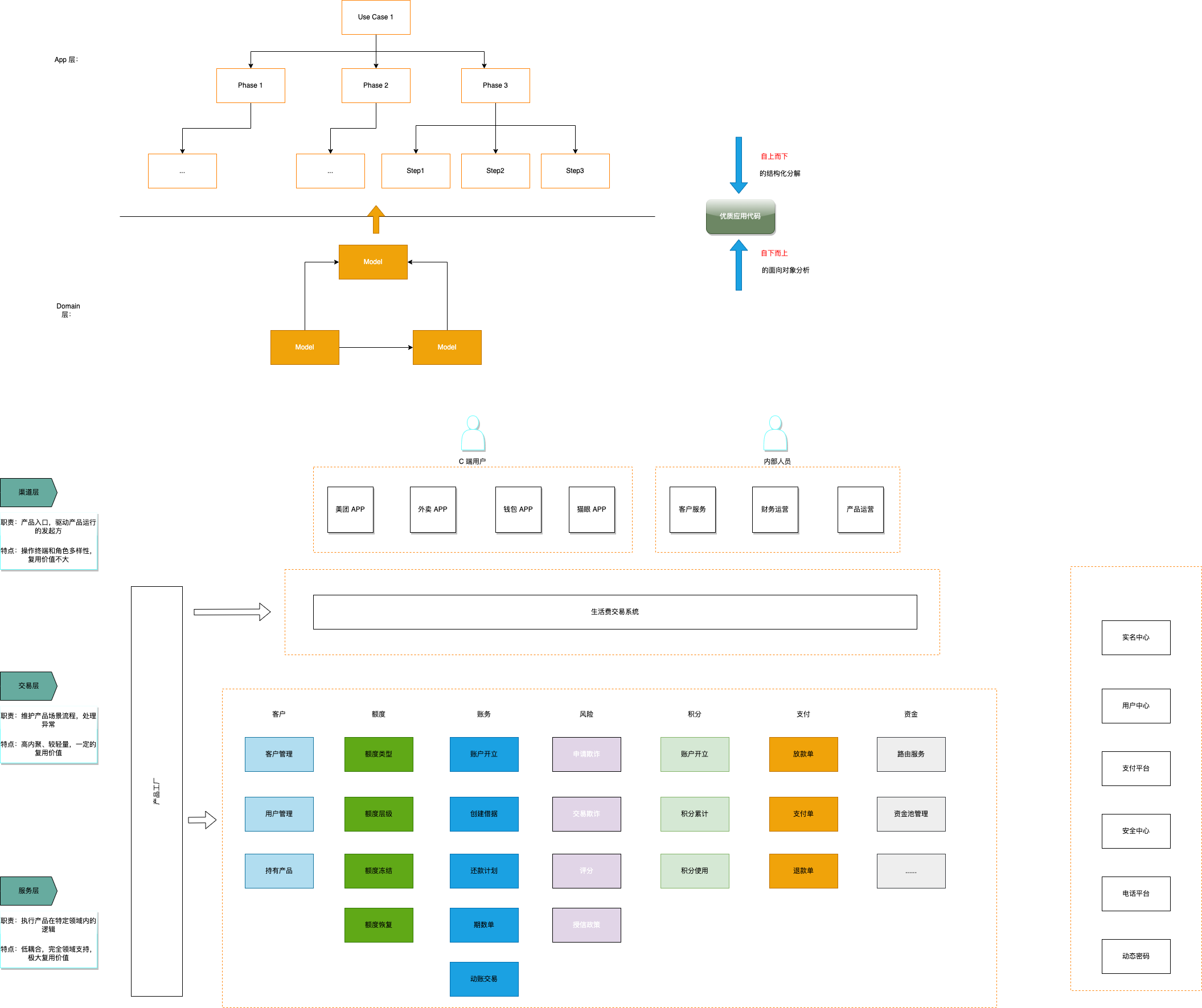
如何写业务代码
业务研发面对的问题 稳定的业务模式 不稳定的需求 业务对交付的渴望 假设 命名规范(《clean code》) 面向对象设计(SOLID原则、贫血/充血模型、设计模式) 系统要拆分 流程控制系统与领域系统.drawio 每一个用例(解决的一个问题)都由访问逻辑和执行逻辑组成。访问逻辑负责用例执行的顺序与分支,并调用执行逻辑完成完整业务逻辑。 访问逻辑由单独的交易系统负责。执行逻辑由个子系统负责。 工程要拆分 三层架构 + 洋葱架构 代码要拆分 业务代码:描述核心业务逻辑的代码,核心是保持业务的流程及业务状态的一致性 领域对象与领域服务,不得对外部有任何依赖(工具类除外) 最核心的几个抽象: 校验:参数有效性校验、参数的业务属性校验。在进入正常业务逻辑代码前,完成所有的校验工作。 异常:业务异常:所有不符合业务逻辑而产生的异常。 系统异常:因为程序本身or依赖产生的异常。 所有的异常第一位runningtime异常。 数据: 业务数据:保存领域对象状态的数据。 非业务数据:过程数据。业务的核心流程中,只对业务数据的持久化负责。 参数:任何时候,任何方法的参数都需要...

2022-03-11
面向好的架构编程
前言 本文是《架构随笔》系列的第五篇,也是它的收官之作。 架构的定义 架构是一个界定不清的东西,我们很难讲清楚哪些东西是架构,哪些东西不是架构。但软件行业里其实人人都在搞架构,软件设计就是架构本身。 架构这个词出现得很早,有些人认为是 NASA(也可能是NATO) 发明的。最早的架构定义就是描述软件的结构而已,但现在已经没有多少人谈论他们定义的“软件架构”了。工程师很难以克制描述复杂结构的原始冲动,但描述复杂结构的普世标准并不存在。大家常见的各种定义,翻来覆去地重新讲着“软件架构是软件结构的顶层设计或者抽象设计”之类的话。即使是这种软件架构的定义,也并不为所有人都接受。汗牛充栋的架构书籍里有各种各样的观点,有的进一步把软件架构视作一堆组件和交互的设计,有的则把软件架构视作架构师主观意图的体现。把自己当作架构师的人们,着迷于把软件里的“不变与抽象的部分”和“易变与具体的部分”分离出来,把前者当作架构。架构师们是如此地热衷于做这样一件事,以至于有些人认为架构设计好了就解决了基本问题,设计不好通常是因为架构不好。于是很多人开始刻舟求剑:从某某颗粒度开始的设计应该叫概要设计,从某某颗粒度...

2021-03-01
HATP 问题
问题定义 AP 的出现 在互联网浪潮出现之前,企业的数据量普遍不大。通常一个单机的数据库就可以保存核心的业务数据。那时候的存储并不需要复杂的架构,所有的线上请求(OLTP, Online Transactional Processing) 和后台分析 (OLAP, Online Analytical Processing) 都跑在同一个数据库实例上。后来业务越来越复杂,数据量越来越大,产生了一个显著问题:单机数据库支持线上的 TP 请求已经非常吃力,没办法再跑比较重的 AP 分析型任务,在这样的大背景下,于是AP开始从TP系统分离,某种程度上,AP是TP的一个分支。 这等于是在存储层做 CQRS 架构设计-另一种方案是在应用层也设计读写分离的架构。 AP 的玩法 在这样的背景下,以 Hadoop 为代表的大数据技术开始蓬勃发展,它用许多相对廉价的 x86 机器构建了一个数据分析平台,用并行的能力破解大数据集的计算问题。 AP 系统的典型技术栈演进: 阶段 代表技术 特点 第一代 Hadoop MapReduce + Hive 批处理,延迟高(分钟到小时级) 第二...
2022-01-19
Gergely Orosz 文章翻译-软件架构被高估,简明设计被低估
原文链接:《Software Architecture is Overrated, Clear and Simple Design is Underrated》





