

Harness Engineering 完整指南:从 Prompt Engineering 到实践落地的三级跃迁
2020 年我们学会了跟模型说话(Prompt Engineering),2025 年我们学会了给模型喂信息(Context Engineering),2026 年我们学会了给模型搭脚手架(Harness Engineering)。这三个 Engineering 不是并列关系,而是严格的超集关系:PE ⊂ CE ⊂ HE。本文从"为什么上一个不够"的视角,系统梳理这条演进路径上的每一次范式跃迁,并给出从 Anthropic 实证到工程落地的完整方案。 一个类比秒懂三级跃迁 在讲技术之前,先用一个所有人都能理解的类比。 想象你要指挥一个完全失忆的天才厨师做一桌满汉全席: Prompt Engineering 就是学会怎么跟厨师下达指令。你发现说"做道好吃的"不行,得说"用中火煎三分钟,翻面后加酱油 15 毫升"。这是措辞的艺术。 Context Engineering 就是学会怎么给厨师备料。光会下指令不够——厨师面前得摆好食材、调料、菜谱、食客的过敏信息。你要设计一个动态备料系统,让厨师在需要的时候拿到需要的东西...

OpenSpec 实战指南:从工作流到落地
为什么需要 OpenSpec 在 AI 编程时代,真正的难点往往不是“AI 会不会写代码”,而是“AI 能不能稳定写出你真正想要的代码”。问题往往不在模型能力,而在于需求、边界、约束和验收标准没有被稳定地表达出来。当意图没有沉淀为可复用的工程事实,AI 就只能在模糊上下文里“猜”。 OpenSpec 解决的正是这个问题。它的核心思想可以概括成一句话:先对齐规范,再生成代码(align before code)。与其把 AI 当成一个只看提示词的即时执行器,不如把它放进一套可追溯、可迭代、可沉淀的规范工作流里。 OpenSpec 既不是重量级流程平台,也不是传统瀑布式文档系统。从实践上看,它更像一套轻量的仓库内协议: 用 specs/ 保存系统当前已经成立的事实; 用 changes/ 保存本次准备引入的未来变化; 用 proposal、spec、design、tasks 把“为什么改、改成什么、怎么实现”拆开表达; 用 sync 和 archive 把一次变更逐步沉淀为下一次变更的上下文。 它的设计哲学,基本可以概括为四点: Fluid not rigid:规范是活文档,不...

子 Agent 的本质:上下文隔离与专门化
"子 Agent"这个词在多 Agent 系统的讨论中频繁出现,却鲜有人把它说清楚。它是一个能力弱化的 Agent,类似一个 Agent 化的工具?还是一个拥有更小上下文的原始 Agent,像从主 Agent fork 出来的进程?还是一个在指挥体系里听从领导 Agent、但拥有更强资源和能力的 Agent? 这三种直觉都不完全准确。本文从 Anthropic、LangChain、Claude Code 等权威来源出发,厘清子 Agent 的真实本质,并探讨一个更深层的问题:"子 Agent"究竟是能力描述,还是关系描述? 三种直觉,三种误解 在深入定义之前,先把三种常见直觉逐一检验。 误解一:子 Agent 是能力弱化的 Agent 这种直觉来自于"子"字的字面含义——子集、子系统、子进程,往往意味着更小、更弱。但 LangChain 官方文档明确指出: “An interesting aspect of this approach is that sub-agents may have the exact sa...

git worktree 术语起源解析
引言 在使用 Git 的过程中,你可能会遇到 git worktree 这个命令。这个名字看起来有些特别——为什么叫 “worktree” 而不是 “workspace” 或其他更常见的词?这背后其实有一段有趣的技术历史。 核心答案 worktree 是 working tree(工作树)的缩写,来源于 Git 内部的核心概念。 这不是一个凭空创造的新词,而是直接引用了 Git 自诞生以来就存在的基础术语。 Git 的三大核心区域 要理解 worktree 的命名,首先需要了解 Git 的三大核心区域: 区域 英文名称 别名 作用 仓库 Repository - 存储所有版本历史和元数据(.git 目录) 工作树 Working Tree Working Directory 用户实际编辑文件的目录 暂存区 Index Staging Area 准备提交的文件快照 Working Tree 的含义 Working Tree(工作树)指的是检出(checkout)到文件系统中的文件集合。它是你能够直接看到、编辑的目录和文件。 12345my-project...
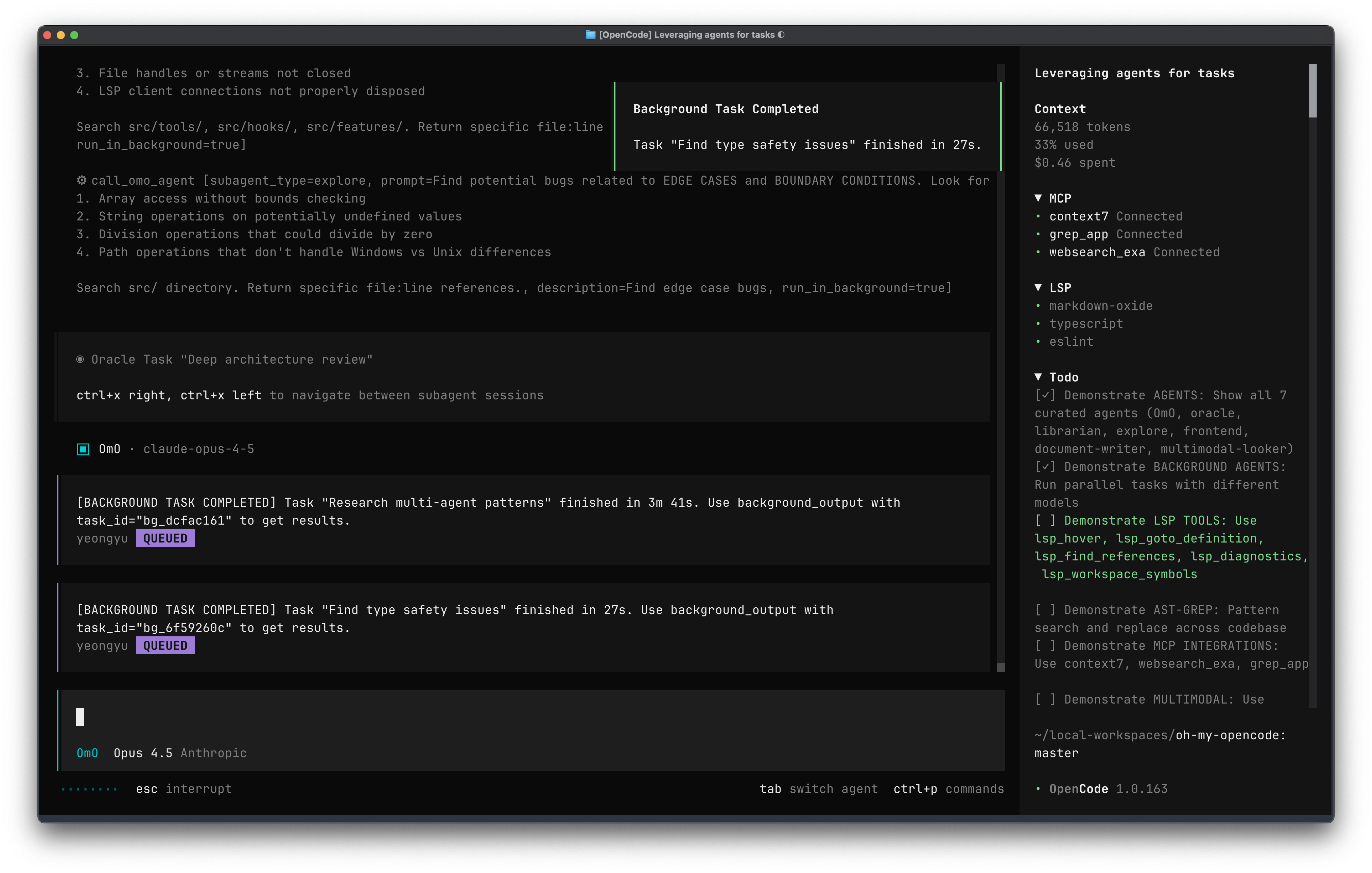
告别 Vibe Coding:用 OmO 构建可靠的 AI 工程系统
引言:AI 编程的范式跃迁 过去一年,AI 编程工具从对话式代码生成器进化为能够自主执行复杂任务的智能代理。但真正的挑战不在于让 AI 写出代码,而在于如何让 AI 持续、可靠地完成工程任务。 Oh My OpenCode(简称 OmO)正是为了解决这一问题而生。它不是另一个聊天框,而是一套将 AI 从"对话工具"升级为"自动化工程系统"的编排框架。 OmO 的核心定位:工程化交付而非对话回答 从"会不会答"到"能不能交付" 传统 AI 编程工具的评判标准是"回答质量",而 OmO 的核心目标是**“工程交付”**。 OmO 的工作流程遵循"输入 Markdown 描述,输出可运行代码"的心智模型: 12341. 输入任务 → 2. 判断意图 → 3. 组织执行 → 4. 工程输出 (任务描述、 (Intent Gate (并行搜索、 (回到 build/ repo 上下文、 分清提问/修复/ 资料、执行...

智能体记忆全景综述:从短时长时之分到向量库回归文件系统(2022-2026)
22 年以前,“LLM 应用"基本等同于"调一次 ChatComplete”。从 22 年底 ChatGPT 出来到 26 年这三年里,行业发现真正决定智能体上限的不是模型本身,而是模型周围那一圈用来承载历史、外部知识与可更新偏好的记忆系统。这篇综述沿着一条主线展开:以"信息来源"为轴的四层记忆世界观,把过去三年的代表性工作放进这四层里,并且回答一个 26 年才浮出水面的反向问题——为什么大家又在把向量数据库塞回到一个 markdown 仓库或一份 SQLite 单文件里。 一、把整片版图压成三句话 如果把过去三年关于智能体记忆的所有论文、产品和工程实践压成三句话,大致是这样: 第一,Agent 的记忆按"信息源"切是一个稳定的四层结构:训练数据(L1)、对话内数据(L2)、会话间数据(L3)、外部世界但与本会话无关的数据(L4)。每一层的写入主体不同,分别是训练管线、当前交互、Agent 自己、世界本身。围绕"是不是要再切出第五层"在 25-26 年有一些讨论,本文的判断是:Titans / ...

在智能体优先的世界中利用 Codex
原文作者:Ryan Lopopolo,OpenAI 技术人员。本文记录了 OpenAI 内部一个工程团队历时五个月、以"零人工编码"方式构建并交付真实软件产品的完整经验。 在过去五个月里,我们的团队一直在进行一项实验:构建并交付一款软件产品的内部 beta 版,其中没有一行代码是人工编写的。 该产品有内部日常活跃用户和外部 Alpha 测试者。它经历了交付、部署、故障和修复的整个过程。与众不同的是,每一行代码 — 从应用逻辑、测试、CI 配置、文档、可观察性到内部工具 — 全都是由 Codex 编写的。据估计,我们只用了手工编写代码所需的大约 1/10 的时间就完成了这项工作。 人类掌舵。智能体执行。 我们有意选择这一限制,以便构建必要的内容,从而将工程速度提升数个数量级。我们用了几周的时间来交付最终达到一百万行代码的项目。为此,我们需要了解,当软件工程团队的主要工作不再是编写代码,而是设计环境、明确意图和构建反馈回路,从而使 Codex 智能体能够可靠地工作时,会发生哪些变化。 这篇文章要说的是,在我们与智能体团队一起从零开始打造一款全新产品的过程中,所...

macOS CLI 工具 HTTPS 抓包指南(以 OpenCode 为例)
为什么需要 CLI 抓包? 在开发调试 AI 编程助手、API 客户端等命令行工具时,经常需要查看其 HTTPS 请求内容。浏览器有开发者工具,但 CLI 工具的流量对开发者是"不可见"的。本文介绍如何使用 mitmproxy 在 macOS 上实现 CLI 工具的 HTTPS 抓包。 工具选择 在 macOS 上对命令行工具进行 HTTPS 抓包,免费方案首选 mitmproxy。它提供三种使用形态: mitmproxy:终端交互式 UI,适合实时过滤和查看 mitmweb:浏览器 Web UI,JSON 自动格式化,适合内容分析 mitmdump:纯命令行,适合录制流量到文件或脚本处理 三者共享同一套证书和配置,按需选用即可。 安装 1brew install mitmproxy 第一步:生成 CA 证书 首次运行会自动生成证书文件: 12mitmproxy# 看到界面后直接 q 退出 证书默认生成在 ~/.mitmproxy/: 1234~/.mitmproxy/├── mitmproxy-ca-cert.pem # 需要信任这个├── mitm...

JSONC - 带注释的 JSON
JSONC 是什么? JSONC(JSON with Comments)是 JSON 的一个扩展格式,允许在 JSON 数据中添加注释。这个规范由 jsonc.org 定义,旨在形式化一种在实践中广泛使用但缺乏正式标准的格式。 起源与背景 JSONC 格式最初由微软非正式地引入,用于 VS Code 的配置文件,包括: settings.json - 编辑器设置 launch.json - 调试配置 tasks.json - 任务配置 伴随着这种非正式格式,微软发布了一个公开可用的解析器 jsonc-parser。JSONC 规范的目标是将 JSONC 格式形式化,定义 jsonc-parser 在默认配置下认为有效的内容。 语法规则 JSONC 遵循与 JSON 相同的语法规则,并额外支持 JavaScript 风格的注释。 单行注释 单行注释以 // 开始,延伸到行尾: 12345{ // 这是单行注释 "name": "John Doe", "age": 30} 多行注释 多行注释以 ...

AI 项目配置文件全景图:md 文件的作用与边界
AI 编程工具的普及带来了一个新问题:项目里到处都是 .md 文件。AGENTS.md、CLAUDE.md、rules/、openspec/……它们各自解决什么问题?边界在哪里?什么时候该用哪一个? 这篇文章的核心洞察是:这些配置文件可以用"核心问题"和"时态属性"两个维度来区分——前者决定它们解决什么层面的问题,后者决定它们适合承载什么类型的信息。 理解这两个维度,就能在配置文件的迷宫中找到方向。 一、背景:为什么需要这么多配置文件? 传统软件项目只需要一个 README.md——它是给人读的。但在 AI 编程时代,项目需要同时面向两类读者:人类和 AI Agent。 人类需要的是高层次的概览(“这个项目是做什么的?”),而 AI Agent 需要的是结构化的、可执行的上下文(“代码在哪里?怎么跑起来?有哪些约束?”)。这两类需求差异巨大,单一文件难以同时满足。 于是,项目配置文件开始分化。每一类配置文件都针对特定的问题域,服务于特定的 AI 工具或工作流。理解它们,就是理解 AI 编程工具的协作边界。 二、目录结构:一个典型 AI 项目...




