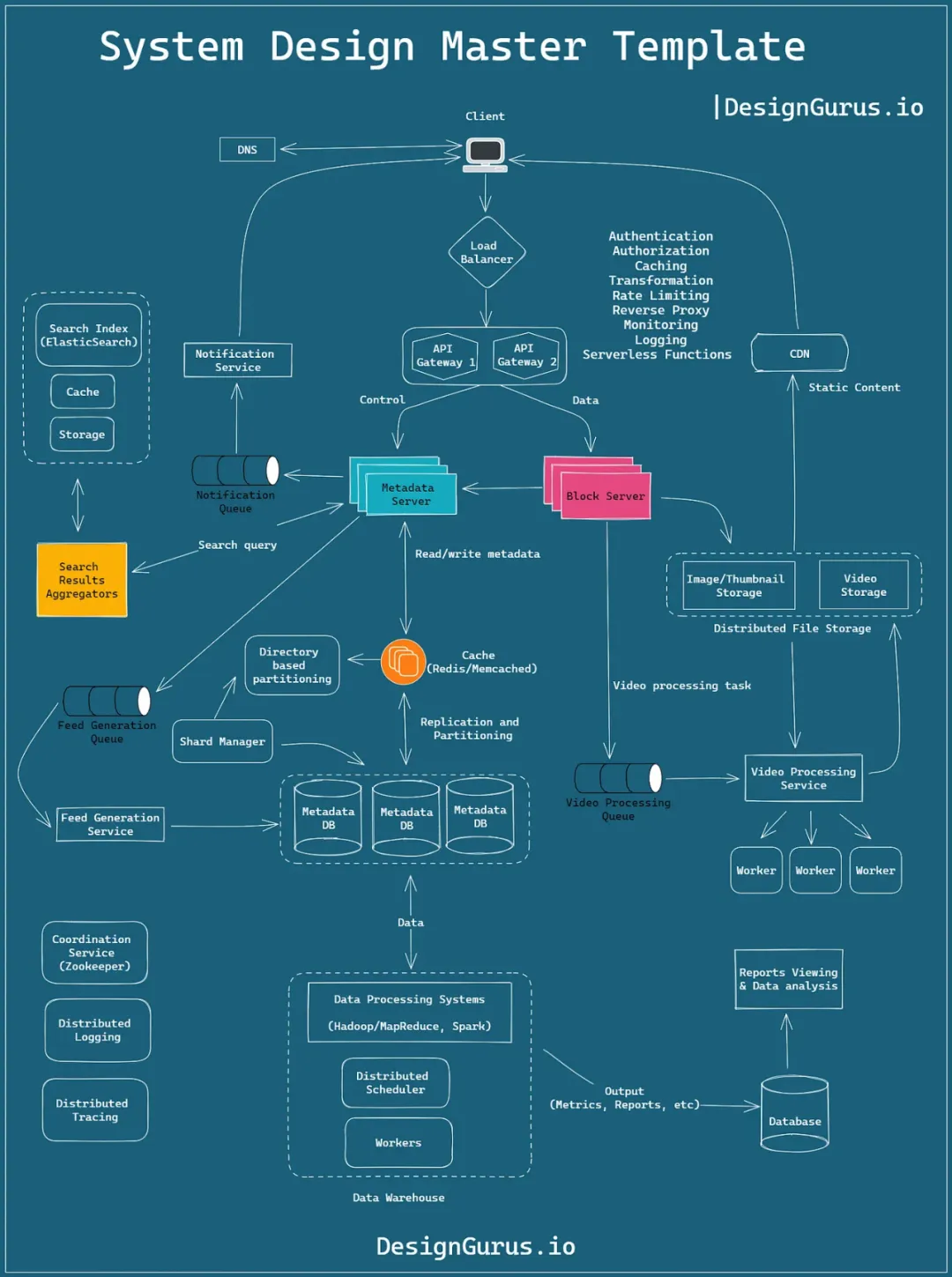
题面
把一个真实落地的项目折叠成一道架构题:
有一个 git 仓库,里面散落着 N 个 SKILL.md 文件(带 YAML frontmatter + 同目录的资源文件)。要做一个内部「Skill Hub」服务:
- 浏览、搜索、分类、查看详情
- 在线预览 markdown 与文件树
- 一键下载某个 skill 的 zip 包
- 源仓库 push 时 Hub 要自动跟上
- 部署形态是单 Node 进程(容器平台只给一个端口)
怎么设计?
约束是分批给的。每听完一版方案,就追加一个新约束逼着方案迭代。下面 14 层按这个节奏走。每层先写最朴素的版本,再写暴露出来的问题,最后写改进,配最小可读的代码片段。
代码片段、字段名、目录名都是从一个真实落地的项目里抽出来的,业务和组织信息已经全部抹掉。
第 1 层:最朴素的版本
最直接的实现:
1
2
3
4
5
| app.get("/api/skills", async () => {
await exec("git clone --depth 1 $REPO /tmp/work");
const skills = scan("/tmp/work");
return skills;
});
|
每次请求都 clone 一次仓库、扫描一次目录。
这一版的问题:
- 一次 clone 几百 MB,请求要等几十秒。
- 并发请求会互相踩
/tmp/work。
- 几百次请求把对端 git 服务打爆。
这一层的修正是把 git 当源,用本地 mirror 加内存索引做运行时存储。
第 2 层:本地 mirror + 启动同步
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class GitMirror {
async ensureClone() {
if (!exists(this.dir)) {
await git("clone", "--mirror", this.repoUrl, this.dir);
}
}
async fetch() {
await git("-C", this.dir, "fetch", "origin");
}
async headSha() {
return git("-C", this.dir, "rev-parse", `refs/heads/${this.branch}`);
}
}
|
启动流程:
- 本地无 mirror 就 clone
fetch originheadSha 未变就跳过重建索引headSha 变了就 checkout 加重新扫描 SKILL.md,再写 skills.json
第一个状态对象由此出现:
1
2
3
4
5
6
7
8
9
| interface SyncState {
headSha: string;
previousHeadSha?: string;
status: "idle" | "syncing" | "failed";
lastSyncStartedAt?: string;
lastSyncFinishedAt?: string;
lastError?: string;
indexedSkillCount: number;
}
|
新的问题有两个:启动后只同步一次,后续仓库变了 Hub 不知道;业务期望源仓 push 完几秒内 Hub 就能搜到新 skill。
第 3 层:四种同步触发器并存
约束加一条:源仓刚 push,业务希望 30 秒内 Hub 上能搜到新 skill。
有三个可选触发器,三个都各有短板:
| 触发器 |
优点 |
缺点 |
| 启动同步 |
冷启动一致 |
仅一次 |
| Webhook |
实时 |
平台可能漏发、网络抖动 |
| 周期 poll |
兜底 |
有延迟 |
| 手动同步 |
应急 |
需要鉴权 |
四个触发器都要保留,而不是只靠 webhook。webhook 平台漏发、配错地址、网络抖动都会让索引悄悄落后几小时甚至几天,而周期 poll 是这类故障唯一能兜住的兜底。
四个触发器一起涌进来必然出问题:webhook 短时间连续触发(一次 push 一个 commit)、周期 poll 撞上 webhook、手动同步撞上启动同步。
第二个核心组件由此出现:串行同步队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class SyncQueue {
private running = false;
private pending: SyncTask | null = null;
enqueue(task: SyncTask) {
if (!this.pending || higherPriority(task, this.pending)) {
this.pending = task;
}
this.drain();
}
private async drain() {
if (this.running) return;
while (this.pending) {
this.running = true;
const task = this.pending;
this.pending = null;
try { await runSync(task); }
finally { this.running = false; }
}
}
}
|
三条不变量:
- 串行。同一时间只一个 sync 在跑。
- Debounce。2 到 5 秒窗口内的同源 enqueue 合并。
- 优先级。manual > webhook > startup > poll,pending 槽位被更高优先级替换。
第 4 层:索引存储的原子性
到这里最自然的写法是:
1
| await fs.writeFile("skills.json", JSON.stringify(skills));
|
问题在掉电窗口。服务在 JSON.stringify 之后、write 完成之前掉电,skills.json 会被截断成半张表,下一次启动直接 JSON parse 报错,服务起不来。
原子写模板:
1
2
3
4
5
6
7
8
9
10
11
| async function atomicWriteJson(target: string, data: unknown) {
const tmp = `${target}.tmp.${process.pid}.${Date.now()}`;
const fh = await fs.open(tmp, "w");
try {
await fh.writeFile(JSON.stringify(data));
await fh.sync();
} finally {
await fh.close();
}
await fs.rename(tmp, target);
}
|
顺手再加两件事。
Schema version envelope:
1
2
3
4
5
| {
"schemaVersion": 1,
"headSha": "ab12cd34",
"skills": [ ... ]
}
|
读取时校验 schemaVersion,未来格式迁移就有回退余地。低版本 server 读到高版本 index 时降级到空索引,比强解析崩溃强。
同步失败保留旧索引:
1
2
3
4
5
6
7
| try {
const fresh = await indexSkills(headSha);
await atomicWriteJson("skills.json", fresh);
} catch (e) {
syncState.lastError = String(e);
}
|
效果是新数据没写成时旧索引继续对外服务。
第 5 层:sync 与 read 的并发竞争
这一层的并发竞争很容易出问题。
考虑这个时间线:
1
2
3
4
5
6
| t0 用户 GET /api/skills/foo/file?path=README.md
t1 handler 拿到 skill.rootPath = /data/git/repo/foo
t2 sync 任务开始 checkout 到新 commit
t3 handler 走 fs.readFile(/data/git/repo/foo/README.md)
↑ 此时工作树正在被 git checkout 撕成两半
t4 返回给用户:截断 / 找不到 / 旧内容混新内容
|
zip 下载更危险。archiver 把目录树流式打包要持续几秒到十几秒,整个过程都在 checkout 风暴中。
朴素的读写锁不行。读多写少时这把锁会饿死 sync,而 zip 的流可能持续超过整个 sync 周期。
真正可用的方案是 per-commit snapshot 加原子 symlink swap。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
async ensureSnapshot(commitSha: string): Promise<string> {
const dir = path.join(this.snapshotsDir, commitSha);
if (await exists(dir)) return dir;
await git("worktree", "add", "--detach", dir, commitSha);
return dir;
}
async swapServingTo(commitSha: string) {
const target = path.join(this.snapshotsDir, commitSha);
const link = this.servingDir;
const tmpLink = `${link}.tmp`;
await fs.symlink(target, tmpLink);
await fs.rename(tmpLink, link);
}
async pruneSnapshots(keep: number) {
}
|
读路径只经过 servingDir,且 zip 构建前先 fs.realpath 把 inode 钉住:
1
2
3
| const root = await fs.realpath(skill.rootPath);
const stream = archiver("zip").directory(root, false);
|
效果:sync 期 reader 看不到撕裂状态;旧 reader 永远看完旧 snapshot;保留 N 个 snapshot 让长 zip 跨多次 sync 也安全。
第 6 层:性能(I/O 与 fork 削减)
加一条约束:同步一次几百个 skill 要扫几百个 SKILL.md、几百次 git log、几百次 fs.stat。能不能快点?
第一刀砍串行 git log:
1
2
3
4
5
6
7
8
9
|
for (const skill of skills) {
skill.lastCommit = await gitLog1(skill.relativePath);
}
const results = await Promise.allSettled(
skills.map(s => gitLog1(s.relativePath))
);
|
第二刀砍 N 次 fork:
1
2
3
4
5
6
|
async function batchLastCommits(paths: string[]): Promise<Map<string, Commit>> {
}
|
第三刀砍 metrics 实时写盘。浏览量、下载量本质是频繁的小增量,每次请求都 fs.writeFile 一次 metrics.json 等于把磁盘当寄存器用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class MetricsStore {
private dirty = new Map<string, MetricsDelta>();
private timer: NodeJS.Timeout;
bump(id: string, kind: "views" | "downloads") {
this.dirty.get(id) ?? this.dirty.set(id, { views: 0, downloads: 0 });
this.dirty.get(id)![kind]++;
if (this.dirty.size >= 10) this.flush();
}
constructor() {
this.timer = setInterval(() => this.flush(), 5000);
}
async flush() {
if (this.dirty.size === 0) return;
const snapshot = this.dirty;
this.dirty = new Map();
await atomicWriteJson("metrics.json", merge(load(), snapshot));
}
}
|
阈值取 5 秒或 10 次累积任一触发。生产观测下来这条改动减少了约 95% 的 metrics I/O。
代价:进程崩溃最多丢 5 秒 / 10 次的计数。对浏览量统计来说可以接受,而且 graceful shutdown 会强制 flush(见第 13 层)。
第 7 层:性能(HTTP 缓存)
换个战场。前端 SPA 每次切页都拉一次 /api/skills,每次都重算列表。能让浏览器和服务器都少干点活吗?
三件套。
ETag 加 Cache-Control:
1
2
3
4
5
6
7
8
9
10
11
| app.get("/api/skills/:id", async (req, reply) => {
const skill = repo.findById(req.params.id);
const etag = skill.commitSha;
if (req.headers["if-none-match"] === etag) {
return reply.code(304).send();
}
reply
.header("etag", etag)
.header("cache-control", "private, max-age=10, stale-while-revalidate=60")
.send(skill);
});
|
ETag 粒度要按接口语义分级:
/api/skills/:id 用记录的 commitSha/api/skills?q=...&page=... 用 hash(headSha + queryString)/api/home-feed 用 headSha,再加一层 memoize
接口合并。首页要展示「最近更新 / 下载热榜 / 工作流精选」三个 bucket。朴素做法是前端打三个请求。改成:
1
2
3
4
5
| app.get("/api/home-feed", async () => ({
recent: repo.sortedByLatest.slice(0, 6),
hot: repo.sortedByDownloads.slice(0, 6),
picks: repo.byCategory("workflow").slice(0, 6),
}));
|
三次 TCP 握手降到一次。响应可以 memoize per headSha,命中率几乎 100%。
客户端 SWR:
1
2
3
| import useSWR from "swr";
const { data } = useSWR("/api/skills", fetcher);
|
ETag 命中 304,SWR 拿旧数据立即渲染,网络几乎不传内容,用户感知是「秒开」。
数据结构层缓存。SkillsRepo 在加载 index 时一次性预计算好三个排序数组和两张倒排:
1
2
3
4
5
6
7
| class SkillsRepo {
sortedByLatest: Skill[];
sortedByName: Skill[];
sortedByResourceSize: Skill[];
byCategory: Map<string, Skill[]>;
byTag: Map<string, Skill[]>;
}
|
list 接口从「每请求 clone 加 sort 全表」降到 O(pageSize) slice。再加一条小优化:metrics 只附加给可见页 slice,不附加给全表。
Tree 接口 LRU。/api/skills/:id/tree 是详情页打开时立刻要的。key 用 id@commitSha,size 200:
1
| const treeCache = new LRU<string, TreeNode>({ max: 200 });
|
key 里带 commitSha 的好处是 commit 变了 key 自然失效,不需要主动 invalidation。
第 8 层:性能(带宽与序列化)
两个数字:列表接口响应是 57 KB JSON,每次请求都重新 JSON.stringify。brotli 在这个体积上能比 gzip 小多少?
编译态序列化。Fastify 支持 per-route response schema:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| app.get("/api/skills", {
schema: {
response: {
200: {
type: "object",
additionalProperties: false,
properties: {
total: { type: "integer" },
items: { type: "array", items: skillSummarySchema },
},
},
},
},
}, handler);
|
fast-json-stringify 把这个 schema 在 register 时编译成一个直接拼字符串的函数。热路径上比 JSON.stringify 快 2 到 10 倍。
additionalProperties: false 还顺手堵了字段泄漏。哪怕 handler 误返了 __internal 之类的字段,序列化层会丢掉。
压缩协议优先级:
1
2
3
4
| await app.register(fastifyCompress, {
threshold: 1024,
encodings: ["br", "gzip", "deflate"],
});
|
实测:57 KB JSON 经 brotli 约 1 KB,经 gzip 约 1.6 KB。内网应用 CPU 富余,brotli 的额外开销划算。
未来再让 nginx 用 brotli_static 配上构建期产物 *.br,CPU 直接归零,这一项放在文末「未做完的优化」里。
第 9 层:安全(Webhook)
webhook 接口最容易写成这样:
1
2
3
4
5
6
7
| app.post("/api/webhooks/git", async (req) => {
if (req.headers["x-token"] !== process.env.WEBHOOK_SECRET) {
return { ok: false };
}
syncQueue.enqueue({ reason: "webhook" });
return { ok: true };
});
|
这段代码的漏洞:
- 明文 token 比较有时序侧信道,可以逐字符爆破。
- 没限制 ref,tag push 和 branch delete 全都触发同步。
- JSON body 先 parse 再校验,攻击者发 1 GB body 把进程 OOM。
- 未配置 secret 时
process.env.WEBHOOK_SECRET === undefined,等于完全不鉴权。
- HMAC 校验和共享 token 没有兜底。
- 错误信息回写「token mismatch」帮攻击者判断。
修复版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import { timingSafeEqual, createHmac } from "crypto";
function tsEqual(a: string, b: string): boolean {
const A = Buffer.from(a);
const B = Buffer.alloc(A.length);
const ok = Buffer.byteLength(b) === A.length;
if (ok) Buffer.from(b).copy(B);
return timingSafeEqual(A, B) && ok;
}
app.register((app, _, done) => {
installRawBodyCapture(app);
app.post("/api/webhooks/git", {
bodyLimit: 1024 * 1024,
}, async (req, reply) => {
const secret = process.env.WEBHOOK_SECRET;
if (!secret) return reply.code(503).send();
const sig = req.headers["x-hub-signature-256"];
const token = req.headers["x-platform-token"];
const rawBody = (req as any).rawBody as Buffer;
const expectedHmac = "sha256=" + createHmac("sha256", secret)
.update(rawBody).digest("hex");
const hmacOk = typeof sig === "string" && tsEqual(sig, expectedHmac);
const tokenOk = typeof token === "string" && tsEqual(token, secret);
if (!hmacOk && !tokenOk) return reply.code(401).send();
const body = JSON.parse(rawBody.toString("utf8"));
if (body.ref !== `refs/heads/${branch}`) {
return { ok: true, skipped: "non-target-ref" };
}
syncQueue.enqueue({ reason: "webhook" });
return { ok: true, accepted: true };
});
done();
});
|
第 10 层:安全(其他攻击面)
webhook 只是入口之一。Hub 还有几个攻击面。
Admin endpoint:
1
2
3
4
5
|
if (process.env.ADMIN_TOKEN) {
app.post("/api/admin/sync", { }, handler);
}
|
「未配置时路由不挂」比「未配置时 401」安全。401 暴露了端点存在。
路径穿越(文件预览 + zip 下载):
1
2
3
4
5
6
7
8
|
export function resolveWithinRoot(root: string, requested: string): string {
const resolved = path.resolve(root, requested);
if (!resolved.startsWith(root + path.sep) && resolved !== root) {
throw new Error("path-escape");
}
return resolved;
}
|
外加白名单加大小上限:
1
2
3
4
5
6
| const TEXT_EXT = new Set([".md", ".ts", ".js", ".json", ".yaml", ".yml", ".sh", ".py", ".txt"]);
const MAX_FILE_BYTES = 256 * 1024;
if (!TEXT_EXT.has(ext)) return reply.code(415).send();
const st = await fs.stat(full);
if (st.size > MAX_FILE_BYTES) return reply.code(413).send();
|
Markdown XSS。SKILL.md 是用户内容,直接渲染会引入 <script>、javascript: URL、内联事件。React 端接 rehype-sanitize:
1
2
3
4
5
6
7
| <ReactMarkdown
remarkPlugins={[remarkGfm]}
rehypePlugins={[rehypeSanitize]}
components={{ a: ({href, children}) => (
<a href={href} target="_blank" rel="noopener noreferrer">{children}</a>
)}}
>{md}</ReactMarkdown>
|
外链强制 target=_blank rel="noopener noreferrer",防 tab-nabbing。
凭证脱敏。git URL 经常是 https://oauth2:<token>@host/repo.git 形式。日志、错误信息、/api/sync-state 响应都要剥掉 token:
1
2
3
| export function redactRepoUrl(url: string): string {
return url.replace(/\/\/[^@/]+@/, "//[redacted]@");
}
|
请求日志里 ?token=xxx&secret=yyy 这种 query 参数也要替换成 redacted。
第 11 层:限流与反压
内网服务也会被爬虫、误调度、循环依赖打爆。两层保险。
限流:
1
2
3
4
5
6
7
8
9
10
11
12
| await app.register(fastifyRateLimit, {
global: true,
max: 100, timeWindow: "1 minute",
});
app.post("/api/skills/:id/view",
{ config: { rateLimit: { max: 30, timeWindow: "1 minute" } } },
handler);
app.get("/api/skills/:id/download",
{ config: { rateLimit: { max: 10, timeWindow: "1 minute" } } },
handler);
|
下载是大开销动作,单独抠到 10/min。
trustProxy 必须配白名单,否则攻击者伪造 X-Forwarded-For 绕开 IP 维度限流:
1
| app: { trustProxy: "127.0.0.1,::1,10.0.0.0/8" }
|
反压:
1
2
3
4
5
6
7
| await app.register(underPressure, {
maxEventLoopDelay: 1000,
maxHeapUsedBytes: 1024 * 1024 * 1024,
maxRssBytes: 1500 * 1024 * 1024,
retryAfter: 10,
message: "Server is under pressure",
});
|
事件循环延迟、heap、RSS 触顶时立刻 503 加 Retry-After: 10,告诉客户端「等 10 秒再来」。比让进程被 OOM Killer 杀掉强。
第 12 层:可观测性
排障时有一类场景特别难缠:webhook 触发了,但同步没跑,日志里完全没线索把这两件事连起来。
每行 log 自己拼上 reqId 不现实。AsyncLocalStorage 是这个问题的标准解法:
1
2
3
4
5
6
7
8
9
10
11
12
|
import { AsyncLocalStorage } from "async_hooks";
const als = new AsyncLocalStorage<{ reqId: string }>();
export const requestContext = {
run<T>(reqId: string, fn: () => T) {
return als.run({ reqId }, fn);
},
get(): string | undefined {
return als.getStore()?.reqId;
},
};
|
入口处包一层:
1
2
3
4
5
6
7
8
| app.addHook("onRequest", async (req) => {
const reqId = req.headers["x-request-id"] as string ?? randomUUID();
req.id = reqId;
return new Promise<void>(resolve =>
requestContext.run(reqId, () => resolve())
);
});
|
下游 SyncQueue.enqueue 和 runSync 自动把当前 reqId 写到 log:
1
2
3
4
5
6
| const log = (msg: string, fields = {}) => {
console.log(JSON.stringify({
msg, ...fields,
triggerReqId: requestContext.get(),
}));
};
|
最终效果:
1
2
3
4
5
| POST /api/webhooks/git reqId=abc123
→ syncQueue.enqueue triggerReqId=abc123
→ runSync start triggerReqId=abc123
→ git fetch ok triggerReqId=abc123
→ index updated triggerReqId=abc123
|
排障时按 triggerReqId=abc123 过滤一条命令出整条链路。
加上几个观测端点:
/api/health 返回 JSON 健康/api/sync-state 返回 head sha、上次同步时间、状态、lastError/ready 在首次成功 sync 之前返回 503,让容器编排不会把流量打进来
/api/sync-state 暴露 lastError 是个故意决策。内网服务的诊断比信息收敛重要,但凭证必须脱敏。
第 13 层:Graceful Shutdown
容器编排发 SIGTERM,30 秒后 SIGKILL。这 30 秒里要做四件事:
- 拒绝新请求(health 改成 503)
- 等正在跑的 sync 任务结束
- flush metrics(第 6 层欠下的写盘)
- 关闭 HTTP server
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| let shuttingDown = false;
async function shutdown(signal: string) {
if (shuttingDown) return;
shuttingDown = true;
log(`received ${signal}, shutting down`);
health.markNotReady();
await syncQueue.waitDrain(20_000);
await metricsStore.flush();
await app.close();
process.exit(0);
}
process.on("SIGTERM", () => shutdown("SIGTERM"));
process.on("SIGINT", () => shutdown("SIGINT"));
|
还有一个隐患:git 子进程没有超时。一次 hang 住的 git fetch 会把 sync 队列卡死,shutdown 也等不出来。
1
2
3
| function git(...args: string[]) {
return execa("git", args, { timeout: 120_000 });
}
|
120 秒超时配上 fetch 失败重试 1 次、3 秒指数退避,把「永久挂起」转成「显式失败」,sync 队列继续往下流。
第 14 层:部署形态对代码组织的反向影响
产品功能到这里基本完成。部署形态会反过来重塑代码组织。
单 CJS bundle。容器平台只跑 node bin/server.js,期待找到 dist/server/index.js:
1
2
3
4
5
| {
"scripts": {
"build:server": "esbuild src/server/index.ts --bundle --platform=node --target=node18 --format=cjs --outfile=dist/server/index.js"
}
}
|
第一版加 --packages=external,不打包 node_modules,体积更小。部署上去发现找不到 fastify,因为部署机镜像里没有 npm,也没有 node_modules。改回内联依赖(去掉 --packages=external 即可)。
bundle 从 200 KB 变 2.9 MB,但能跑。
dist 入 git 跟踪。这一条违背常规直觉:
1
2
3
|
dist/public/assets/*.map
|
dist/server/index.js 和 dist/public/ 都要提交进仓库。前提条件是部署机没有构建环境。脱离这个前提下结论就反过来。
sourcemap linked:
prod 栈跟踪能反映射回 TS 源行。栈丢源行后线上 bug 等于黑盒。
bundle audit:
1
| --metafile=dist/server/meta.json
|
跑一个简单脚本展开 meta.json,看 2.9 MB bundle 里哪些库占了大头。常见的发现是某个意想不到的 transitive dep 占了 30% 体积。
周期同步开关。线上同时开 webhook 和 poll,缺一不可。webhook 平台漏发、配置失效、网络抖动一次,poll 兜底;没有 poll 的话索引可能落后几小时没人发现。
1
2
3
| if (config.syncIntervalMs > 0) {
setInterval(() => syncQueue.enqueue({ reason: "poll" }), config.syncIntervalMs);
}
|
留给下一轮迭代的优化
每个项目都有一份「评估过但还没做」的清单。这种清单的价值是不重复评估,看到「已评估暂未做」可以直接抄结论。
A. 同步阶段把 markdown 预渲染成 HTML。
详情页 bundle 里 react-markdown 加 remark-gfm 加 rehype-sanitize 占了约 80 KB(gzipped 25 KB)。每次进详情页都在客户端 parse 一次同一段 markdown。
方案是索引时在 server 端用同一套 sanitize schema 渲成 HTML,存进 skills.json,前端 dangerouslySetInnerHTML 直发。前后端共享一份 sanitize schema 是关键。
风险点:skills.json 变大几 MB;schemaVersion 升到 2 时发布顺序必须是「先发能读 v1/v2 的新 server,再发 v2 index」。
B. 静态产物预压缩加 Brotli 优先。
构建时产 *.gz 和 *.br,nginx 上开 gzip_static on 或 brotli_static on 直发,runtime CPU 归零。
风险点是反向代理是否编译了 brotli 模块,没编译就只开 gzip。
C. git cat-file --batch 加 ls-tree -r。
索引时几百次 fs.readFile 加 fs.stat 改成一次常驻 cat-file --batch 子进程加一次 ls-tree -r --long。Tree 接口也走 ls-tree 不走 fs。
收益:sync 从秒级降到亚秒级,tree 冷启动从几十毫秒降到几毫秒。
风险:cat-file --batch 是常驻进程,崩溃要能自愈,复杂度上升。先做 ls-tree(一次性子进程,简单)再上 batchReadBlobs。
一些可迁移的判断
14 层走完,下面这些判断对「只读索引型服务」这一类大多适用。
源与运行时分离:git 是源,本地 mirror 加内存索引是运行时。第 1 层就该定下来。
多触发器并存时用串行队列收口:事件可能来自多个来源的子系统,用一个 single-writer 队列加 debounce 加优先级收口比较稳妥。
失败时保留旧数据:新数据未就绪时旧数据继续服务,对只读索引型服务特别适用。
JSON 持久化的最小安全姿势:tmp 加 fsync 加 rename 加 schemaVersion envelope。
sync 与 read 的并发竞争是隐藏雷区:per-commit snapshot 加原子 symlink swap 是 git 类后端的常见解法。
缓存粒度跟着不变量走:能用 commitSha 当 ETag 就别拍脑袋 timestamp。
安全设施 fails closed:secret 未配置时端点 503,或者路由根本不挂载,比「未配置时放行」安全。
AsyncLocalStorage 把跨边界的因果串起来:不用每行 log 自己拼 reqId。
graceful shutdown 决定线上重启时丢不丢数据:有缓冲的写都要在 SIGTERM 路径上 flush。
部署形态会反过来塑造代码:与其在部署机的约束上盖一层抽象,不如把约束直接当成设计输入。
附:上面这些改进几乎每一条都对应一个单 commit 单意图的实际修改。比起静态架构图,一份按主题归类、附 commit SHA 的「优化历史」清单更能回答「为什么这样写」,新人 onboarding 时往往更用得上。