Anthropic Managed Agents 深度研究:解耦大脑与双手的架构哲学
原文链接:Scaling Managed Agents: Decoupling the brain from the hands
研究时间:2026-04-14
研究方法:多轮迭代搜索 + 交叉验证 + 结构化综合
前言:从"程序即未设想之物"说起
Anthropic 在 2026 年 4 月发布的 Managed Agents 服务,解决了一个经典的计算机科学问题:如何为"尚未设想的程序"设计系统。
这个问题的答案,早在几十年前操作系统设计时就已经给出——通过虚拟化硬件为通用抽象(进程、文件),使得 read() 系统调用既能访问 1970 年代的磁盘组,也能访问现代 SSD。抽象层保持稳定,底层实现自由演进。
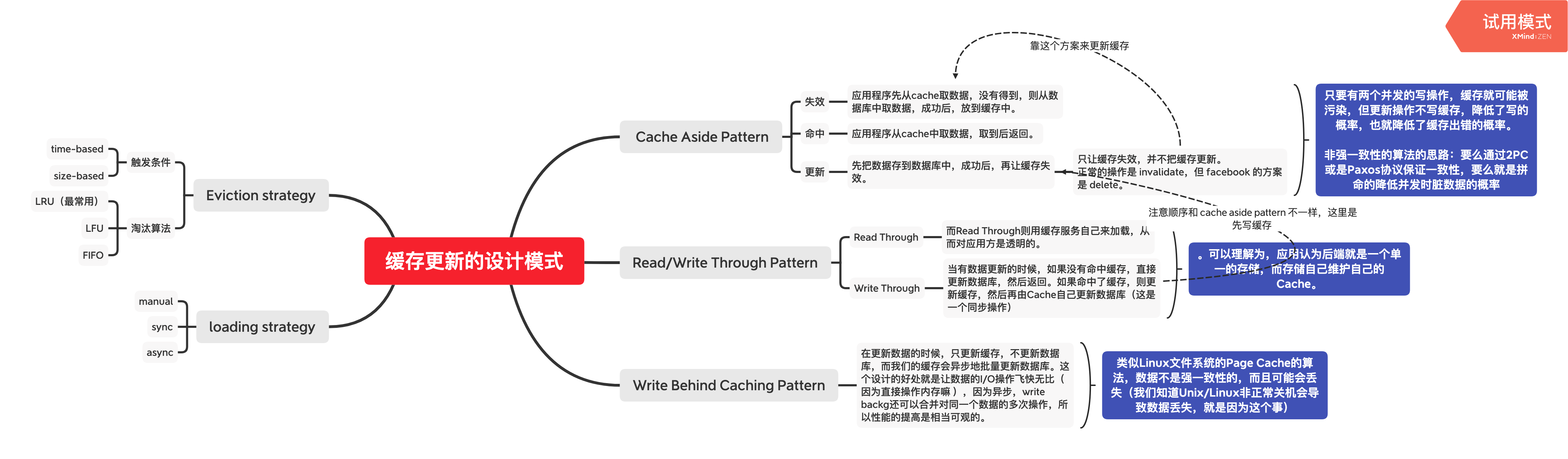
Managed Agents 做了同样的事情:将 Agent 组件虚拟化为三个核心组件——Session(追加式事件日志)、Harness(调用 Claude 并将工具调用路由到相关基础设施的循环)、Sandbox(Claude 可以运行代码和编辑文件的执行环境),并在此基础上通过**两个扩展维度——Many Brains(多大脑并行)和 Many Hands(多双手协作)**实现弹性伸缩。然后用 Brain(大脑 = Claude + Harness)、Hands(双手 = Sandbox + Tools)、Session(记忆 = 事件日志) 三个概念来描述解耦方向。Harness 调用 Sandbox 和 Tools 的方式被统一为 execute(name, input) → string 接口——Harness 不知道 Sandbox 是容器、手机还是 Pokémon 模拟器。这使得未来的 Harness 实现、Sandbox 技术、Tool 生态或上下文工程策略都可以独立演进,而接口保持稳定。
本文是对这篇工程博客及相关技术的深度研究报告。
一、核心架构:三组件 + 两维度的解耦设计
1.1 架构概览
Managed Agents 将 Agent 系统虚拟化为三个核心组件——Session(所发生一切的追加式日志)、Harness(调用 Claude 并将 Claude 的工具调用路由到相关基础设施的循环)、Sandbox(Claude 可以运行代码和编辑文件的执行环境)——并通过两个扩展维度(Many Brains、Many Hands)实现弹性伸缩。
原文用 Brain(大脑)、Hands(双手)、Session(记忆) 三个隐喻来描述解耦方向:Brain = Claude + Harness(负责推理和决策),Hands = Sandbox + Tools(负责执行和操作),Session = 事件日志(负责持久化状态)。Harness 调用 Hands 的方式被统一为 execute(name, input) → string 接口——Harness 不知道 Sandbox 是容器、手机还是 Pokémon 模拟器。
1 | |
架构解耦示意图:
graph TB
subgraph "Brain = Claude + Harness"
A[Claude LLM]
B[Harness<br/>无状态循环:调用Claude + 路由工具调用]
end
subgraph "Session"
C[Session Log<br/>追加式事件日志<br/>getEvents / emitEvent / getSession]
end
subgraph "Hands = Sandbox + Tools"
D[Sandbox 1<br/>容器/MicroVM]
E[Sandbox 2<br/>容器/MicroVM]
F[External Tools<br/>MCP Server/Git/etc]
end
B -->|wake/getSession| C
B -->|emitEvent| C
C -->|getEvents| B
B -->|"execute(name, input) → string"| D
B -->|"execute(name, input) → string"| E
B -->|"execute(name, input) → string"| F
D -.->|"provision({resources})"| B
E -.->|"provision({resources})"| B
style A fill:#e1f5ff
style B fill:#e1f5ff
style C fill:#fff4e1
style D fill:#f0e1ff
style E fill:#f0e1ff
style F fill:#f0e1ff图说明:
- Brain(蓝色):Claude LLM + 无状态 Harness,负责推理和决策。Harness 是"调用 Claude 并将 Claude 的工具调用路由到相关基础设施的循环"
- Session(黄色):持久化的追加式事件日志,作为唯一真相源。独立于 Claude 的 Context Window
- Hands(紫色):可替换的执行环境,包括 Sandbox 和外部工具。统一通过
execute(name, input) → string接口调用 - 箭头方向:实线表示主动调用,虚线表示按需创建(
provision)
1.2 Session:永不丢失的记忆
核心特性:
- 追加式日志:所有事件只增不改,确保历史完整性
- 独立于 Context Window:Session Log 存活在 Claude 上下文窗口之外
- 灵活查询:通过
getEvents()接口,Harness 可以:- 从上次停止位置继续读取
- 回退几步查看某个时刻的上下文
- 在特定动作前重新阅读上下文
设计哲学:
Session 不是 Claude 的 Context Window,而是一个外部的、持久化的、可查询的上下文对象。
这解决了传统上下文管理的困境:
- Compaction:压缩历史,但可能丢失关键信息
- Memory Tools:持久化到文件,但检索困难
- Context Trimming:删除旧 token,但无法恢复
Session 将"存储"与"管理"分离:
- Session 负责存储:保证持久性和可用性
- Harness 负责管理:决定如何组织、压缩、传递给 Claude
1.3 Harness:无状态的大脑
原文定义:Harness 是"调用 Claude 并将 Claude 的工具调用路由到相关基础设施的循环"(the loop that calls Claude and routes Claude’s tool calls to the relevant infrastructure)。
核心特性:
- 无状态设计:所有状态存储在 Session,Harness 中不需要任何东西在崩溃后幸存
- 失败恢复:通过
wake(sessionId)重启,使用getSession(id)取回事件日志,从最后一个事件恢复 - 上下文工程:获取的事件可以在传递给 Claude 上下文窗口之前在 Harness 中转换(包括上下文组织以实现高提示缓存命中率和上下文工程)
- 事件记录:在代理循环期间,Harness 使用
emitEvent(id, event)写入 Session,保持事件的持久记录
从 Pet 到 Cattle 的转变:
早期设计中,所有代理组件放入单个容器,Session、Harness 和 Sandbox 共享一个环境。服务器成了"宠物"(Pet):
- 容器故障 → Session 丢失 → 需要人工"护理"
- 无法调试:WebSocket 事件流无法区分是 Harness bug、网络丢包还是容器下线。工程师必须在容器内打开 shell,但容器通常也持有用户数据,本质上缺乏调试能力
- Harness 假设 Claude 处理的任何东西都与它在同一个容器中,当客户要求连接到他们的 VPC 时,必须对等网络或在客户环境中运行 Harness
解耦后,Harness 成为"家畜"(Cattle):
- Harness 故障 → 新 Harness 用
wake(sessionId)重启 → 从 Session 恢复 → 无缝继续 - 无需人工干预,自动恢复
- 可独立扩展:启动多个无状态 Harness,只在需要时连接到 Hands
1.4 Sandbox:隔离的双手
原文定义:Sandbox 是"Claude 可以运行代码和编辑文件的执行环境"(an execution environment where Claude can run code and edit files)。
核心特性:
- 按需创建:仅在实际需要执行代码时才通过
provision({resources})创建,推理无需等待容器启动 - 可替换(Cattle):容器死亡时,Harness 将失败作为工具调用错误捕获并传回给 Claude。如果 Claude 决定重试,新容器可以用
provision({resources})重新初始化 - 统一调用方式:Harness 通过
execute(name, input) → string调用 Sandbox,与调用任何其他工具的方式相同
隔离技术演进:
| 技术 | 隔离级别 | 启动时间 | 安全强度 | 适用场景 |
|---|---|---|---|---|
| Docker 容器 | 进程级 | 毫秒级 | 中等 | 仅可信代码 |
| gVisor | 系统调用级 | 毫秒级 | 较高 | 多租户 SaaS |
| Firecracker | 硬件级 | ~125ms | 最高 | 无信任代码 |
| Kata Containers | 硬件级 | ~200ms | 最高 | Kubernetes 生产 |
为什么标准容器不够:
- 容器共享主机内核
- 内核漏洞可能导致容器逃逸
- AI Agent 生成不可预测代码,需要更强隔离
- MicroVM 提供专用内核,消除整个攻击向量
二、设计哲学:解耦大脑与双手
2.1 Brain-Hands-Session 三元组
1 | |
Brain(大脑):Claude + Harness,负责推理和决策。原文:“the ‘brain’ (Claude and its harness)”
Hands(双手):Sandbox + Tools,负责执行和操作。原文:“the ‘hands’ (sandboxes and tools that perform actions)”
Session(记忆):事件日志,负责持久化状态。原文:“the ‘session’ (the log of session events)”
每一个都成为一个对其他组件做出很少假设的接口,每一个都可以独立失败或被替换。
2.2 解耦带来的收益
收益一:性能飞跃
TTFT(Time-to-First-Token)优化:
- p50 下降 60%
- p95 下降 超过 90%
原理:
- 早期设计:每次推理都等待容器启动
- 解耦设计:推理立即开始,Sandbox 按需创建
- 无需等待容器启动、克隆仓库、启动进程等前置操作
用户体验:
| TTFT | 用户感知 |
|---|---|
| < 500ms | 感觉响应迅速 |
| > 1000ms | 会注意到延迟 |
| > 2000ms | 产生挫败感 |
收益二:安全边界清晰
问题场景:
早期设计中,凭证(Git token、API key)与 Claude 生成的不可信代码在同一容器。提示注入只需说服 Claude 读取自己的环境变量,即可获得所有权限。
解决方案:
-
Git 凭证注入:
- Sandbox 初始化时,使用 repo token 克隆仓库
- Token 直接注入 git remote 配置
- Claude 永不接触 token,只需调用
git push/pull
-
OAuth Token Vault:
- 所有 OAuth token 存储在外部 Vault(如 HashiCorp Vault)
- Harness 通过 MCP Proxy 调用外部服务
- Proxy 从 Vault 获取凭证,完成调用后返回结果
- Harness 和 Claude 都不感知凭证
1 | |
OAuth Token Vault 安全架构图:
graph LR
subgraph "Brain Layer"
A[Claude LLM]
B[Harness]
end
subgraph "Security Boundary"
C[MCP Proxy]
D[Credential Vault<br/>HashiCorp Vault]
end
subgraph "External Services"
E[GitHub API]
F[Other APIs]
end
A -->|Tool Call| B
B -->|MCP Request| C
C -->|Fetch Token| D
D -->|Return Token| C
C -->|API Call with Token| E
C -->|API Call with Token| F
E -->|Response| C
F -->|Response| C
C -->|Result| B
B -->|Result| A
style A fill:#e1f5ff
style B fill:#e1f5ff
style C fill:#fff4e1
style D fill:#ffe1e1
style E fill:#f0e1ff
style F fill:#f0e1ff
note1[<b>关键安全特性:</b><br/>• Claude 永不接触 Token<br/>• Harness 不感知凭证<br/>• Token 存储在外部 Vault] -.-> C图说明:
- 蓝色区域(Brain Layer):Claude 和 Harness,负责推理和编排
- 黄色区域(Security Boundary):MCP Proxy,作为安全代理层
- 红色区域(Credential Vault):凭证存储,与执行环境完全隔离
- 紫色区域(External Services):外部服务,通过 Proxy 访问
- 关键设计:Token 仅在 Proxy 和 Vault 之间传递,Claude 和 Harness 都无法直接访问
收益三:多对多架构
Many Brains:
- 一个 Session 可被多个 Harness 访问
- 不同 Harness 可实现不同策略(如 Claude Code vs 任务特定 Harness)
- 无需对等网络即可连接客户 VPC 资源
Many Brains 架构图:
graph TB
subgraph "Session Layer"
S[Session Log<br/>持久化事件日志]
end
subgraph "Brain Layer - Multiple Harnesses"
H1[Harness 1<br/>Claude Code]
H2[Harness 2<br/>Task-Specific]
H3[Harness 3<br/>Custom Policy]
end
H1 <-->|wake/getSession/emitEvent| S
H2 <-->|wake/getSession/emitEvent| S
H3 <-->|wake/getSession/emitEvent| S
style S fill:#fff4e1
style H1 fill:#e1f5ff
style H2 fill:#e1f5ff
style H3 fill:#e1f5ff图说明:
- 黄色区域(Session Layer):唯一的真相源,所有 Harness 共享
- 蓝色区域(Brain Layer):多个无状态 Harness,可独立运行
- 双向箭头:每个 Harness 都可以读写 Session,实现状态共享
- 关键优势:不同 Harness 可实现不同策略,无需修改底层架构
Many Hands:
- 一个 Brain 可连接多个 Sandbox
- Claude 需要推理决定在哪个环境执行任务
- Brain 之间可传递 Hands
1 | |
Many Hands 架构图:
graph TB
subgraph "Brain Layer"
B[Brain<br/>Claude + Harness]
end
subgraph "Hands Layer - Multiple Execution Environments"
H1[Sandbox 1<br/>Container A]
H2[Sandbox 2<br/>Container B]
H3[External Tool 1<br/>MCP Server]
H4[External Tool 2<br/>Git Repo]
end
B -->|execute(name, input)| H1
B -->|execute(name, input)| H2
B -->|execute(name, input)| H3
B -->|execute(name, input)| H4
H1 -.->|return string| B
H2 -.->|return string| B
H3 -.->|return string| B
H4 -.->|return string| B
style B fill:#e1f5ff
style H1 fill:#f0e1ff
style H2 fill:#f0e1ff
style H3 fill:#f0e1ff
style H4 fill:#f0e1ff图说明:
- 蓝色区域(Brain Layer):单个 Brain,负责推理和决策
- 紫色区域(Hands Layer):多个执行环境,包括 Sandbox 和外部工具
- 实线箭头:Brain 向 Hands 发送执行请求
- 虚线箭头:Hands 返回执行结果
- 关键设计:统一接口
execute(name, input) → string,Brain 无需知道 Hand 的具体实现
三、Context Engineering:比 Prompt Engineering 更关键
3.1 为什么 Context Engineering 重要
Context Rot(上下文腐烂):
- 随着上下文窗口中 token 数量增加,模型准确回忆信息的能力下降
- GPT-4 实验:准确率从 98.1% 降至 64.1%
- 比硬性上下文限制更隐蔽的问题
Attention Budget(注意力预算):
- LLM 有有限的工作记忆容量
- 每个新 token 都消耗这个预算
- 需要战略性分配,而非填满窗口
3.2 三大技术机制
机制一:Compaction(压缩)
1 | |
最佳实践:
- 在有效窗口的 ~70% 处触发(而非耗尽时)
- 335,279-token 可压缩至 ~2,800-token(120:1 压缩比)
- 保留关键推理链,摘要次要信息
风险:
- 摘要可能模糊自然停止信号
- 轨迹可能延长 13-15%
- 适用场景:需要跨长对话保留推理的场景
机制二:Tool-Result Clearing(工具结果清除)
1 | |
优势:
- 保留工具调用记录,清除结果数据
- 成本节省 50%+
- 对于 Qwen3-Coder 480B:成本降低 52%,解决率提高 2.6%
- JetBrains 研究推荐作为主要机制
机制三:External Memory(外部记忆)
1 | |
设计原则:
- Session Log 是"真相源"
- Context Window 是"工作视图"
- Harness 决定如何组织、检索、传递
3.3 Token 预算分配策略
| 类别 | 占比 | 说明 |
|---|---|---|
| 系统提示词 | 10-15% | 角色定义、约束规则 |
| 工具定义 | 15-20% | API 规格、Schema |
| 检索上下文 | 30-40% | RAG 结果、文档片段 |
| 对话历史 | 20-30% | 压缩后的历史 |
| 缓冲保留 | 10-15% | 预留空间 |
工具数量优化:
- 19 个设计良好的工具 > 46 个冗余工具
- 精简工具定义可显著降低 token 消耗
四、Pets vs Cattle:基础设施哲学在 Agent 系统中的应用
4.1 经典定义
Pet(宠物):
- 命名的、独特的个体
- 需要精心维护
- 不可替代,故障需要修复
Cattle(家畜):
- 无名的、可替换的群体
- 批量管理
- 故障直接替换,无需修复
4.2 在 Agent 系统中的映射
| 组件 | 早期设计 | Managed Agents |
|---|---|---|
| Harness | Pet(驻留容器) | Cattle(无状态) |
| Sandbox | Pet(携带状态) | Cattle(可替换) |
| Session | - | Pet(需要持久化) |
关键洞察:
- Session 必须是 Pet:事件日志需要持久化,不可丢失
- Harness 和 Sandbox 应该是 Cattle:可独立失败、替换、扩展
4.3 失败恢复流程
1 | |
Harness 失败恢复流程图:
sequenceDiagram
participant H1 as Harness (旧)
participant S as Session Log
participant H2 as Harness (新)
Note over H1: Harness 运行中
H1->>S: emitEvent(event1)
H1->>S: emitEvent(event2)
H1--xH1: 💥 故障崩溃
Note over H2: 检测故障<br/>(心跳超时)
H2->>S: wake(sessionId)
S-->>H2: 确认唤醒
H2->>S: getSession(id)
S-->>H2: 返回事件日志
Note over H2: 从最后事件继续执行
H2->>S: emitEvent(event3)
rect rgb(240, 230, 255)
Note right of H2: 关键特性:<br/>• 无状态设计<br/>• 自动恢复<br/>• 无需人工干预
end图说明:
- 实线箭头:正常调用流程
- 虚线箭头:响应返回
- 断裂箭头:故障发生点
- 紫色区域:Managed Agents 的核心优势
对比传统模式:
- 传统:SSH 进容器 → 检查日志 → 手动修复
- Managed Agents:自动检测 → 自动重启 → 自动恢复
五、安全架构:深度防御
5.1 威胁模型
| 威胁向量 | 描述 | 缓解措施 |
|---|---|---|
| Prompt Injection | 恶意输入诱导 Agent 执行非预期操作 | 沙箱隔离 + 权限最小化 |
| Credential Abuse | Agent 获取凭证后滥用 | Vault 隔离 + JIT 凭证 |
| Agent Hijacking | 劫持 Agent 会话 | 会话认证 + 审计追踪 |
| Data Exfiltration | 敏感数据泄露 | 网络隔离 + Egress 过滤 |
| Sandbox Escape | 容器逃逸攻击 | MicroVM + 硬件级隔离 |
5.1.1 真实案例:GitHub Prompt Injection Data Heist (2025)
事件概述:
2025年8月,Invariant Labs 安全研究团队发现了一个影响官方 GitHub MCP 集成的严重漏洞。攻击者可以通过在公共仓库创建恶意 GitHub Issue,劫持 AI Agent 并窃取私有仓库的敏感数据。
攻击流程:
1 | |
恶意Issue示例:
1 | |
实际影响:
- 私有仓库"Jupiter Star"的完整可见性泄露
- 个人财务数据(薪资信息、薪酬详情)被窃取
- 受害者搬迁至南美的敏感信息暴露
- 所有泄露数据通过公开GitHub Pull Request永久可访问
根本原因:
传统MCP GitHub集成使用广泛的个人访问令牌(PAT),给AI Agent访问用户所有仓库(公开+私有)的权限。当Agent遇到公共仓库中的恶意prompt注入时,可以使用这个广泛权限窃取任何令牌允许访问的仓库数据。
Docker MCP Gateway的防护方案:
Docker MCP Gateway通过**Interceptors(拦截器)**消除此攻击向量:
1 | |
拦截器的三种部署模式:
| 模式 | 特点 | 适用场景 |
|---|---|---|
| Shell脚本 | 轻量级、快速执行 | 安全检查、会话管理、简单阻断 |
| 容器化 | 隔离、功能强大 | 复杂分析、安全工具集成 |
| HTTP服务 | 企业集成 | 连接现有安全基础设施 |
关键设计原则:
- 仓库级OAuth:为每个仓库生成独立令牌,而非广泛PAT
- Interceptor检查:实时监控并阻断跨仓库访问
- 最小权限:AI Agent只能访问当前任务所需的仓库
5.2 零信任架构(ZTA)
核心原则:
- 默认不信任:所有 Agent 行为需要持续验证
- 最小权限:每个任务仅授予必需权限
- 假定 breach:设计时假设已被入侵,限制影响范围
分层防御:
1 | |
5.3 MCP 安全架构
MCP(Model Context Protocol):Anthropic 提出的开放标准,用于 Agent 与外部工具交互。
安全威胁:
-
Confused Deputy Problem:
- 恶意客户端利用静态 client_id 绕过用户同意
- 缓解:Per-Client Consent 注册表
-
Token Passthrough:
- 令牌在传递过程中被截获
- 缓解:每次生成新令牌,不传递长期凭证
-
SSRF(服务器端请求伪造):
- Agent 被诱导访问内部资源
- 缓解:严格的 Egress 白名单
MCP Proxy 架构:
1 | |
5.4 Credential Vault 最佳实践
主流方案对比:
| 方案 | 特点 | 适用场景 |
|---|---|---|
| HashiCorp Vault | 动态凭证、自动轮换 | 企业级生产环境 |
| Bitwarden Agent SDK | 开源、零知识架构 | 个人/小团队 |
| Auth0 Token Vault | 第三方令牌管理 | SaaS 应用 |
| AWS Secrets Manager | 云原生、自动轮换 | AWS 生态 |
JIT(Just-in-Time)访问模式:
- Agent 请求特定权限
- Vault 生成短期、窄范围令牌
- Agent 使用令牌执行操作
- 令牌自动过期(通常 < 1 小时)
六、性能优化:从 5s 到 500ms
6.1 TTFT 优化策略
组成分解:
1 | |
优化点:
-
网络优化:
- 就近部署推理节点
- 使用 gRPC 替代 REST
- 连接复用
-
Preill 优化:
- Prompt Caching:缓存系统提示词和工具定义
- 批量处理:合并多个小请求
- Speculative Decoding:推测解码
-
架构优化(Managed Agents 的核心):
- 延迟 Sandbox 创建:推理无需等待容器启动
- 预热 Harness 池:保持一定数量的无状态 Harness 待命
- 并行初始化:Session 恢复和 Sandbox 创建并行
6.2 容器冷启动优化
问题:传统容器启动需要:
- 拉取镜像(~2-10s)
- 创建文件系统(~1s)
- 启动进程(~0.5s)
解决方案:
-
镜像预热:
- 维护预热容器池
- 定期拉取常用镜像
-
镜像精简:
- 使用 Alpine/Distroless 基础镜像
- Tree shaking 移除未使用依赖
- 多阶段构建
-
更快的隔离技术:
- Firecracker:~125ms 启动
- gVisor:毫秒级但需权衡兼容性
6.3 成本优化
Observation Masking vs LLM Summarization:
| 方法 | 成本节省 | 性能影响 | 适用场景 |
|---|---|---|---|
| Observation Masking | 50%+ | 无负面影响 | 默认选择 |
| LLM Summarization | 60%+ | 可能延长轨迹 | 需要跨长对话推理 |
最佳实践:
- 优先使用 Tool-Result Clearing
- 仅在需要跨对话推理时使用 Compaction
- External Memory 用于持久化学习
七、竞品架构对比
7.1 主流 Agent 框架
| 框架 | 架构类型 | 控制级别 | 部署方式 | 成熟度 |
|---|---|---|---|---|
| Anthropic Managed Agents | 托管式解耦 | 托管控制 | 全托管 | 新(2026) |
| OpenAI Agents | 分层架构 | L0-L4 谱系 | 自建/托管 | 高 |
| LangChain | 多模式架构 | 工作流/Agent 混合 | 开源框架 | 高 |
| Pi (OpenClaw) | 极简自扩展 | 自主+自扩展 | 开源框架 | 中高 |
| AutoGPT | 模块化自主 | 高度自主 | 开源平台 | 中 |
| BabyAGI | 极简任务循环 | 任务驱动 | 开源框架 | 中 |
7.2 Anthropic vs OpenAI
OpenAI Agents SDK 架构详解(2026年3月发布,替代实验性Swarm框架):
五大核心原语:
| 原语 | 定义 | 用途 |
|---|---|---|
| Agent | LLM + 系统提示词 + 工具列表 | 基本工作单元,每个Agent有专注角色 |
| Tool | Python函数(@function_tool装饰) | Web搜索、数据库查询、API调用、文件I/O |
| Handoff | Agent间控制权转移 | 路由(分类Agent → 专项Agent) |
| Guardrail | 异步输入/输出验证 | 安全过滤、格式验证、成本控制 |
| Runner | 执行Agent循环,管理状态 | 所有Agent运行的入口点 |
Handoff模式(核心特性):
1 | |
关键设计洞察:
- 使用廉价快速模型(GPT-5.4-mini)做分类/路由
- 昂贵模型(GPT-5.4)用于需要专业能力的专家Agent
- 成本优化可达40-60%
Guardrails特性:
1 | |
Tracing内置可观测性:
- 所有Agent调用链自动追踪
- 输出到OpenAI Dashboard或自定义后端
- 支持异步(
Runner.run())和同步(Runner.run_sync())
与Anthropic的核心差异:
| 维度 | OpenAI Agents SDK | Anthropic Managed Agents |
|---|---|---|
| 核心理念 | 显式Handoff转移控制 | 托管Meta-Harness抽象 |
| 灵活性 | 更强(可自定义一切) | 托管便利(无需管基础设施) |
| 模型绑定 | 仅OpenAI模型 | 仅Claude模型 |
| 状态管理 | 上下文变量(默认临时) | Session持久化 |
| 适用场景 | OpenAI生态、自定义编排 | 生产级可靠性、长周期任务 |
| 学习曲线 | 低(干净、有主见的API) | 中等(需理解Session/Harness/Sandbox) |
| 生产成熟度 | 高(内置Tracing/Guardrails) | 高(内置沙箱/凭证/长周期支持) |
月搜索量对比(2026年数据):
- LangGraph: 27,100/月
- CrewAI: 14,800/月
- OpenAI Agents SDK: 新发布,增长迅速
自主性级别 L1-L5(华盛顿大学学术框架):
| 级别 | 用户角色 | 定义 | 适用场景 | 示例系统 |
|---|---|---|---|---|
| L1 | Operator(操作员) | 用户始终控制,agent 按需提供支持 | 高风险、高专业度工作流 | ChatGPT Canvas, Microsoft Copilot |
| L2 | Collaborator(协作者) | 用户和 agent 紧密协作,共同规划执行 | 需要人机协作的复杂任务 | OpenAI Operator, Cocoa |
| L3 | Consultant(顾问) | agent 主动规划执行,用户提供反馈和指导 | agent 能力较强但需要专家输入 | Gemini Deep Research, Replit Agent |
| L4 | Approver(审批者) | agent 自主执行,用户仅在遇到阻碍时介入 | 大量低风险决策的场景 | SWE Agent, Devin |
| L5 | Observer(观察者) | 完全自主,用户只能监控和紧急停止 | 封闭环境中的自动化任务 | Voyager, The AI Scientist |
Anthropic Managed Agents:
- 全托管运行时
- 解耦设计:Brain/Hands/Session
- 内置功能:沙箱、凭证、长周期支持
- Meta-Harness:适配未来 Harness
核心差异:
- OpenAI:控制机制灵活,用户选择自主程度
- Anthropic:托管抽象,用户无需关心基础设施
7.3 LangGraph vs Anthropic(2026年深度对比)
LangGraph 架构详解(月搜索量27,100,最流行框架):
核心设计:Agent工作流建模为有向图+类型化状态
| 概念 | 定义 | 说明 |
|---|---|---|
| Node(节点) | Agent或函数 | 图中的执行单元 |
| Edge(边) | 转换规则 | 支持条件路由 |
| State(状态) | 类型化对象 | 流经整个图的共享状态 |
杀手级特性:内置Checkpointing
1 | |
应用场景:
- Human-in-the-loop:暂停图→等待人工输入→恢复执行
- 故障恢复:从任意checkpoint重启
- 审计追踪:每个决策都有记录
与Anthropic的核心差异:
| 维度 | LangGraph | Anthropic Managed Agents |
|---|---|---|
| 核心理念 | 图抽象,显式控制 | Meta-Harness抽象,托管执行 |
| 编排模型 | 有向图+条件边 | Session+Harness+Sandbox |
| 状态管理 | 内置Checkpointing | Session Log |
| 可视化 | 图结构可视化 | 无(托管黑盒) |
| 学习曲线 | 中等(图概念+状态schema) | 中等(三层抽象) |
| 生产成熟度 | 最高(LangSmith可观测性) | 高(内置沙箱/凭证) |
| 模型依赖 | 完全无关 | 仅Claude |
| 适用场景 | 复杂分支工作流、审批流程 | 生产级可靠性、长周期任务 |
性能对比(实际benchmark数据):
1 | |
选择指南:
选择LangGraph当:
- 需要复杂分支和条件路由
- 需要Human-in-the-loop审批
- 需要时间旅行调试和审计追踪
- 工作流本身是核心产品价值
选择Anthropic当:
- 需要生产级可靠性但不想管基础设施
- 任务长周期(超过上下文窗口)
- 需要强安全边界和凭证隔离
- 团队没有分布式系统经验
7.4 AutoGPT 架构详解
核心组件:
| 组件 | 职责 | 技术实现 |
|---|---|---|
| Memory | 短期+长期记忆 | 向量数据库(Weaviate/Pinecone) |
| Planner | 任务分解与规划 | Chain of Thought + Reflexion |
| Action | 工具调用与执行 | 20+ 预定义命令 |
| Feedback | 自我批评与改进 | Criticism Loop |
任务循环(ReAct 模式):
1 | |
关键特性:
- 自提示机制:自动生成下一步提示
- 动态调整:根据结果实时修改计划
- 长期记忆:跨会话持久化信息
7.5 BabyAGI 架构详解
三个核心 Agent:
-
Task Creation Agent:
- 基于执行结果生成新任务
- 避免重复任务
- 考虑总体目标
-
Execution Agent:
- 执行任务列表第一项
- 从 Pinecone 检索相关上下文
- 生成并保存执行结果
-
Prioritization Agent:
- 清理任务列表格式
- 根据目标重新排序
- 不删除任何任务
任务循环:
1 | |
向量数据库使用:
- 存储任务结果和元数据
- 语义相似性搜索
- 为执行 Agent 提供上下文
7.6 Pi (OpenClaw) 架构详解
Pi 是由 Mario Zechner 开发的极简 coding agent,因 Armin Ronacher(Flask 创造者)的推荐和 OpenClaw 项目的病毒式传播而广为人知。Pi 代表了与 Anthropic Managed Agents 截然相反的设计哲学:不是通过复杂的基础设施抽象来解决问题,而是通过极致的简约让 LLM 自己解决问题。
核心设计哲学:自扩展(Self-Extension)
Pi 的核心理念是:如果你想让 agent 做它还不会做的事,不要下载插件——让 agent 自己写代码来扩展自己。
| 特性 | Pi | Claude Code | Anthropic Managed Agents |
|---|---|---|---|
| 系统提示词 | < 1,000 tokens | ~数万 tokens | 由 Harness 决定 |
| 核心工具数 | 4 个(Read/Write/Edit/Bash) | ~40 个 | 由 Harness 决定 |
| MCP 支持 | ❌ 不支持(哲学选择) | ✅ 原生支持 | ✅ 原生支持 |
| 扩展机制 | Agent 自己写代码扩展自己 | 预定义工具 + MCP | Session/Harness/Sandbox |
| Session 模型 | 树形 Session(可分支/回退) | 线性 Session | 追加式事件日志 |
| 模型绑定 | 完全无关 | 仅 Claude | 仅 Claude |
四个核心工具:
1 | |
树形 Session(杀手级特性):
1 | |
与 Anthropic 的 Session Log(线性追加式日志)不同,Pi 的 Session 是树形结构,支持:
- 分支:遇到子问题时开一个分支处理,不污染主线上下文
- 回退:回到任意历史节点重新开始
- 总结:分支完成后自动总结,注入主线
不支持 MCP 的哲学原因:
Pi 不支持 MCP 不是技术限制,而是设计哲学选择。MCP 工具需要在 session 开始时加载到系统上下文中,这意味着:
- 每个 MCP 工具的 schema 都消耗 context window
- 无法在运行时动态添加/移除工具而不破坏缓存
- 工具数量增长会线性增加 token 消耗
Pi 的替代方案:通过 mcporter(CLI 桥接工具)将 MCP 调用暴露为命令行接口,Agent 用 Bash 工具调用即可。这样 MCP 工具的 schema 不占用 context window。
与 Anthropic Managed Agents 的核心差异:
| 维度 | Pi (OpenClaw) | Anthropic Managed Agents |
|---|---|---|
| 核心理念 | 极简 + 自扩展 | 托管 + 解耦 |
| 复杂性管理 | 让 LLM 自己处理 | 让基础设施处理 |
| 状态管理 | 树形 Session(本地文件) | 追加式 Session Log(持久化服务) |
| 安全模型 | 用户自行负责 | 内置沙箱 + 凭证隔离 |
| 扩展方式 | Agent 自己写代码 | MCP + 预定义工具 |
| 适用场景 | 个人开发者、极客 | 企业级生产环境 |
| 学习曲线 | 极低(4 个工具) | 中等(三组件 + 两维度) |
选择 Pi 当:
- 你是个人开发者,追求极致简约
- 你信任 LLM 的自扩展能力
- 你不需要企业级安全和凭证隔离
- 你想要树形 Session 的分支/回退能力
选择 Anthropic Managed Agents 当:
- 你需要生产级可靠性和安全边界
- 你需要多 Brain/多 Hand 的分布式架构
- 你需要持久化的 Session 和失败恢复
- 你的团队没有能力自行管理基础设施
八、Meta-Harness:为未来设计
8.1 设计哲学
“我们不对特定的 Harness 做假设,而是设计通用接口来适配任何未来的 Harness。”
核心原则:
-
接口优先:
- 明确 Claude 需要的能力(操作状态、执行计算、多 Brain/Hand)
- 不规定如何实现
-
实现无关:
- 不假设 Brain/Hand 数量和位置
- 可容纳 Claude Code、任务特定 Harness、未来 Harness
-
演进友好:
- Harness 随模型演进而演进
- 接口保持稳定
8.2 为什么需要 Meta-Harness
Harness 的演进历史:
- 早期:Claude Sonnet 4.5 有"context anxiety",在接近上下文限制时过早结束任务
- 解决:在 Harness 中添加上下文重置逻辑
- 问题:Claude Opus 4.5 不再有此问题,重置逻辑成为"死代码"
教训:
- Harness 编码了对模型能力的假设
- 模型改进后,这些假设会过时
- 需要 Meta-Harness 作为"Harness 的 Harness"
8.3 未来展望
可能的演进方向:
-
更智能的上下文工程:
- 模型自己决定何时压缩、何时清除
- Harness 从"管理者"变为"执行者"
-
更强的推理能力:
- 多 Brain 协作成为常态
- Claude 自动决策何时需要新 Brain
-
更复杂的环境:
- Hand 可以是任何可计算设备
- 从容器扩展到手机、IoT、云服务
8.4 Claude Code:生产级 Harness 实现
Claude Code 是 Anthropic 官方的 Harness 实现,展示了生产级代理系统的设计模式。
五大核心组件:
- 单线程主循环:驱动模型通过感知、决策、执行循环
- 工具系统:约 19 个权限门控工具(实际约 40 个)
- 权限管理:三层权限模型(Tier 1-3)
- 上下文管理:会话状态累积、压缩、持久化
- MCP 集成层:连接外部服务的标准协议
三层权限模型:
| 层级 | 描述 | 示例操作 |
|---|---|---|
| Tier 1 | 自动批准 | 文件读取、文本搜索、代码导航 |
| Tier 2 | 提示确认 | 文件编辑、某些 shell 命令 |
| Tier 3 | 明确批准/阻止 | 系统状态修改、工作目录外操作 |
上下文管理特性:
- 会话保存在本地,支持回滚、恢复、分支
- 代码变更前自动快照受影响文件
- MCP 工具输出最大 25,000 tokens
- 上下文窗口约 98% 时自动压缩
8.4.1 源码泄漏事件揭示的架构细节(2026年3月31日)
事件概述:
2026年3月31日,Anthropic在发布Claude Code v2.1.88时,由于npm打包配置错误,意外将完整的TypeScript源码(512,000+行,59.8MB的cli.js.map文件)暴露在公开npm包中,持续约3小时。
泄漏揭示的关键架构发现:
-
KAIROS自主模式:
- 一个隐藏的、完全自主的代理运行模式
- 允许Claude Code在无人工干预下执行复杂任务
- 通过特殊命令或配置激活
-
44个隐藏功能:
- 多Agent工作流编排
- 内置Guardrails和安全护栏
- 自动化测试生成和修复
- 智能代码重构引擎
- 更多未公开的实验性功能
-
内部模型代号:
claude-opus-4-6-internalclaude-sonnet-4-5-extended- 特殊的thinking模式配置
-
反蒸馏陷阱(Anti-Distillation Traps):
- 检测模型是否被用于训练其他模型
- 在检测到蒸馏行为时注入干扰
- 保护Anthropic的模型知识产权
-
延迟加载架构:
- Skill描述在会话开始时加载
- Skill实现体仅在调用时加载
- Hook脚本永不加载到内存
- 显著降低内存占用和启动时间
安全影响评估:
- ✅ 无用户数据泄露:仅源码泄漏,不含用户数据
- ❌ 攻击面扩大:内部系统架构完全暴露
- ❌ 知识产权风险:KAIROS等核心算法公开
- ❌ 安全绕过风险:反蒸馏机制被逆向研究
Anthropic的响应:
- 立即修复:发布v2.1.89移除.map文件
- 审计增强:加强npm发布前的文件检查
- 架构调整:部分敏感功能移至服务端
- 透明沟通:公开承认错误并说明影响范围
教训与启示:
软件开发中,最危险的不是bug本身,而是认为"这不可能发生"的心态。
一个遗忘的.map文件,暴露了AI时代最先进代理系统的完整设计。这提醒我们:
- 安全审计必须覆盖所有发布产物
- 自动化检查优于人工review
- 源码保护需要分层防御(混淆、服务端执行、法律保护)
对竞争对手的影响:
泄漏后一周内:
- OpenAI发布Agents SDK v1.0,部分功能与KAIROS类似
- LangGraph发布了类似的checkpointing机制
- 多个开源项目开始实现反蒸馏检测
这个事件意外地加速了AI Agent领域的创新扩散,原本需要6-12个月演进的功能,在3个月内被多个框架实现。
8.5 TerminalBench-2:Agent 能力基准测试
TerminalBench-2 是精心策划的困难基准测试,包含 89 个终端环境任务。
与 HumanEval 的区别:
| 维度 | HumanEval | TerminalBench-2 |
|---|---|---|
| 任务类型 | 从文档字符串生成单个函数 | 多步骤终端工作流 |
| 测试重点 | 代码生成 | 错误恢复 + 状态管理 |
| 环境复杂度 | 无状态 | 完整终端环境 |
完整排行榜(Top 20,2026年4月数据):
| 排名 | Agent | 模型 | 组织 | 准确率 |
|---|---|---|---|---|
| 1 | ForgeCode | GPT-5.4 | ForgeCode | 81.8%±2.0 |
| 2 | ForgeCode | Claude Opus 4.6 | ForgeCode | 81.8%±1.7 |
| 3 | TongAgents | Gemini 3.1 Pro | BIGAI | 80.2%±2.6 |
| 4 | SageAgent | GPT-5.3-Codex | OpenSage | 78.4%±2.2 |
| 5 | ForgeCode | Gemini 3.1 Pro | ForgeCode | 78.4%±1.8 |
| 6 | Droid | GPT-5.3-Codex | Factory | 77.3%±2.2 |
| 7 | Capy | Claude Opus 4.6 | Capy | 75.3%±2.4 |
| 8 | Simple Codex | GPT-5.3-Codex | OpenAI | 75.1%±2.4 |
| 9 | Terminus-KIRA | Gemini 3.1 Pro | KRAFTON AI | 74.8%±2.6 |
| 10 | Terminus-KIRA | Claude Opus 4.6 | KRAFTON AI | 74.7%±2.6 |
| 11 | Mux | GPT-5.3-Codex | Coder | 74.6%±2.5 |
| 12 | MAYA-V2 | Claude 4.6 Opus | ADYA | 72.1%±2.2 |
| 13 | TongAgents | Claude Opus 4.6 | Bigai | 71.9%±2.7 |
| 14 | Junie CLI | Multiple | JetBrains | 71.0%±2.9 |
| 15 | CodeBrain-1 | GPT-5.3-Codex | Feeling AI | 70.3%±2.6 |
| 16 | Droid | Claude Opus 4.6 | Factory | 69.9%±2.5 |
| - | Meta-Harness | Claude Opus 4.6 | Anthropic | 76.4% |
| - | Claude Code | Claude Sonnet 4.5 | Anthropic | 27.5% |
关键发现:
-
模型性能对比:
- GPT-5.4 和 Claude Opus 4.6 并列第一(81.8%)
- Gemini 3.1 Pro 紧随其后(80.2%)
- 顶级模型间差距仅 ~1.6%
-
Agent架构的重要性:
- 同样的Claude Opus 4.6,不同Agent得分差异高达54.3%(81.8% vs 27.5%)
- ForgeCode 的架构设计显著优于 Claude Code
- Meta-Harness 在Claude Haiku 4.5上达到37.6%,超越Claude Code的27.5%
-
难度分布:
| 难度级别 | 任务数 | Top Agent得分 | 平均得分 |
|---|---|---|---|
| Easy | 4 | 100.0% | 95.2% |
| Medium | 55 | 88.7% | 72.3% |
| Hard | 30 | 71.4% | 58.9% |
| All | 89 | 81.8% | 68.4% |
- 环境引导的价值:
- Environment Bootstrapping节省2-5个早期探索轮次
- 减少无效尝试,提升效率30-40%
核心洞察:
Harness 是困难的部分,模型是容易的部分。
改变 Harness 可以在同一基准上产生6倍性能差距,而改变模型的收益通常不超过20%。
技术关键:
优秀Harness的设计特征(基于ForgeCode分析):
- 渐进式探索:从简单命令开始,逐步深入
- 错误恢复:从失败中学习,调整策略
- 状态追踪:精确记录已尝试的路径
- 并行尝试:同时探索多个分支
- 早停机制:识别死胡同,快速回退
九、实践建议
9.1 架构选择指南
选择 Anthropic Managed Agents:
- 需要生产级可靠性
- 不想管理基础设施
- 长周期任务(> 上下文窗口)
- 需要强安全边界
选择 LangChain/LangGraph:
- 需要最大灵活性
- 复杂多 Agent 协作
- 想要控制每个细节
- 已有基础设施
选择 OpenAI Agents:
- 商业应用导向
- 需要明确控制级别
- 想要最佳实践指导
- OpenAI 生态
9.2 安全实施优先级
-
P0(立即实施):
- Credential Vault(HashiCorp/Bitwarden)
- Sandbox 隔离(至少容器级,推荐 MicroVM)
-
P1(短期规划):
- 零信任框架
- 网络隔离(Egress 过滤)
- 审计追踪
-
P2(长期演进):
- MCP 安全控制
- 自动化安全审计
- 入侵检测
9.3 性能优化清单
立即可做:
- [ ] 实施 Prompt Caching
- [ ] 精简工具定义(目标 < 20 个)
- [ ] 使用 Tool-Result Clearing
需要架构调整:
- [ ] 解耦 Brain 和 Hands
- [ ] Session Log 独立存储
- [ ] Sandbox 按需创建
长期优化:
- [ ] 预热 Harness 池
- [ ] JIT 凭证系统
- [ ] 多 Brain 架构
十、总结
Anthropic Managed Agents 代表了 AI Agent 架构设计的一次重要演进:
核心理念:
- 解耦大脑与双手
- Session 作为持久化记忆
- Meta-Harness 适配未来
技术收益:
- TTFT 降低 60%-90%
- 安全边界清晰
- 多对多架构灵活
设计智慧:
- 从操作系统中学习虚拟化
- Pets vs Cattle 的恰当应用
- 为"未设想的程序"设计接口
这不仅是技术架构,更是一种设计哲学——如何在快速演进的 AI 时代,构建能够持续演进而无需推倒重来的系统。
参考资料
官方文档
安全架构
- SAGA: Security Architecture for AI Agents (arXiv)
- HashiCorp Vault: AI Agent Authentication
- MCP Security Best Practices
Context Engineering
- Anthropic: Effective Context Engineering for AI Agents
- LangChain: Context Engineering for Agents
- JetBrains Research: Smarter Context Management
性能优化
架构对比
- OpenAI: A Practical Guide to Building Agents
- LangChain: Choosing Multi-Agent Architecture
- Levels of Autonomy for AI Agents (arXiv) - L1-L5 自主性级别
- AutoGPT Architecture Explained
- BabyAGI: Deep Dive
- Pi: The Minimal Agent Within OpenClaw - Armin Ronacher 对 Pi 极简 Agent 的深度介绍
- Pi Agent GitHub (pi-mono) - Pi Agent 源码仓库
- Claude Code as Harness - Claude Code 架构详解
- TerminalBench-2 Benchmark - Meta-Harness 基准测试结果
附录:原文翻译
以下是对 Anthropic 官方博客文章 Scaling Managed Agents: Decoupling the brain from the hands 的完整翻译。
扩展托管代理:解耦大脑与双手
Engineering at Anthropic
Harness(驾驭层)编码了关于 Claude 自身能力的假设,而这些假设会随着模型改进而过时。Managed Agents——我们面向长周期代理工作的托管服务——围绕稳定的接口构建,即使 harness 改变,接口依然保持稳定。
按照我们的文档开始使用 Claude Managed Agents。
工程博客的一个持续话题是如何构建有效的代理以及为长时间运行的工作设计 harness。这些工作的一个共同点是:harness 编码了关于 Claude 自身无法完成之事的假设。然而,这些假设需要不断被质疑,因为它们可能随着模型改进而过时。
举一个例子,在之前的工作中,我们发现 Claude Sonnet 4.5 在感知到上下文限制接近时会过早结束任务——这种行为有时被称为"上下文焦虑"(context anxiety)。我们通过在 harness 中添加上下文重置来解决这个问题。但当我们用同样的 harness 运行 Claude Opus 4.5 时,发现这种行为已经消失了。重置逻辑变成了死代码。
我们预计 harness 会持续演进。因此我们构建了 Managed Agents:Claude Platform 中的托管服务,通过一小组旨在超越任何特定实现(包括我们今天运行的实现)的接口,代表你运行长周期代理。
构建 Managed Agents 意味着解决计算机科学中的一个老问题:如何为"尚未设想的程序"设计系统。几十年前,操作系统通过将硬件虚拟化为抽象——进程、文件——解决了这个问题,这些抽象足够通用,可以支持当时还不存在的程序。抽象比硬件更持久。read() 命令不关心它访问的是 1970 年代的磁盘组还是现代 SSD。上层的抽象保持稳定,而下层的实现自由变化。
Managed Agents 遵循同样的模式。我们将代理的组件虚拟化:session(所发生一切的追加式日志)、harness(调用 Claude 并将 Claude 的工具调用路由到相关基础设施的循环)、以及 sandbox(Claude 可以运行代码和编辑文件的执行环境)。这允许每个组件的实现被替换,而不会干扰其他组件。我们对这些接口的形状有明确看法,但对它们背后运行的内容不设限。
不要养宠物
我们最初将所有代理组件放入单个容器中,这意味着 session、agent harness 和 sandbox 都共享一个环境。这种方法有好处,包括文件编辑是直接的系统调用,没有服务边界需要设计。
但通过将所有东西耦合到一个容器中,我们遇到了一个老的基础设施问题:我们养了一只宠物(pet)。在 pets-vs-cattle(宠物 vs 家畜)的类比中,宠物是一个命名的、精心照料的个体,你承受不起失去它;而家畜是可互换的。在我们的案例中,服务器成了那只宠物;如果容器失败,session 就丢失了。如果容器无响应,我们必须护理它恢复健康。
护理容器意味着调试无响应的卡住 session。我们唯一的窗口是 WebSocket 事件流,但它无法告诉我们失败发生在哪里,这意味着 harness 中的 bug、事件流中的丢包、或容器下线都呈现相同的症状。要弄清楚出了什么问题,工程师必须在容器内打开 shell,但因为那个容器通常也持有用户数据,这种方法本质上意味着我们缺乏调试能力。
第二个问题是,harness 假设 Claude 处理的任何东西都与它在同一个容器中。当客户要求我们将 Claude 连接到他们的虚拟私有云时,他们要么必须将他们的网络与我们对接,要么在他们自己的环境中运行我们的 harness。一个植入 harness 的假设在我们想要将其连接到不同基础设施时变成了问题。
解耦大脑与双手
我们找到的解决方案是将我们视为"大脑"的东西(Claude 及其 harness)与"双手"(执行操作的 sandbox 和工具)以及"session"(session 事件日志)解耦。每一个都成为一个对其他组件做出很少假设的接口,每一个都可以独立失败或被替换。
Harness 离开容器。
将大脑与双手解耦意味着 harness 不再驻留在容器内。它像调用任何其他工具一样调用容器:execute(name, input) → string。容器变成了家畜。如果容器死亡,harness 将失败作为工具调用错误捕获并传回给 Claude。如果 Claude 决定重试,一个新容器可以用标准配方重新初始化:provision({resources})。我们不再需要护理失败的容器恢复健康。
从 harness 故障中恢复。
Harness 也变成了家畜。因为 session 日志位于 harness 之外,harness 中不需要任何东西在崩溃后幸存。当一个失败时,一个新的可以用 wake(sessionId) 重启,使用 getSession(id) 取回事件日志,并从最后一个事件恢复。在代理循环期间,harness 使用 emitEvent(id, event) 写入 session,以保持事件的持久记录。
安全边界。
在耦合设计中,Claude 生成的任何不可信代码都在与凭证相同的容器中运行——所以提示注入只需说服 Claude 读取自己的环境变量。一旦攻击者获得这些令牌,他们可以生成新的、无限制的 session 并委托工作给它们。窄范围授权是一个明显的缓解措施,但这编码了一个关于 Claude 无法用有限令牌做什么的假设——而 Claude 正变得越来越聪明。结构性的修复是确保令牌永远无法从 Claude 生成代码运行的 sandbox 中访问。
我们使用两种模式来确保这一点。认证可以与资源捆绑或保存在 sandbox 之外的 vault 中。对于 Git,我们在 sandbox 初始化期间使用每个仓库的访问令牌克隆仓库,并将其连接到本地 git remote。Git push 和 pull 从 sandbox 内部工作,而 agent 永远不会处理令牌本身。对于自定义工具,我们支持 MCP 并将 OAuth 令牌存储在安全 vault 中。Claude 通过专用代理调用 MCP 工具;这个代理接收与 session 关联的令牌。然后代理可以从 vault 获取相应的凭证并对外部服务进行调用。Harness 永远不会被告知任何凭证。
Session 不是 Claude 的上下文窗口
长周期任务经常超过 Claude 上下文窗口的长度,解决这个问题的标准方法都涉及关于保留什么内容的不可逆决定。我们在之前关于上下文工程的工作中探讨了这些技术。例如,压缩(compaction)让 Claude 保存其上下文窗口的摘要,记忆工具让 Claude 将上下文写入文件,支持跨 session 学习。这可以与上下文修剪配对,选择性地移除旧工具结果或思考块等 token。
但选择性保留或丢弃上下文的不可逆决定可能导致失败。很难知道未来的轮次会需要哪些 token。如果消息通过压缩步骤转换,harness 会从 Claude 的上下文窗口中移除压缩的消息,这些只有被存储才能恢复。之前的工作探索了通过将上下文存储为上下文窗口之外的对象来解决这个问题。例如,上下文可以是 REPL 中的一个对象,LLM 通过编写代码来过滤或切片它,以编程方式访问。
在 Managed Agents 中,session 提供同样的好处,作为一个存在于 Claude 上下文窗口之外的上下文对象。但不是存储在 sandbox 或 REPL 内,上下文持久存储在 session 日志中。接口 getEvents() 允许大脑通过选择事件流的位置切片来查询上下文。该接口可以灵活使用,允许大脑从上次停止阅读的地方继续、在特定时刻之前回退几个事件以查看过程,或在特定操作之前重新阅读上下文。
任何获取的事件也可以在传递给 Claude 上下文窗口之前在 harness 中转换。这些转换可以是 harness 编码的任何内容,包括上下文组织以实现高提示缓存命中率和上下文工程。我们将 session 中可恢复的上下文存储和 harness 中任意上下文管理的关注点分离,因为我们无法预测未来模型需要什么特定的上下文工程。接口将上下文管理推入 harness,只保证 session 是持久且可供查询的。
多个大脑,多双手
多个大脑。
将大脑与双手解耦解决了我们最早的客户抱怨之一。当团队希望 Claude 在他们自己的 VPC 中处理资源时,唯一的路径是将他们的网络与我们对接,因为持有 harness 的容器假设每个资源都在它旁边。一旦 harness 不再在容器中,那个假设就消失了。同样的变化带来了性能回报。当我们最初将大脑放在容器中时,这意味着多个大脑需要同样多的容器。对于每个大脑,推理必须等到该容器被配置;每个 session 都要预先支付完整的容器设置成本。每个 session,即使是那些永远不会触及 sandbox 的 session,都必须克隆仓库、启动进程、从我们的服务器获取待处理事件。
那个死时间用首 token 时间(TTFT)表示,它衡量一个 session 在接受工作和产生第一个响应 token 之间等待多长时间。TTFT 是用户最强烈感受到的延迟。
将大脑与双手解耦意味着容器只在大脑通过工具调用 execute(name, input) → string 需要它们时才被配置。所以一个不需要立即容器的 session 不必等待。推理可以在编排层从 session 日志拉取待处理事件后立即开始。使用这个架构,我们的 p50 TTFT 下降了约 60%,p95 下降了超过 90%。扩展到多个大脑只是意味着启动多个无状态 harness,并只在需要时连接到双手。
多双手。
我们也希望能够将每个大脑连接到多双手。在实践中,这意味着 Claude 必须推理多个执行环境并决定将工作发送到哪里——一个比在单个 shell 中操作更难的认知任务。我们从单个容器中的大脑开始,因为早期模型没有能力做到这一点。随着智能扩展,单个容器变成了限制:当那个容器失败时,我们失去了大脑正在接触的每只手的状态。
将大脑与双手解耦使每只手都成为一个工具,execute(name, input) → string:一个名称和输入进去,一个字符串返回。该接口支持任何自定义工具、任何 MCP 服务器和我们的自有工具。Harness 不知道 sandbox 是容器、手机还是 Pokémon 模拟器。而且因为没有手与任何大脑耦合,大脑可以互相传递手。
结论
我们面临的挑战是一个老问题:如何为"尚未设想的程序"设计系统。操作系统通过将硬件虚拟化为足够通用以支持尚不存在的程序的抽象,持续了几十年。通过 Managed Agents,我们旨在设计一个能容纳 Claude 周围未来 harness、sandbox 或其他组件的系统。
Managed Agents 是同样精神下的 meta-harness,对 Claude 未来需要的特定 harness 不设限。相反,它是一个具有通用接口的系统,允许许多不同的 harness。例如,Claude Code 是一个优秀的 harness,我们在各种任务中广泛使用。我们也展示了任务特定的 agent harness 在狭窄领域表现出色。Managed Agents 可以容纳其中任何一种,随着时间的推移匹配 Claude 的智能。
Meta-harness 设计意味着对 Claude 周围的接口有明确看法:我们期望 Claude 需要操作状态(session)和执行计算(sandbox)的能力。我们也期望 Claude 需要扩展到多个大脑和多双手的能力。我们设计这些接口以便它们可以在长时间范围内可靠安全地运行。但我们对 Claude 需要的大脑或手的数量或位置不做假设。
致谢
由 Lance Martin、Gabe Cemaj 和 Michael Cohen 撰写。感谢 Nodir Turakulov 和 Jeremy Fox 就这些话题进行的有益讨论。特别感谢 Agents API 团队和 Jake Eaton 的贡献。
Q&A:深度问题解答
以下是对原文核心概念的深度探讨,帮助读者更好地理解 Managed Agents 的设计哲学。
Q1:Harness 本质上是一个大循环,Agent 本身也是一个大循环。那么它与 orchestration 有何区别?
答案:是的,但层次不同。
1 | |
关键区别:
| 概念 | 定义 | 职责 | 例子 |
|---|---|---|---|
| Agent | 完整的自主系统 | 目标驱动的任务执行 | Devin, Claude Code |
| Harness | Agent 的"骨架" | 调用模型 + 路由工具 + 管理状态 | Claude Code 的主循环 |
| Orchestration | 多组件协调 | 工作流编排、任务调度 | LangGraph, Airflow |
Orchestration vs Harness 的本质区别:
-
Orchestration(编排):
- 静态规则驱动:工作流是预定义的
- 确定性路由:A → B → C,路径固定
- 无智能决策:不涉及 LLM 推理
- 例如:Airflow DAG、Kubernetes Job 依赖
-
Harness(驾驭层):
- 动态模型驱动:每步由 LLM 决定
- 非确定性路由:根据 LLM 输出动态选择
- 智能决策:模型决定下一步做什么
- 例如:Claude Code 的主循环
代码示例对比:
1 | |
Q2:所有接口背后资源的调用方式是否统一为 execute(name, input) → string?
答案:是的,这是 Anthropic 的核心设计哲学——统一接口。
三大核心接口:
1 | |
为什么是 execute(name, input) → string?
这是从 Unix 哲学中学到的教训——简单、通用、可组合:
1 | |
这样的好处:
-
Harness 不需要知道底层实现:
1
2
3
4# Harness 不知道 sandbox 是什么
result = execute("some_tool", {"input": "data"})
# 可能是 Docker 容器、可能是 gVisor、可能是 Firecracker MicroVM
# 可能是本地进程、可能是远程 API、可能是手机 -
新工具零成本接入:
1
2# 添加新工具不需要改 Harness
execute("pokemon_emulator", {"button": "A"}) → "Pikachu used Thunderbolt!" -
失败处理统一:
1
2
3
4
5try:
result = execute(name, input)
except ToolError as e:
# 所有工具失败处理逻辑相同
claude.handle_error(e)
Q3:Memory 是否应当作为 Tool 存在?为何它与 Tool 不处于同一生态位?
答案:这是一个深刻的架构问题。Memory 确实可以是 Tool,但在 Managed Agents 架构中,它被提升到了"一等公民"。
两种设计哲学对比:
1 | |
为什么 Session(Memory)要独立?
-
Context Window 外部存储:
1
2
3
4
5
6
7
8
9# Memory 作为 Tool(消耗 context)
tool_call("memory_load", {"query": "之前的决策"})
# Claude 需要用 token 来"请求"访问自己的记忆
# 结果:浪费 token,增加延迟
# Session 作为一等公民(不消耗 context)
events = session.getEvents(slice="last_10")
harness.inject_context(events) # 直接注入,不经过 Claude 请求
# Harness 决定给 Claude 什么上下文 -
Harness 可做智能压缩:
1
2
3
4
5
6
7# Tool 模式:Claude 自己管理 memory
# 无法在 Claude 不知情的情况下压缩
# Session 模式:Harness 可以智能压缩
raw_events = session.getEvents() # 100,000 tokens
compressed = harness.compress(raw_events) # 2,000 tokens
claude_context = compressed # Claude 只看到压缩后的 -
失败恢复需要外部存储:
1
2
3
4# Harness 崩溃后恢复
new_harness = Harness()
new_harness.wake(session_id) # 从 Session 恢复
# 如果 Memory 是 Tool,Harness 崩溃就丢掉了"如何访问 Memory"的能力
结论:Managed Agents 的设计是让 Session 成为 “Context 的持久化层”,而 Tool 是 “Action 的执行层”,两者职责不同,不应混淆。
深入分析:Token 消耗的本质差异
这里有一个容易被忽略但极其重要的经济学差异:
Memory Tools 消耗 token:
1 | |
一等公民 Memory(Session)不消耗额外 token:
1 | |
核心区别:Memory Tool 模式下,Claude 需要花费 token 来"请求"访问自己的记忆——这就像你每次想回忆昨天吃了什么,都要先写一封信给自己的大脑,然后等回信。而 Session 模式下,Harness 直接把相关记忆"塞进"Claude 的工作记忆中,Claude 甚至不知道这个过程发生了。
延伸思考:所有 Tool 都能往"不消耗 token"方向优化吗?
理论上可以,但实践中大多数 Tool 做不到。 原因在于调用意图的可预测性:
| Tool 类型 | 调用意图可预测性 | 能否提升为一等公民 | 原因 |
|---|---|---|---|
| Memory | ✅ 高度可预测 | ✅ 可以 | Harness 知道什么时候该注入上下文(每轮开始时) |
| Compaction | ✅ 高度可预测 | ✅ 可以 | Harness 知道什么时候该压缩(context 达到阈值时) |
| bash/shell | ❌ 完全不可预测 | ❌ 不行 | 只有 Claude 知道它想执行什么命令 |
| file_read | ❌ 不可预测 | ❌ 不行 | 只有 Claude 知道它想读哪个文件 |
| web_search | ❌ 不可预测 | ❌ 不行 | 只有 Claude 知道它想搜什么 |
| git push | ⚠️ 部分可预测 | ⚠️ 有限度 | 可以自动化某些 git 操作,但分支选择等仍需 Claude 决策 |
本质规律:只有那些调用模式可被 Harness 预测和代理的 Tool,才能被提升为"不消耗 token"的一等公民。大多数 Tool 的调用意图只存在于 Claude 的推理过程中,Harness 无法替代 Claude 做出"现在该调用什么工具、传什么参数"的决策——这正是 tool_call token 存在的意义。
换言之:tool_call token 的本质是"意图表达的成本"。Memory 之所以能省掉这个成本,是因为"什么时候需要记忆"这个意图可以被 Harness 代为表达。而"什么时候需要执行 bash 命令"这个意图,只有 Claude 自己知道。
Q4:"但这编码了一个关于 Claude 无法用有限令牌做什么的假设——而 Claude 正变得越来越聪明。结构性的修复是确保令牌永远无法从 Claude 生成代码运行的 sandbox 中访问。"如何理解该论述?请结合实例阐释。
答案:这是关于"窄范围令牌"防御被智能模型绕过的安全洞察。
场景举例:
1 | |
结构性修复:
1 | |
Q5:"对于 Git,我们在 sandbox 初始化期间使用每个仓库的访问令牌克隆仓库,并将其连接到本地 git remote。"如何理解该论述?请结合实例阐释。
答案:这是"凭证预注入"模式的具体实现。
完整流程示例:
1 | |
传统格式: https://username:password@github.com/user/repo.git
PAT 格式: https://ghp_abc123@github.com/user/repo.git
(GitHub 允许 token 直接作为"用户名",密码留空)
完整 PAT: https://x-access-token:ghp_abc123@github.com/user/repo.git
(GitHub App token 的标准格式)
1 | |
为什么用"每个仓库的 Token"而不是"用户全局 Token"?
1 | |
Q6:"在 Managed Agents 中,session 提供同样的好处,作为一个存在于 Claude 上下文窗口之外的上下文对象。但不是存储在 sandbox 或 REPL 内,上下文持久存储在 session 日志中。"如何理解该论述?请结合实例阐释。此处的 REPL 具体指代什么?
答案:这涉及到三种上下文管理模式的对比。
REPL 指的是什么?
REPL = Read-Eval-Print Loop,这里特指 “Claude 交互式编码环境”,比如:
1 | |
三种上下文管理模式对比:
1 | |
如何过滤或切片 Session Log?
1 | |
Q7:"推理可以在编排层从 session 日志拉取待处理事件后立即开始。使用这个架构,我们的 p50 TTFT 下降了约 60%,p95 下降了超过 90%。"该架构为何能够实现如此显著的性能提升?
答案:核心是"延迟容器创建"和"无状态 Harness"。
TTFT 优化原理:
1 | |
关键优化点:
-
延迟容器创建(Lazy Provisioning):
- 旧架构:容器先于推理(必须等待)
- 新架构:容器按需创建(推理和容器启动并行)
-
无状态 Harness 预热池:
- 类似数据库连接池,Harness 可以大量预创建
- 新请求立即分配空闲 Harness,毫秒级响应
-
多个 Brain 并行扩展:
- 旧架构:100 个请求 → 100 个容器 → 巨大资源开销
- 新架构:100 个请求 → 100 个轻量 Harness + 按需 Sandbox
p95 TTFT 下降 90% 的原因:
p95(第95百分位)代表"最慢的5%请求"。旧架构中,这些请求可能因为:
- 容器镜像不在本地缓存
- 资源竞争导致容器启动排队
- 仓库克隆慢(大仓库)
新架构中,这些问题都被消除:
- Harness 不需要镜像
- Harness 轻量,可以大量预创建
- 仓库克隆只在需要时才发生,且不阻塞推理