
推荐系统相关
新闻的推荐系统是为了给信息流的用户推荐资讯 feed。接口返回的信息不一定会被外显曝光。
在瀑布流式的外显曝光场景下,重排能够减少用户的疲劳度。
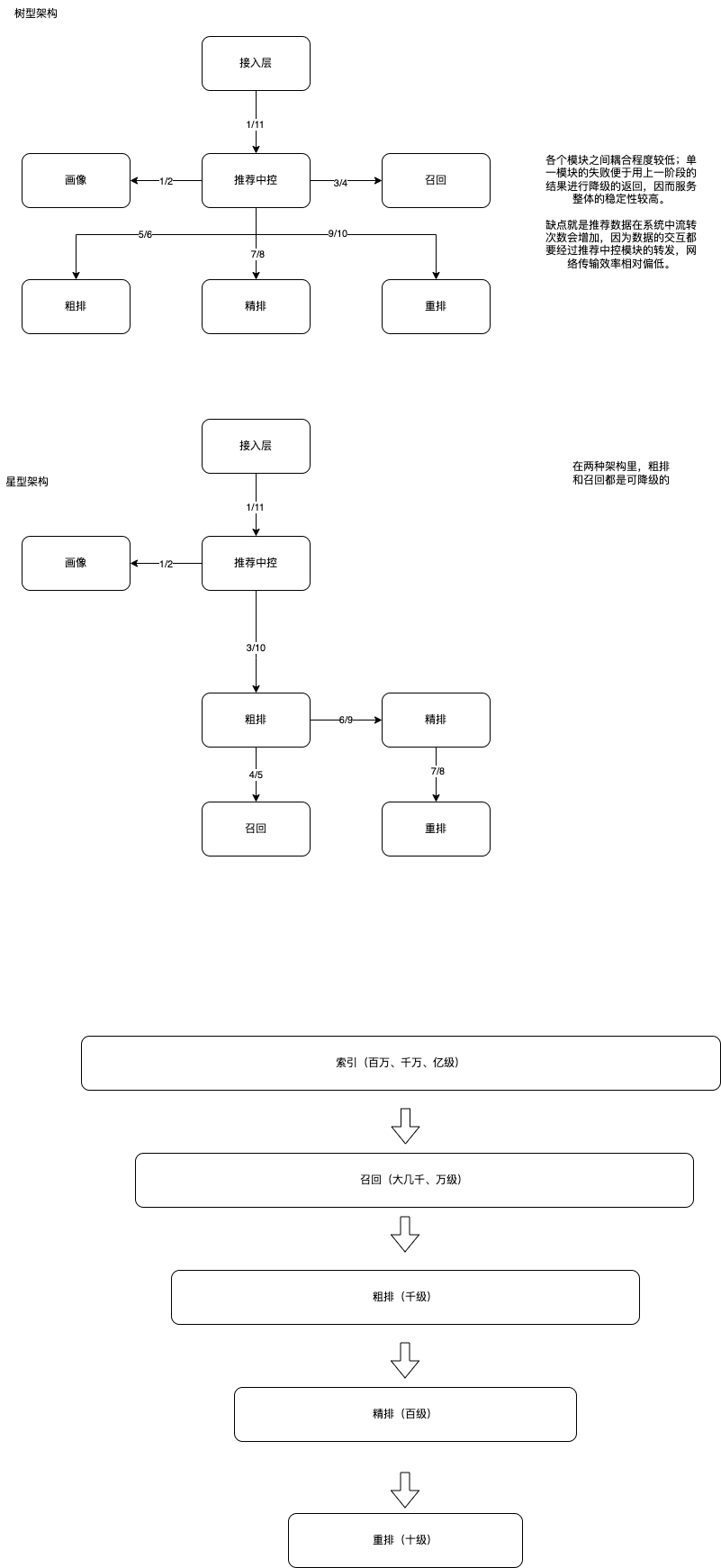
这就涉及到推荐系统的设计,流量要经过什么样的链路呢?
接入层、推荐中控、画像、召回、粗排、精排、重排。这些系统会形成星型架构和树形架构。
不同的架构之间有一个典型的优缺点需要取舍:链路长度会影响网络传输的最终效率,也会影响推荐系统的性能。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-06-01
交易系统模型设计
交易系统.xmind
2021-05-27
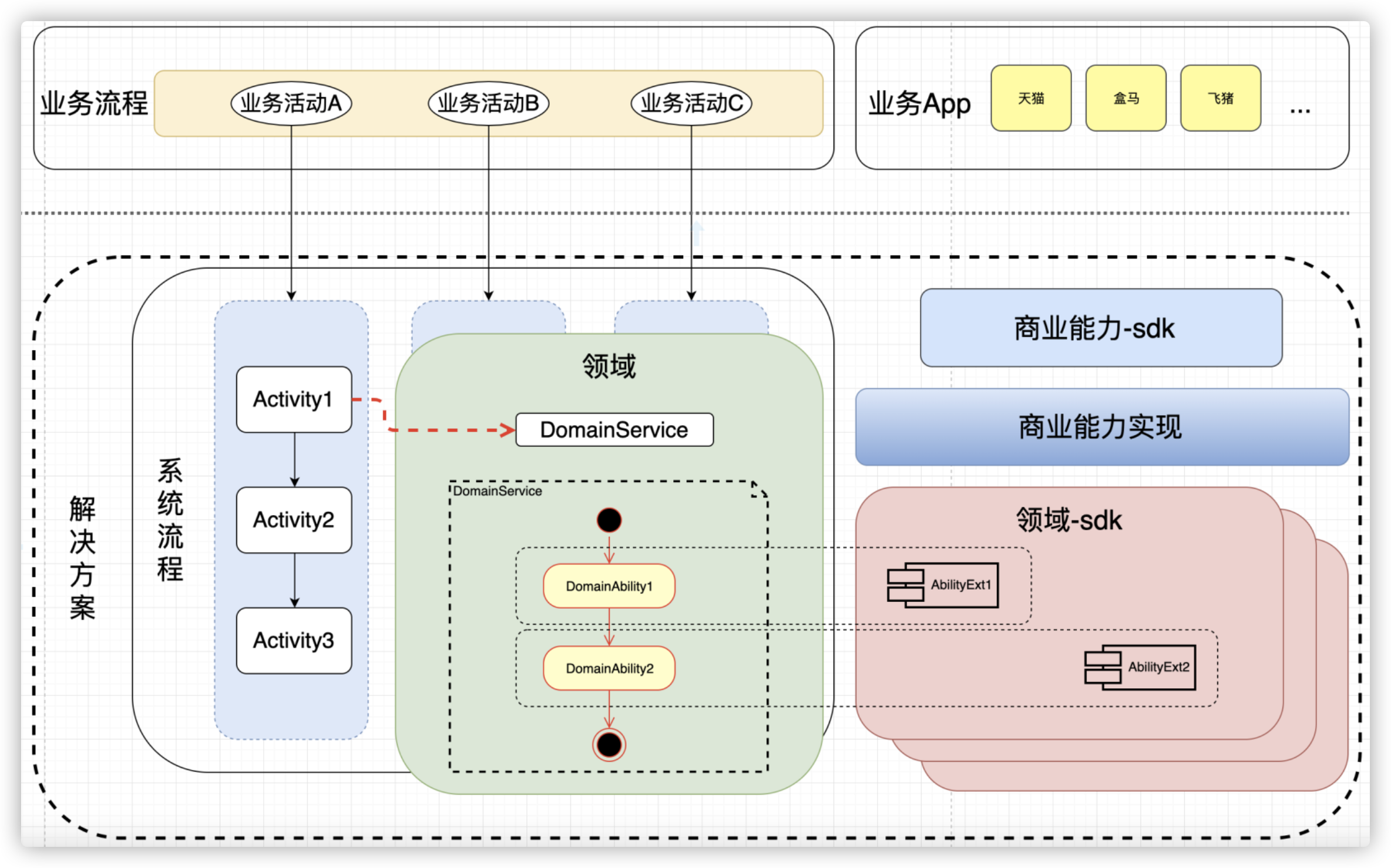
插件化架构
为什么要实现插件化架构 业务和平台要解耦。业务和平台都是多对多的关系。全链路里既有业务,也有平台。大家应该如何 talk by interface。我们看待复杂组织的业务流程,要线性看,看到很多节点;也要分层看,看到复合的层次。在这种情况下,上层架构域和下层架构域之间怎么实现复杂度的管理? 如果我们需要构建大规模的泛交易平台,我们需要靠插件化架构把我们的系统组装起来。 插件化架构通常需要一个 runtime 层(或者 boot 层)、core 层。 从业务视角来看,要解决多团队协同的问题 因为多个业务域/团队没有把能力用统一的方式透出,所以没有人能够知道统一的技术能力应该怎么串联。进行全链路沟通需要大量的沟通对齐工作。 从业务视角来看,复杂性业务要素包含本业务用例里的各种模型。 从平台视角来看,要解决复杂性管理问题 平台要支撑多种业务,业务的复杂性、差异性,以及众多业务需求不确定性,在各平台内部如何管理和支撑?简单的 if-else 不易于管理,确保对业务的支撑能力不相互影响。隔离是最好的管理手法。 从平台视角来看,复杂性业务要素包含本域内标准系统用例里的各种模型。 同一个模型,...

2021-08-25
基本业务架构设计方法
如何实现自己的 validation 123456789101112131415161718192021222324252627282930313233343536373839// 抛出异常private void validateParam(Map<String, String> paramValues) { boolean validate = MapUtils.isEmpty(paramValues) || !paramValues.containsKey(ParamConstant.CUSTOMER_N0) || StringUtils.isEmpty(paramValues.get(ParamConstant.CUSTOMER_N0)); if (validate) { throw new DataBusinessException(ResultCodeEnum.PARAM_NULL); }
...
2021-08-18
如何写系统规划
列出背景 列出现状。 列出当前组织的 okr,分析机会和挑战。 将当前系统的视图勾勒出来,要能理解信息流和资金流。 列出痛点,分析需要实现的技术能力。 对标 对标其他团队的成功经验。 分析背景和成功原理。 要有架构图。 解决方案 要有目标架构图 有问题拆解:什么服务,是什么问题域的解空间,拥有什么能力,建设路径分几期,需要多少人力成本。 全团队分工: 本团队产品怎么分工 本团队后端怎么分工 本团队前端怎么分工 本团队数据怎么分工 本团队算法怎么分工 其他团队怎么分工 里程碑 按照绝对时间拆解 按照任务事件拆解 如何画简单的架构图 水平分层极其重要,每一层左边在层次里会有层次说明。 要用圆角都用圆角,要用直角都用直角。 重点:要填满整个空间: 深底色配白字。 模块之间的应该要直,不然应该优美、松弛。 图像应该紧凑,不留缝隙。 越处于背景之中,颜色越浅。 有时候,利用立体图形是好的。 要有阴影。 要玻璃化。
2022-01-17
如何成为一名优秀的架构师
成为一个架构师:为了这一刻,你准备了多久? 架构师的关注点:顶层设计、长期视角。 寿命:数据 > 代码(特指业务逻辑)> 技术(特指业务逻辑的载体) 不是传道受业,而是观点分享。 架构师的几种 profile:有架构能力、以架构为生也是一种架构师。 长期战略:对于任何一家公司,架构设计一定是必要的,而且需要自行解决。架构师的职责是保证组织拥有正确的设计,控制复杂度。 架构师的关键特质: 目标正确:限制条件和目标价值产生理解偏差。是架构师最常见的问题。 能力满足:为组织带来更好的外部适应性。 持续减熵:好架构等于发现、规划和演化。 思考深度和实战经验最重要:这是任何的书本都不能带给我们的。包容、求真、良知、勇气。 有没有德?考虑组织长期利益(基于良知做判断)。 有没有勇气?承担责任,决定命运。 有没有眼光?是否擅于思考? 独立、理性、有深度的思考。长期感召力,来自于良知、成功、经验和勇气。 从复盘中学习。 郭东白.pdf
2022-01-07
如何写复杂业务系统
引言 本文只是一家之言。 本文是一系列文章的缩略版本(完整版只写了个开头),尽量只讲具体的东西,如果有东西太干了,没有具体的“体感”,是作者的责任。 不喜欢看纯理论分析的可以跳到单一系统层次和模块设计(大多数人可能更加关注这一节,其实前面的部分更重要)。 几个很干的原则 解决复杂问题要用高级思维,不要用低级思维。 蚂蚁/ebay 等若干家企业架构师四大原则 - 听过的可以往下跳: 分治(其他所有原则都是从分治里衍生的) 分层 抽象 演化 solid 5 原则很重要很重要 -很多人读过,很多人可能没有读过,温故知新很重要。 注重过程质量,拿到结果质量。 业务系统为什么难写? 纯粹的业务驱动:技术的输入和决策完全来源于业务同事,甚至只受业务摆布的团队,架构容易混乱 业务又不懂架构、业务又不懂功能点罗列的合理性,业务只会往技术团队身上扔需求。 怎么把需求和实现分门别类是技术自己的事情。 但技术人员如果一直都很忙,没有自己的空闲时间或者对设计洁癖的坚持,慢慢地就会养成“把需求翻译成代码,然后往老的系统里面扔”(混乱根源 1)的坏习惯- 问题:翻译只是普通的低级思维,不能解决很复杂...




