
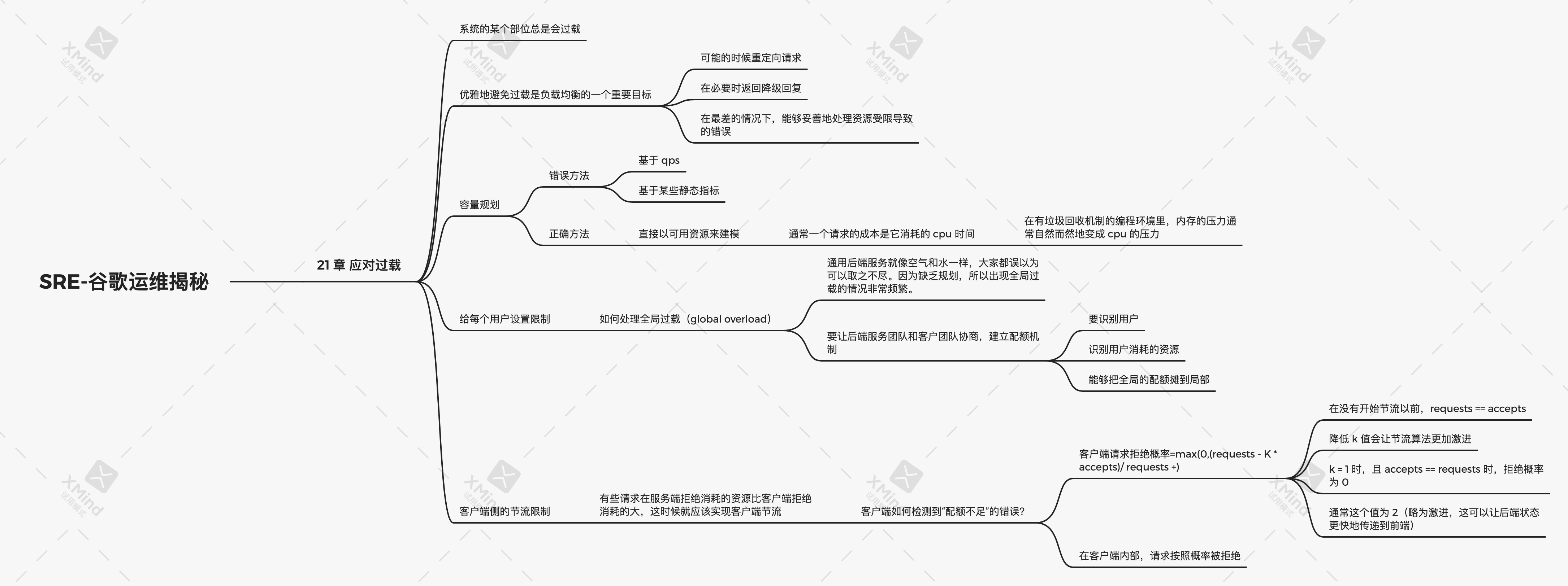
SRE-谷歌运维揭秘
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2026-05-14
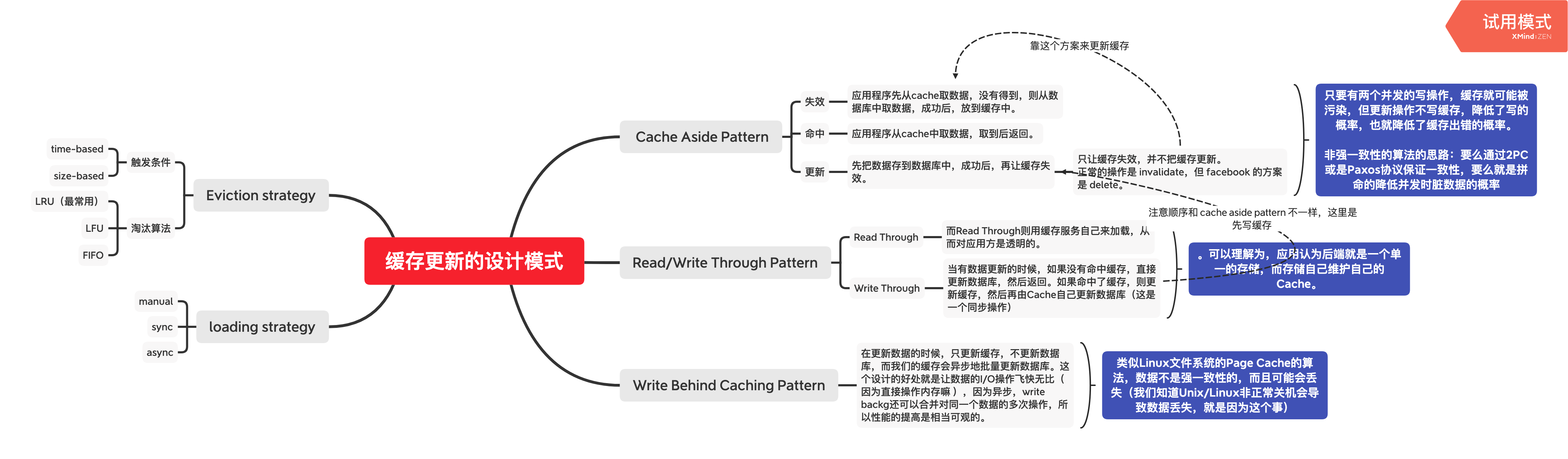
缓存系统设计全景——从原理到生产的完整指南
缓存是提升系统性能的第一利器,但也是引发故障的第一杀手。从缓存穿透、击穿、雪崩三大经典问题,到多级缓存架构、分布式锁、热点 Key 治理,缓存设计几乎贯穿后端工程师的整个职业生涯。 本文将系统性地剖析缓存系统的设计原则与生产实践,从单机进程内缓存到分布式 Redis 集群,从理论模型到可落地的代码方案,构建一套完整的缓存知识体系。 mindmap root((缓存架构)) 何时使用 读多写少 热点集中 可容忍最终一致性 缓存层次 近端缓存 Guava Caffeine EhCache 远端缓存 Redis Memcached 核心挑战 更新策略 Cache Aside Read Through Write Through Write Behind 一致性保障 故障防护 击穿防护 雪崩防...

2026-07-13
性能诊断:Spark UI、Event Log 与调优思路
上一篇解决了动态资源分配和调度策略。这一篇进入性能诊断——当 Spark 作业慢了,怎么找到瓶颈。 性能调优的第一步不是改配置,是定位问题。Spark UI 提供了五个关键页面(Jobs、Stages、Storage、Environment、Executors),每个页面指向不同类型的性能问题。Event Log 提供了离线分析的完整数据。 本文只抓一个问题:面对一个慢作业,如何从 Spark UI 的指标出发,沿着诊断路径找到根因。 Spark UI 五个页面 1234567891011121314151617181920212223Jobs 页面 → 每个 Action 对应一个 Job → 关注: Job Duration、Failed Tasks 数量 → 入口: 找到最慢的 Job,点击进入 Stage 详情Stages 页面 → 每个 Stage 的 Task 统计 → 关注: Task Duration 分布、Shuffle Read/Write、GC Time → 核心: 这里是定位性能问题的主战场Storage 页面 → 缓存的 RDD/DataF...

2026-06-20
生产运维:集群扩缩、监控指标与故障排查
上一篇解决了安全体系的认证、授权与加密。这一篇进入生产运维。 生产运维容易被理解为"改配置 + 重启"。更准确的说法是:Kafka 集群的运维本质上是对分布式日志的分区所有权、副本状态和元数据的受控迁移,每一步操作都在改变哪些 broker 持有哪些 partition 的哪个角色。 本文只抓三个问题:如何安全地扩缩 broker,应该盯哪些 JMX 指标,以及遇到常见故障时从哪里开始排查。 集群扩缩容模型 Kafka 集群的 broker 状态可以用一个简化模型描述: 123456789101112当前集群: [broker-0, broker-1, broker-2]partition 分布: topic-A-0 -> leader=0, follower=[1,2] topic-A-1 -> leader=1, follower=[0,2]加 broker-3 后: broker-3 加入集群,无 partition -> 手动触发 partition reassignment topic-A-0 -> leader=0...

2026-05-24
OOM Killer:内核什么时候决定杀进程
上一篇讲了 memcg 如何把全局内存资源划分成层级预算。当预算用尽且回收无力时,最后一道防线是 OOM killer——通过终止进程来释放内存。这不是内存管理的常规路径,而是所有正常手段都失败后的兜底。 核心问题可以压成一句话: OOM killer 是多轮分配、回收、压缩、写回、swap 都无法满足请求后的兜底路径,不是内存管理的常规目标。 问题从哪里来 内存分配失败的处理有一个基本问题:内核不能简单地对调用者返回"分配失败"。很多内核代码路径不检查分配失败(GFP_KERNEL 分配假设不会失败),即使返回错误,用户空间进程通常也没有合理的 fallback 逻辑。 所以内核的策略是:在返回失败之前,尽可能通过各种手段释放内存。如果所有手段都用尽仍然无法满足分配请求,最后才走 OOM kill——选择一个进程杀掉以释放它占用的内存。 到达 OOM kill 之前的完整路径: 1234567891011121314__alloc_pages() 分配请求 → 检查 zone 水位线:有空闲页? → 成功返回 → 唤醒 kswapd 后台回收 →...

2025-07-28
Redis 经典用例全解:从数据结构到系统设计
Redis 最容易被误解成“更快的数据库”。这个理解只对了一小半。Redis 更适合放在系统的热路径上,处理短生命周期状态、派生索引、原子协调、近实时统计和少量高频列表;完整事实仍然应该由数据库、日志或对象存储承载。 系统设计面试里,Redis 的价值也不在命令背诵。更重要的是把业务需求翻译成几个稳定的问题模型: 这份数据是否可以过期 这份数据丢了能否重建 读路径是否远热于写路径 是否需要排序、范围查询、集合运算或原子判断 Redis 故障时,系统还能不能保持核心正确性 答案如果把 Redis 当成事实库,通常会在持久性、审核追溯、深页查询或跨 key 一致性上掉坑。更可靠的边界是:数据库保存事实,Redis 保存热路径和派生状态。 Redis 的系统设计位置 flowchart TD Req["业务需求"] --> Sem["抽象操作语义"] Sem --> DS["选择 Redis 数据结构"] DS --> Key["设计 Key 和分片边界"] ...
2026-06-29
MySQL 经典架构模式:从主从复制到分库分表
MySQL 在绝大多数业务系统中扮演事实源的角色。Redis 和 ES 都是派生存储——数据可以从 MySQL 重建,反过来不行。围绕 MySQL 的架构模式,核心问题始终是三个:怎么扛住读写压力、怎么保证数据不丢、怎么随业务增长水平扩展。 下面整理十个生产环境中反复出现的 MySQL 架构模式。和 ES 架构模式 与 Redis 用例全解 形成三件套:Redis 管热路径和派生状态,ES 管可搜索的派生索引,MySQL 管事实。 模式速查 模式 解决的问题 核心机制 典型场景 主从复制 + 读写分离 读压力分摊 binlog 复制 + 代理层路由 读多写少的业务 半同步复制 + 增强半同步 主从切换时数据不丢 after-sync / after-commit 金融、订单 双主(互为主从) 机房级故障切换 双向复制 + 自增步长错开 同城双活 级联复制 大规模从库扩展 从库的从库 读流量极大的分析场景 分库分表 单库容量和写入瓶颈 水平分片 + 路由中间件 亿级数据量 影子表与 Online DDL 大表结构变更不锁表 pt-osc / gh...




