
数据库容灾体系的演变
什么是容灾
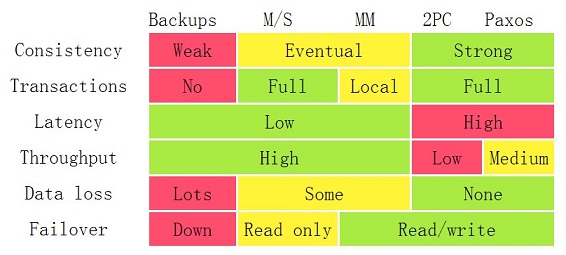
备份的分类
| 备份方式 | 说明 |
|---|---|
| 逻辑备份 | 数据库对象级备份,备份内容是表、索引、存储过程等数据库对象,如MySQL mysqldump、Oracle exp/imp。 |
| 物理备份 | 数据库文件级备份,备份内容是操作系统上数据库文件,如MySQL XtraBackup、Oracle RMAN。 |
| 快照备份 | 基于快照技术获取指定数据集合的一个完全可用拷贝,随后可以选择仅在本机上维护快照,或者对快照进行数据跨机备份,如文件系统Veritas File System,卷管理器Linux LVM,存储子系统NetApp NAS。 |
规划
要结合业务,产生多维立体的解决方案。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-05-20
MyBatis 内部架构深度解析:从 Mapper 方法到 JDBC 执行链
MyBatis 的内部结构并不复杂,但很容易被看散:SqlSession、MapperProxy、MappedStatement、Executor、StatementHandler、TypeHandler、一级缓存、二级缓存、插件链分别出现在不同包里,单看任何一个类都像是局部技巧。把它们放回完整调用链之后,MyBatis 的设计会变得很清楚: MyBatis 的核心不是“把对象自动映射成表”,而是“把 Java 方法稳定地映射到一条可执行的 SQL 描述,再把执行过程拆成可替换的流水线组件”。 本文以 MyBatis 3.5.19 的官方文档与源码 XRef 为基准,重点讨论 MyBatis 运行时内部架构,不展开 MyBatis-Spring 的事务同步、Spring Boot 自动装配,也不讨论 MyBatis-Plus 等增强框架。 总体架构 MyBatis 可以分成两条主线:构建期主线和执行期主线。 构建期负责把 XML、注解、类型别名、类型处理器、插件、缓存配置等材料编译成一个 Configuration 对象。执行期从 SqlSessionFactory 打开 ...
2017-11-15
MariaDB 调优相关
本文主要摘译自这里。 MySQL 曾经有独立的公司。但那间公司后来被 Sun 微系统公司获取了。 Sun 微系统公司又被 Oracle 获取了。原 MySQL 开发者担心 MySQL 成为闭源软件,因此成立了一家SkySQL 公司维护开源的 MySQL 分支–MariaDB。 MariaDB 支持的存储引擎包括: InnoDB/XtraDB 后者是前者的加强版,属于事务性存储引擎,也叫 ACID-compliant(ACID 遵从的)。XtraDB 是 Percona 开发的存储引擎,整体向下兼容。使用普通的 mysqldump 会耗尽 cpu(因为要把数据库转化成正经的 SQL 语句)。而 xtrabackup 在大库上的备份、还原、冗余都表现得更好(因为像 Oracle 一样是二进制备份吗?)。 TokuDB。另一个事务性存储引擎。以高压缩率著称(最高25倍压缩)。适合小空间存储大数据。 MyISAM。MySQL 上最古老的存储引擎。非事务性存储引擎,只支持表级锁,不支持 MVCC。 SphinxSE。非事务性存储引擎。这名字和古希腊猜谜语的怪兽,斯芬克斯一样。本以上是用...
2026-06-01
数据库 Resharding 的在线切换与回滚
Resharding 是分库分表架构绕不过去的难题。系统上线时用 uid % 2 把数据分到两个库,跑了两年发现容量不够,要扩成四个库——uid % 4。这个 % 号一变,大约 75% 的数据需要重新搬家。搬数据本身不难,难的是三件事同时做到:在线搬、搬完瞬间切、切坏了能回滚。 下面从最朴素的双写到 Vitess 的 VReplication,逐一拆解业界主流的 resharding 在线切换方案。核心问题只有三个:数据怎么不丢,流量怎么瞬间切,故障怎么秒级回。 问题的本质:hash mod 变化引发的数据海啸 hash 取模是最常见的分片路由策略。uid % N 的 N 一旦改变,绝大部分数据的归属分片都会变。 以 2 库扩 4 库为例:原先 uid % 2 = 0 的数据全在 A 库,扩容后 uid % 4 把这批数据拆成了 uid % 4 = 0(留 A 库)和 uid % 4 = 2(搬到新 C 库)。B 库的情况类似,一半数据要搬去新 D 库。 12345678910111213扩容前(uid % 2) 扩容后(uid % 4)┌─────────┐ ...
2026-06-29
MySQL 经典架构模式:从主从复制到分库分表
MySQL 在绝大多数业务系统中扮演事实源的角色。Redis 和 ES 都是派生存储——数据可以从 MySQL 重建,反过来不行。围绕 MySQL 的架构模式,核心问题始终是三个:怎么扛住读写压力、怎么保证数据不丢、怎么随业务增长水平扩展。 下面整理十个生产环境中反复出现的 MySQL 架构模式。和 ES 架构模式 与 Redis 用例全解 形成三件套:Redis 管热路径和派生状态,ES 管可搜索的派生索引,MySQL 管事实。 模式速查 模式 解决的问题 核心机制 典型场景 主从复制 + 读写分离 读压力分摊 binlog 复制 + 代理层路由 读多写少的业务 半同步复制 + 增强半同步 主从切换时数据不丢 after-sync / after-commit 金融、订单 双主(互为主从) 机房级故障切换 双向复制 + 自增步长错开 同城双活 级联复制 大规模从库扩展 从库的从库 读流量极大的分析场景 分库分表 单库容量和写入瓶颈 水平分片 + 路由中间件 亿级数据量 影子表与 Online DDL 大表结构变更不锁表 pt-osc / gh...
2021-03-18
MySQL pitfalls 与配置札记(2018-2021 札记整合)
一、SQL 语义陷阱 引号的方言差异 标准的 SQL 中只允许用单引号表达字符串类型。有些 SQL 方言允许使用双引号包裹字符串,如 MySQL,有些则不允许,如 Oracle。 反引号是专门用来表达 identifier 的。 字符串与数字的隐式转换 pitfall Data truncation: Truncated incorrect 不要小看 MySQL,它出 warning 就一定有错误。 不要滥用 MySQL 字符串到decimal,和 decimal 到 string 的转换。这样有时候 MySQL 不只是 warning。 二、存储引擎对比 参考:https://www.zhihu.com/question/20596402 MyISAM 与 InnoDB 的区别 InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一; InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败; InnoDB 是聚集索引,MyISAM ...
2021-03-28
MySQL 存储引擎 InnoDB 技术内幕
这本书的电子版的一个博客。 InnoDB.xmind 前言 MySQL 是处理海量数据(尤其 是OLTP 写入)时仍能获得最佳性能的最佳选择之一,它的 CPU 效率可能其他任何基于磁盘的关系型数据库所不能匹敌的-但它应该能够匹敌 Redis。 Think Different 而不是 Think Differently,这意味着要思考不同的东西,而不只是思考不同的方式。 不要相信网上的传言,去做测试,根据自己的实践做决定。很多伟大的作者写的伟大的书里面,关于性能的说法都来源于他们个人的随身电脑的直观测试。 change buffer 是 inert buffer 的升级版本。 MySQL 体系结构和存储引擎 定义数据库和实例 数据库:物理操作系统文件或其他形式文件类型的集合。 实例:操作系统后台进程(线程和一堆共享内存)。 存储引擎:基于表而不是基于库的,所以一个库可以有不同的表使用不同的存储引擎。 InnoDB 将数据存储在逻辑的表空间中,这个表空间就像黑盒一样。 存储引擎不一定需要事务。比如没有 ETL 的操作,单纯的查询操作不需要考虑并发控制问题,不需要产生一致性视图。...