一个滚动重启的状态保存问题
很多时候滚动重启,都会导致状态丢失。比较好的设计方法是把服务本身设计成无状态的,然后在上游的服务上做好 failover,然后增加 standby server,让 sticky 数据 transmit 到 standby 机器上,让 request 失败以后可以自己由上游重传到 standby server。然后就可以滚动重启了。
这大部分场景下还要考虑幂等的问题。
这就看得出热配置热替换的重要性了。在大多数情况下,除了发布新的 feature 升级以外,都应该尽量用热配置来避免重启。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2021-03-01
HATP 问题
问题定义 AP 的出现 在互联网浪潮出现之前,企业的数据量普遍不大。通常一个单机的数据库就可以保存核心的业务数据。那时候的存储并不需要复杂的架构,所有的线上请求(OLTP, Online Transactional Processing) 和后台分析 (OLAP, Online Analytical Processing) 都跑在同一个数据库实例上。后来业务越来越复杂,数据量越来越大,产生了一个显著问题:单机数据库支持线上的 TP 请求已经非常吃力,没办法再跑比较重的 AP 分析型任务,在这样的大背景下,于是AP开始从TP系统分离,某种程度上,AP是TP的一个分支。 这等于是在存储层做 CQRS 架构设计-另一种方案是在应用层也设计读写分离的架构。 AP 的玩法 在这样的背景下,以 Hadoop 为代表的大数据技术开始蓬勃发展,它用许多相对廉价的 x86 机器构建了一个数据分析平台,用并行的能力破解大数据集的计算问题。 AP 系统的典型技术栈演进: 阶段 代表技术 特点 第一代 Hadoop MapReduce + Hive 批处理,延迟高(分钟到小时级) 第二...

2019-12-29
彩色 UML 建模
理论基础与来源 彩色 UML 建模(也称为四色模型)是由 Peter Coad、Eric Lefebvre 和 Jeff De Luca 在经典著作《Java Modeling in Color with UML》中提出的领域建模方法。该方法通过四种颜色区分不同类型的域对象,帮助开发人员更好地理解和设计业务领域模型。 四色模型的核心思想是将领域对象分为四种架构型(Archetype),每种架构型用不同的颜色表示: 粉色(Moment-Interval):表示业务过程中发生的某个时刻或时段 黄色(Role):表示参与方在特定时刻时段中扮演的角色 绿色(Party-Place-Thing):表示参与方、地点和事物 蓝色(Description):表示描述性信息,通常是可重用的数据 四色模型与 DDD 的关系 四色模型与领域驱动设计(Domain-Driven Design,DDD)有很强的关联性: 关注领域本质:两者都强调深入理解业务领域,建立符合业务语义的模型 限界上下文:四色模型的彩色分类可以帮助识别和定义限界上下文 聚合根:粉色 MI 通常对应聚合根,负责维护业务不变性 ...
2022-01-07
如何写复杂业务系统
引言 本文只是一家之言。 本文是一系列文章的缩略版本(完整版只写了个开头),尽量只讲具体的东西,如果有东西太干了,没有具体的“体感”,是作者的责任。 不喜欢看纯理论分析的可以跳到单一系统层次和模块设计(大多数人可能更加关注这一节,其实前面的部分更重要)。 几个很干的原则 解决复杂问题要用高级思维,不要用低级思维。 蚂蚁/ebay 等若干家企业架构师四大原则 - 听过的可以往下跳: 分治(其他所有原则都是从分治里衍生的) 分层 抽象 演化 solid 5 原则很重要很重要 -很多人读过,很多人可能没有读过,温故知新很重要。 注重过程质量,拿到结果质量。 业务系统为什么难写? 纯粹的业务驱动:技术的输入和决策完全来源于业务同事,甚至只受业务摆布的团队,架构容易混乱 业务又不懂架构、业务又不懂功能点罗列的合理性,业务只会往技术团队身上扔需求。 怎么把需求和实现分门别类是技术自己的事情。 但技术人员如果一直都很忙,没有自己的空闲时间或者对设计洁癖的坚持,慢慢地就会养成“把需求翻译成代码,然后往老的系统里面扔”(混乱根源 1)的坏习惯- 问题:翻译只是普通的低级思维,不能解决很复杂...

2021-08-18
如何写系统规划
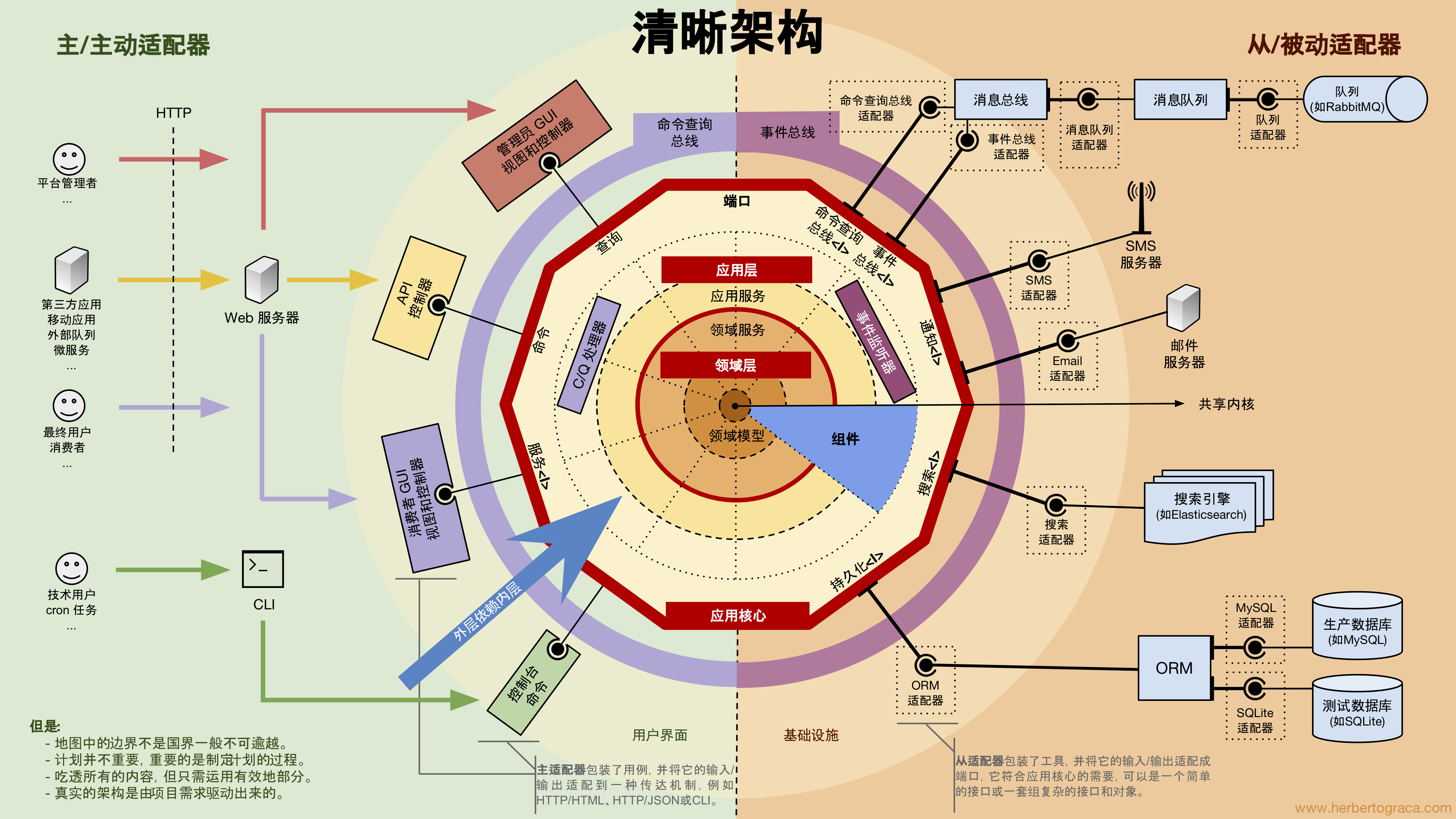
列出背景 列出现状。 列出当前组织的 okr,分析机会和挑战。 将当前系统的视图勾勒出来,要能理解信息流和资金流。 列出痛点,分析需要实现的技术能力。 对标 对标其他团队的成功经验。 分析背景和成功原理。 要有架构图。 解决方案 要有目标架构图 有问题拆解:什么服务,是什么问题域的解空间,拥有什么能力,建设路径分几期,需要多少人力成本。 全团队分工: 本团队产品怎么分工 本团队后端怎么分工 本团队前端怎么分工 本团队数据怎么分工 本团队算法怎么分工 其他团队怎么分工 里程碑 按照绝对时间拆解 按照任务事件拆解 如何画简单的架构图 水平分层极其重要,每一层左边在层次里会有层次说明。 要用圆角都用圆角,要用直角都用直角。 重点:要填满整个空间: 深底色配白字。 模块之间的应该要直,不然应该优美、松弛。 图像应该紧凑,不留缝隙。 越处于背景之中,颜色越浅。 有时候,利用立体图形是好的。 要有阴影。 要玻璃化。
2025-07-15
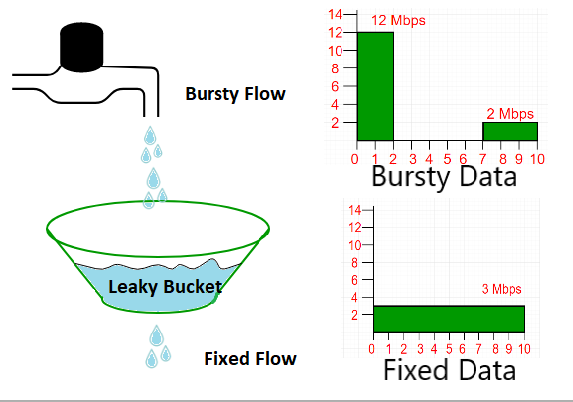
系统的弹性
背景介绍 1999年,Dan Kegel 在互联网上发表了一篇文章,首次将 C10K 问题带入软件工程师的视野。在那个互联网勃兴的年代,计算机的运算处理能力,ISP 能够提供的带宽和网速都还十分有限,用户的数量也很少(那时候一个网站几百个人是很正常的事)。Dan Kegel 却已经敏锐地注意到极端的场景下资源紧张的问题。按照他的观察,某些大型的网络站点需要面对高达10000个客户端的并行请求。以当时的通行系统架构,单机服务器并不足以处理这个这个问题(当时绝大部分系统也没有那么大的流量,所以大部分人也没意识到这个问题)。因此,系统设计者必须为 C10K 问题做好准备。在那篇文章之中, Dan Kegel 提出了使用非阻塞异步 IO 模型,和使用各种内核系统调用黑魔法来提高系统 IO 性能的方式,来提高单机的并行处理能力。不得不说,这篇文章在当时很有先驱意义,它使得大规模网络系统的流量问题浮上了水面,也让人们意识到了系统容量建模和扩容提升性能的重要性。在它的启发下,C10K 问题出现了很多变种,从并发 C10K clients,到并发 C10K connections,到 C10K ...

2020-12-08
活动保障性体系建设和实践的总结
大促规划.xmind 活动的定义和特点 活动具有大并发、高流量的特点,前期充足的准备是活动顺利完成的必要条件。 准备好完备的保证流程,可以为相关人员提供指引。 基本的保障方案 事前:严格按照保障步骤分工执行,活动要报备,核心链路要梳理,梳理完要评估容量和准备,要治理风险,要准备预案,要建设大盘,准备压测和演练预案,要安排值班。 事中:相关责任方(要分技术负责人和运维负责人,召集相关人员,组成稳定性保障小组)监控线上数据,以线上/线下会议、群聊和电话等多个方式参与值班并及时响应异常事件。 事后:组织复盘,总结亮点,指出不足,沉淀经验。 活动报备 要理清活动信息:活动背景、活动时间、用户参与路径、活动链接、活动 玩法、预计UV数、负责人。 核心链路的设计与梳理 核心链路的梳理、设计需和活动保障的几个核心要素相结合,核心要素分为:隔离、限流、容量。 隔离:域名隔离、Nginx集群隔离、核心服务隔离、以及其他一些重要服务的隔离。 限流:前端活动业务限流、Nginx限流(HTTP限流)、服务限流(RPC)等。特别要关注接入层的限流能力和方案。 容量:从域名解析到后端存储的系列容量评...





