

你的答案在你的宇宙里
《瞬息全宇宙》这个电影不如我预期的好,可能是我预期太高了。它用了非常多的符号和镜头切换来合理化逻辑论证的跳脱,这是很多观众不易接纳的(特别是中国观众)。当然它最后讲出来的仍然是好莱坞这些年念兹在兹的人生真谛:不要去思考人生的问题,因为不够好的东西是注定的,好的人生是 you enjoy it 的人生。这也是中国观众早已习以为常的耳边风。所以这个片子自从网飞开片,中国本土观众可以收看以来,在豆瓣的评分一直往下掉,中国人因为离不开这种人生真谛给它打高分,又因为厌倦了这种人生真谛,给不了多么高的分数。 很多人的生存哲学是:我将如何通过摆烂获得peace或者我将如何通过奋斗(struggle)来获得 peace。但我们的人生体验告诉我们,无论哪种方法都不算peace,而且快乐是短暂的,悲伤是长久的。人生绝大部分快乐总是一下子就消散掉了,悲伤对人的消极影响通常是沉浸式的,悲伤甚至可以改变一个人的人格,而快乐永远做不到这一点。人们渴望的快乐是简单纯粹而彻底安全的,人为了获得这一点会拼命需要别人给自己供养安全感,这种安全感就是我们心中的爱。而所有人学会渴求爱的行为模式,都是从家庭的教养中来的。...
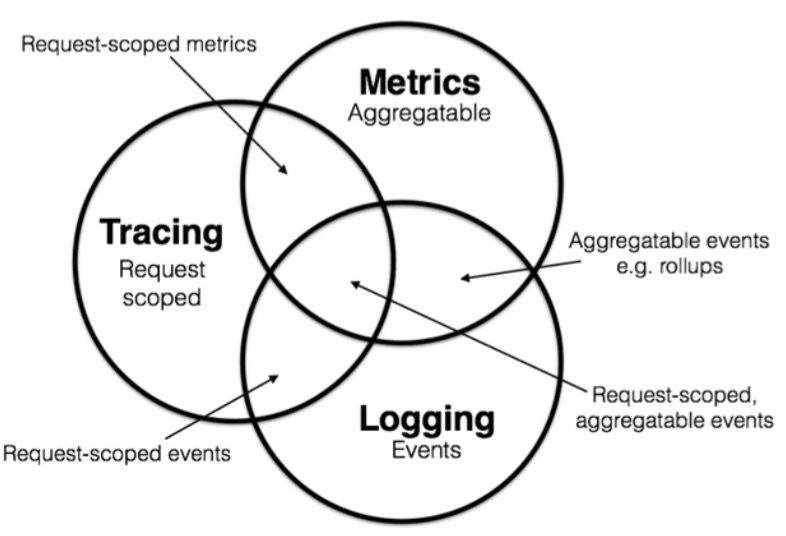
可观测性问题
可观测性 现代的可观测性(Observability)等于以下三者的集合。 可观测性概念起源于控制理论中的可观察性(observability) 系统的可观测性,指该系统可以由其外部输出推断其内部状态的程度 某一个系统的可观测性越强,那么我们对这个系统的把控能力也会越强 需要明确,监控是一个动作。 目前认为,一个完整的可观测性系统,具备输出三种类型数据的能力:metrics、log、trace。 实际上,metrics、log、trace只是三种数据类型,本身与可观测性无关。仅仅是收集这些类型的数据,并不能保证系统的可观测性。 但是将这些数据进行合理的收集、存储、分析和利用,就容易使系统具有一定的可观测性。因此这些数据,又被称为可观测数据。 定义: metrics指标:是原子性的、可累加的一种值,用于表示在⼀段时间内测量的数值,每个metrics都是一个逻辑计量单元。 trace链路追踪:又称分布式链路追踪,表示 请求通过分布式系统 的端到端的路径。 log日志:用于描述一些离散的(不连续的)事件,是对特定时间发⽣的事件的⽂本记录。 特性: metrics ...
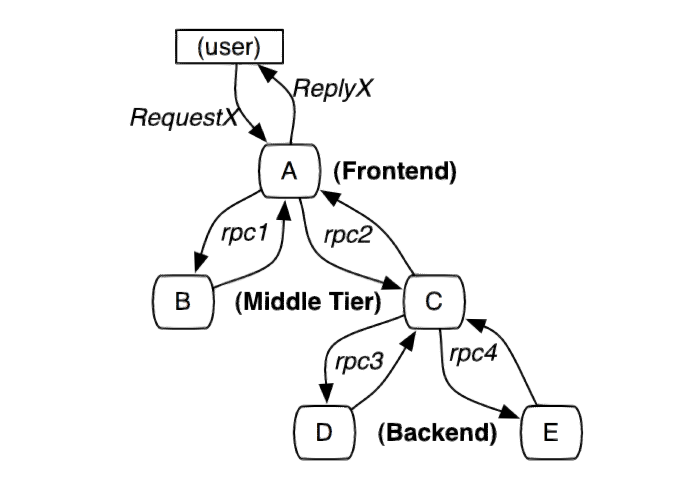
Dapper 论文
参考译文 dapper分布式跟踪系统原文 概述 当代的互联网的服务,通常都是用复杂的、大规模分布式集群来实现的。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能部署在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具。 Dapper–Google生产环境下的分布式跟踪系统,应运而生。那么我们就来介绍一个大规模集群的跟踪系统,它是如何满足一个低开销、应用透明的、大范围部署这三个需求的。当然Dapper设计之初,参考了一些其他分布式系统的理念,尤其是Magpie和X-Trace,但是我们之所以能成功应用在生产环境上,还需要一些画龙点睛之笔,例如采样率的使用以及把代码植入限制在一小部分公共库的改造上。 介绍 我们开发Dapper是为了收集更多的复杂分布式系统的行为信息,然后呈现给Google的开发者们。这样的分布式系统有一个特殊的好处,因为那些大规模的低端服务器,作为互联网服务的载体,是一个特殊的经济划算的平台。想要在这个上下文中理解分布式系统的行为,就需要监控那些横跨...

重写 ELK 相关信息
ELK in docker 官方文档见:《Running the Elastic Stack (“ELK”) on Docker》 Start Elasticsearch and Kibana in Docker 任意在容器中启动的单节点 Elasticsearch 集群都会 security will be automatically enabled and configured for you。这包括: 证书和key会在配置目录下自动生成。Certificates and keys are generated for the transport and HTTP layers.``When you install Elasticsearch, the following certificates and keys are generated in the Elasticsearch configuration directory, which are used to connect a Kibana instance to your secured Elasticsearc...
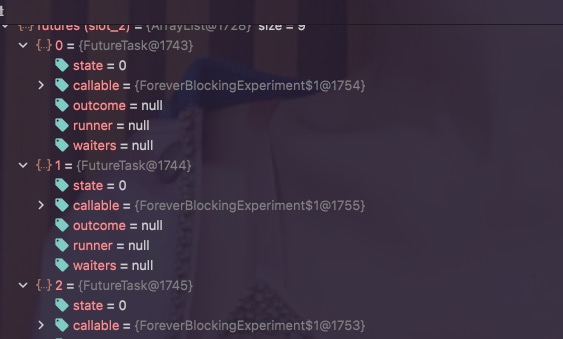
一个隐藏了17年的 JDK Bug
摘要 本文介绍了发现JDK-8286463 : DiscardPolicy may block invokeAll forever的全过程。 问题起因 因为工作需要,笔者最近考虑利用 Java 标准文档里的标准 API做一个批量执行任务的框架: 这个 API 的语义是: 批量执行任务。 在任务执行完成(不管任务是被正常终止还是异常终止)后,批量返回一个持有任务状态的 Future 列表。 我们团队内部的代码里已经有了一个自定义线程池的工厂方法,大义是: 1234567891011121314151617181920212223242526272829303132333435363738394041/** * 一个有缺陷的线程池构造器 * * @param corePoolSize the number of threads to keep in the pool, even * if they are idle, unless {@code allowCoreThreadTimeOut} is ...

Lombok 拾遗
sneakyThrow 12345678public static RuntimeException sneakyThrow(Throwable t) { if (t == null) throw new NullPointerException("t"); return Lombok.<RuntimeException>sneakyThrow0(t); } private static <T extends Throwable> T sneakyThrow0(Throwable t) throws T { throw (T)t; }

基于 Play 框架进行开发
构建和编译的方法 sbt clean "project leads-web" "universal:packageZipTarball" 常用命令 1234567891011121314151617# 在 sbt 里# 刷新命令reload;update;clean;compile# 切换到项目 aproject a# 在 sbt 的项目 a 里run "-Dotel.resource.attributes=serviceName=iouy"# 如果使用了 coursier 来管理依赖的话,查看依赖coursierDependencyTree# 在普通的 shell 里# 开启远程调试sbt -jvm-debug 9999 run# 传递 jvm 参数sbt -J-javaagent:skywalking-agent.jar -jvm-debug 9999 run ORM ebean 1234567891011121314151617181920212223242526lazy val `model-base` = ...

领域驱动设计汇总
总结 DDD 主要是面向对象范式的高级应用。 分治、分层、抽象、演化是架构设计的4大原则。 分治是为了让复杂度变小,而且围绕单一的中心概念具有内聚,又通过边界区别彼此。在DDD中,在解决规模性问题,防止模型出现分裂-矛盾和重复的时候,使用战略设计:上下文(支持边界,天然为微服务服务,这里的上下文边界也是组织架构的边界,也强调团队管理)、精炼(围绕核心域的种种动作)、大型结构(分层在这里被强调)。战术设计则是围绕各种职责类型,强调程序的构造块。 分层 主要依赖于大型结构和模型驱动设计提到的 flexible layered architecture。 抽象意味着永远留有余地,核心越薄越好,这也是精炼要求的。 演化在这里则体现为,允许系统设计不断通过重构来精化模型。 在 DDD 的原书里面,为了防止模型出问题,才逐渐引入战略设计。 但别的 DDD 书籍里面,作者们都主张直接从战略设计入手。 DDD 官网 真实的架构是由项目需求驱动出来的。 左半段最外层叫 interface 层;右半段最外层叫 infra 层。左半段的 bus 是 command query bus,右半段...
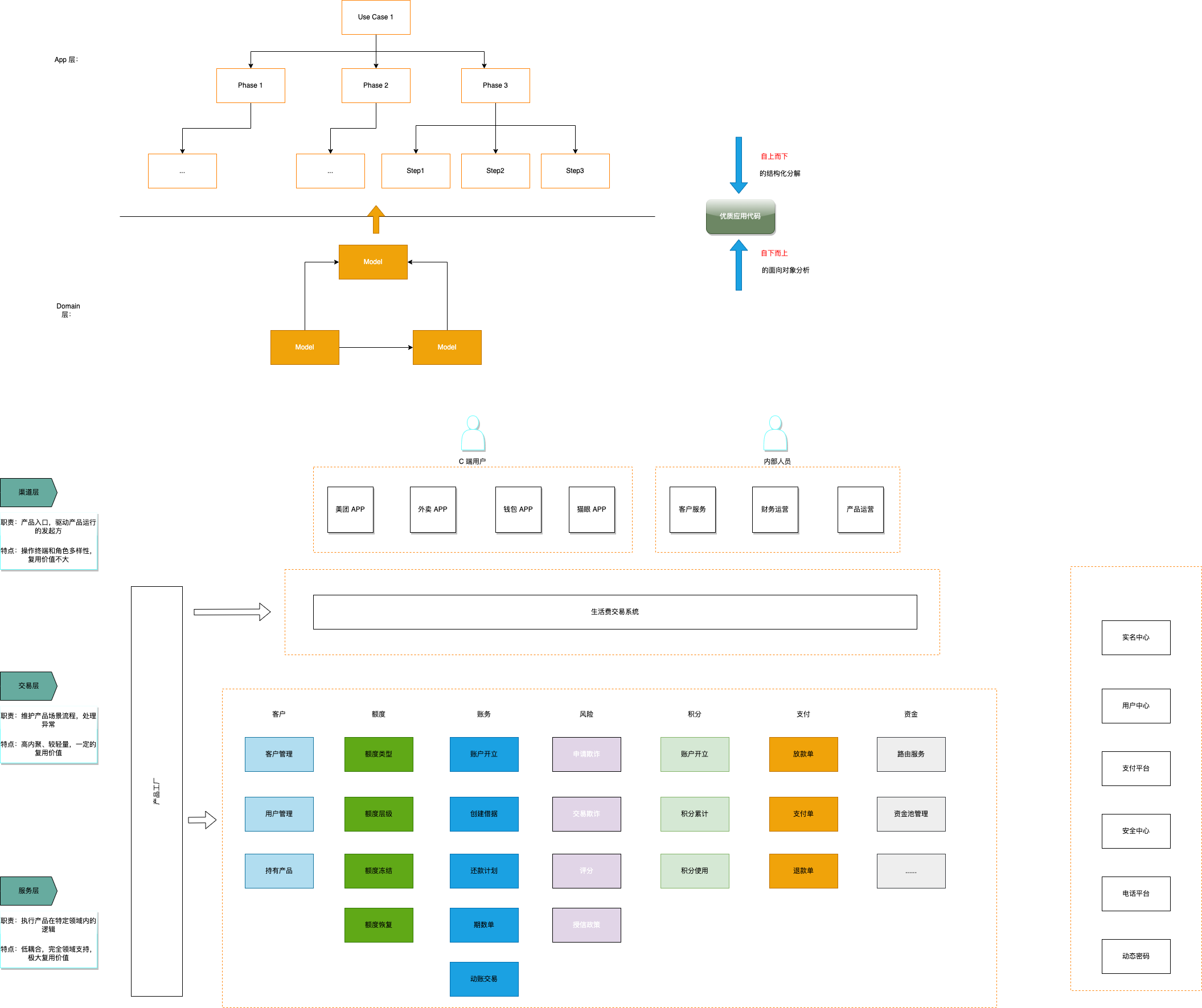
如何写业务代码
业务研发面对的问题 稳定的业务模式 不稳定的需求 业务对交付的渴望 假设 命名规范(《clean code》) 面向对象设计(SOLID原则、贫血/充血模型、设计模式) 系统要拆分 流程控制系统与领域系统.drawio 每一个用例(解决的一个问题)都由访问逻辑和执行逻辑组成。访问逻辑负责用例执行的顺序与分支,并调用执行逻辑完成完整业务逻辑。 访问逻辑由单独的交易系统负责。执行逻辑由个子系统负责。 工程要拆分 三层架构 + 洋葱架构 代码要拆分 业务代码:描述核心业务逻辑的代码,核心是保持业务的流程及业务状态的一致性 领域对象与领域服务,不得对外部有任何依赖(工具类除外) 最核心的几个抽象: 校验:参数有效性校验、参数的业务属性校验。在进入正常业务逻辑代码前,完成所有的校验工作。 异常:业务异常:所有不符合业务逻辑而产生的异常。 系统异常:因为程序本身or依赖产生的异常。 所有的异常第一位runningtime异常。 数据: 业务数据:保存领域对象状态的数据。 非业务数据:过程数据。业务的核心流程中,只对业务数据的持久化负责。 参数:任何时候,任何方法的参数都需要...
Idea 的小技巧
调试的时候的断点 Suspend Policies Specifies whether to pause the program execution when the breakpoint is hit. Non-suspending breakpoints are useful when you need to log some expression without pausing the program (for example, when you need to know how many times a method was called) or if you need to create a master breakpoint that will enable dependent breakpoints when hit. The following policies are available for the breakpoints that suspend program execution: All: all threads are suspended when...




