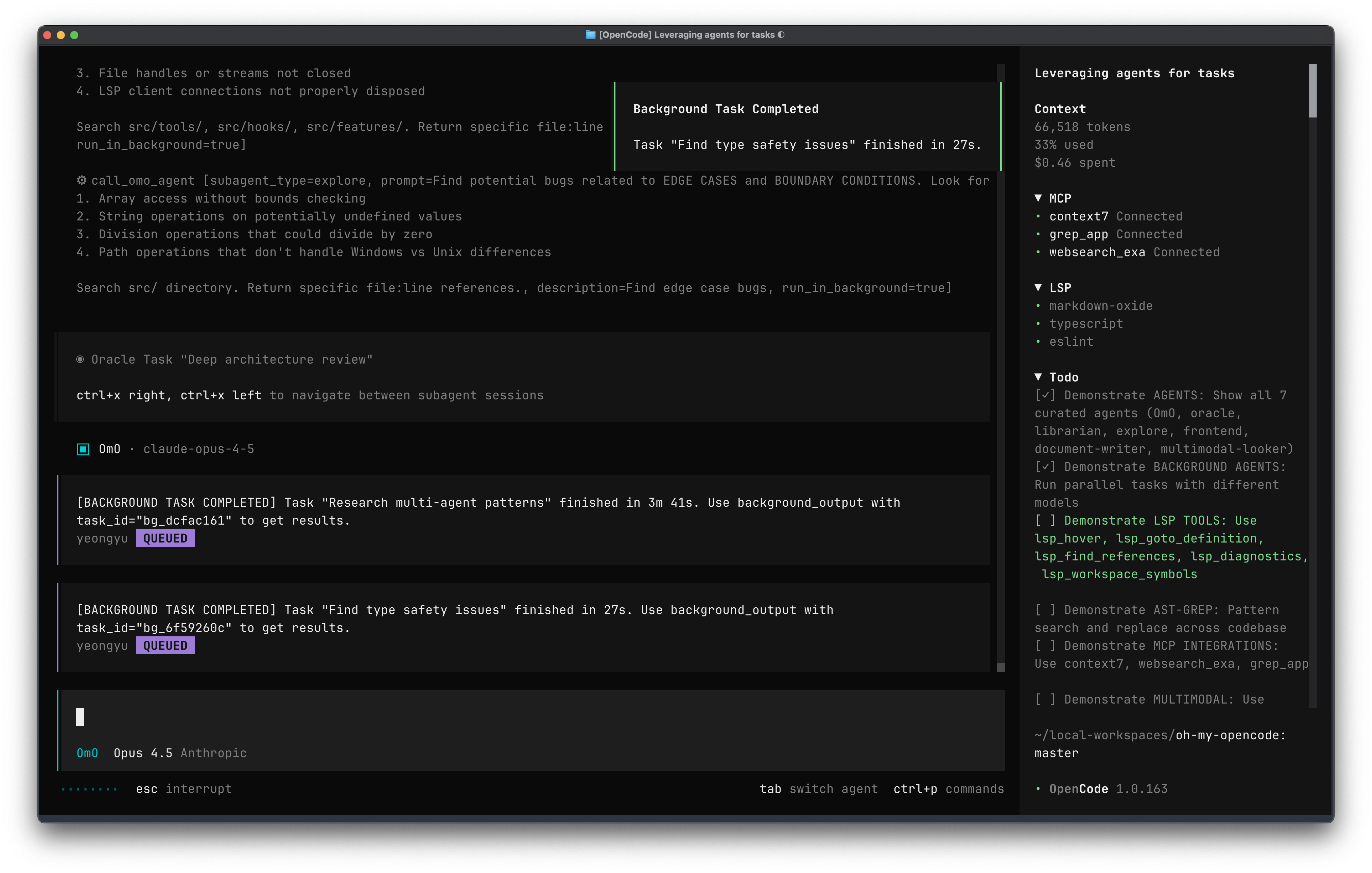
MySQL 中的引号
标准的 SQL 中只允许用单引号表达字符串类型。有些 SQL 方言允许使用双引号包裹字符串,如 MySQL,有些则不允许,如 Oracle。 反引号是专门用来表达 identifier 的。

MySQL 字符串和数字隐式转换的 pitfall
Data truncation: Truncated incorrect 不要小看 MySQL,它出 warning 就一定有错误。 不要滥用 MySQL 字符串到decimal,和 decimal 到 string 的转换。这样有时候 MySQL 不只是 warning。

散列算法
散列算法概述 散列函数(Hash Function)是一种将任意长度的输入数据映射为固定长度输出的函数,该输出称为散列值或哈希值。散列算法在计算机科学中具有广泛应用,尤其在密码学和数据完整性校验领域。 核心性质 一个优秀的散列函数应具备以下核心性质: 确定性:相同的输入始终产生相同的输出。这是散列函数的基本要求,确保了散列值的一致性和可验证性。 单向性:从散列值无法反向推导出原始输入。这一性质使散列函数适用于密码存储等场景,即使数据库泄露,攻击者也无法直接获取明文密码。 雪崩效应:输入数据的微小变化会导致输出散列值的剧烈变化。修改输入的任意一位,输出的散列值应有约50%的位发生变化。这一特性保证了散列值对输入的高度敏感性。 抗碰撞性:难以找到两个不同的输入产生相同的散列值。抗碰撞性分为弱抗碰撞性(给定输入,难以找到另一个输入产生相同散列值)和强抗碰撞性(难以找到任意两个不同输入产生相同散列值)。 常见散列算法家族 MD5 MD5(Message Digest Algorithm 5)输出128位散列值,曾广泛应用于文件校验和密码存储。然而,MD5已被证明存在严...

checklist
写代码 checklist 注意位置 注意顺序 注意初始化 注意返回值 注意注释 注意防御性编程 注意数据库性能 上线 checklist 代码变更 check 代码 配置变更 check 配置 系统变更注意上线顺序 依赖中间件变更注意配置中间件 配置中心配了吗 交互所有细节都实现了吗? 配监控和埋点 数据库变更了吗? 安全检查

JDWP 与远程调试
JDWP(Java Debug Wire Protocol),它提供了调试器和目标 JVM (target vm)之间的调试协议。 在 target vm 启动时,增加这个 JAVA_OPTS: 1JAVA_OPTS="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=26310" 在服务器端,增加 remote debuging 的时候使用如下配置: 12345678# Java 9 以上-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:8000# Java 5-8-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000# Java 1.4.x -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,addre...

卡表和 RSet
卡表和 RSet 问题定义:为什么需要跨区域引用记录 JVM 垃圾收集器的核心工作之一是确定 live set——哪些对象仍然存活、不可回收。确定 live set 的标准做法是从 GC Roots(栈帧中的局部变量、静态字段等)出发,沿引用链遍历所有可达对象。 问题在于:当堆被划分为多个区域(代、Region)并且只回收其中一部分时,如何高效地找到从"不回收区域"指向"回收区域"的引用? 以 Young GC 为例:只回收新生代,但老年代中可能持有指向新生代对象的引用。如果不处理这些跨代引用,就会错误地回收仍被老年代引用的新生代对象。最朴素的做法是扫描整个老年代来找出这些引用——但老年代通常远大于新生代,这样做的代价过高,违背了分代收集"只回收一部分堆"的初衷。 卡表(Card Table)和 RSet(Remembered Set)正是为解决这个问题而设计的辅助数据结构。二者的关系并非互相替代,而是层次不同、协作互补:卡表是底层的脏标记机制,RSet 是建立在卡表之上的更高层索引结构。 核心概念速览 在深入细节之前,...

数据建模名称规范
综合 NV + DiDi + Ali 的各种命名规范。 DO( Data Object):与数据库表结构一一对应,通过DAO层向上传输数据源对象。 DTO( Data Transfer Object):数据传输对象,Service或Manager向外传输的对象。 BO( Business Object):业务对象。 由Service层输出的封装业务逻辑的对象。 AO( Application Object):应用对象。 在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。 VO( View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象。 POJO( Plain Ordinary Java Object):POJO专指只有setter/getter/toString的简单类,包括DO/DTO/BO/VO等。 Query:数据查询对象,各层接收上层的查询请求。 注意超过2个参数的查询封装,禁止使用Map类来传输。 Entity:JPA 规范下从数据持久层存储里取出来的对等对象。其实相当于 DO 。 Request:RESTful 接...
业务分析方法
背景 从 prd 出发,分析业务需求,寻找可以创造价值的方案。 业务分析的价值 全面分析用户的各项需求 告诉我们“做什么” 业务分析的目的 理解产品需求,识别业务范围 分析业务模块的重要程度、优先级 发现产品设计的不足 为后后续测试分析做准备 业务分析方法-整体过程 用不同的动作达到不同的产出。 理解 需求背景(必须) 举例:阿里巴巴账户体系 要初步阐述:1. 产生什么价值。 2. 需要解决什么问题。3. 甚至要阐明要达到什么目标(比如,基于支付宝账户体系统一账户id)。 现状分析(必须) 产品定位 现有业务架构 产品业务范围 规划业务架构**(1. 要有分期的意识,识别产品形态。 2. 要有清洗数据的方案,预测安全风险)** 识别(抽象分析建模) 业务角色(实际上就是系统交互的输入方,有多少个角色,就需要关注多少个东西) 自然人 其他系统 业务串联(为了找业务用例。业务串联就是把一堆文字描述串在一起) 业务用例(建模-业务用例图 用例是对场景的概括) 分析业务用例(建模-活动图 活动图是对用例的拆解) 提炼(进一步建模) 关键流程 由活动图的 ...

系分方法论交流笔记
分析、设计和架构的区别 系分 = 业务分析 + 系统设计 系分其实就是 Analysis + Design 业务分析才是最重要的大头 要理解: 架构约束 项目约束 要有: 权衡 选择 的过程 理解业务,要理解业务背后的东西,产出的是模型。 一步一步走,推演出来解决方案,要有方法论。 系统设计是很明确的工作了 应用设计 + 数据设计 + 技术设计 = 系统方案 要考虑的额外问题: 非功能设计:运行关注点、运维关注点、开发关注点、测试关注点。 项目约束 常见方法论 用例驱动设计 SOAD 面向服务的分析和设计 OOAD 面向对象分析和设计 DDD 领域驱动设计 DDD特别适合复杂系统。有一个以不变应万变的对象,才可以在未来承载复杂的业务演进过程。 这几种方法论可以混合使用。 需求分析与业务建模 把 prd 从薄读到厚,把文档中缺失的部分补全。 系分做 PRD 评审的时候,影响比较大的点一定要尽早确认。一些对系统变化可控,可预测的变化,可以暂时放过,后续在补充。 面向服务的业务建模 分析主业务服务,设计业务功能域,设计业务功能域边界。这个过程可能不断地螺旋式地重构。 如果用...

OOM 调查使用到的工具
基础工具 top 与 htop。这两个东西比 free 好用。比较神奇的是,为什么线上还有装了 htop这样的非标准 top。字节跳动自己开源了一个 atop,可以细致地监控线程信息,也可以快速采集系统信息,是一个不错的监控工具。 pmap。这个东西是莫枢自己也用来 dump 详细的内存轮廓的地址,但可能需要使用他提到的一个 Serviceability Agent API 来读才读得懂。这个工具的输出可以看到各段内存的起止,但不经帮助,很难读出各个子线程的栈来。 这个命令在非 root/sudo 权限下看到的是 jvm 启动参数,在 root/sudo 权限下看到的是内存轮廓,这时候就需要 Serviceability Agent API 了。 smem。这个东西对内存的 RSS/PSS/USS 分析得很好。但并不能帮助我们直接获知我们最期待的栈内存轮廓,比如当前 JVM 的 stack 到底是怎么分布的,占了多少内存?而且更重要是,线上机器没有这个工具。 直接 cat /proc/pid/smaps 其实其他的进程内存查看工具的信息可能都能在这里看得到,但是需要耐心。而且,...