

苹果印度产能转移深度调查:一场价值千亿美元的制造业大迁徙
2025 年 3 月的一个深夜,一架满载 iPhone 的货运包机从印度金奈起飞,直奔美国。这批价值 20 亿美元的手机,是苹果有史以来最大规模的一次印度空运。在特朗普关税大棒即将落下的前夜,库克用一种近乎"抢跑"的方式,向全世界宣告了一个事实:iPhone 的制造版图,正在发生不可逆转的重构。 这不是一个简单的"搬工厂"故事。这是一场涉及地缘政治博弈、供应链重塑、劳动力素质鸿沟、基础设施短板的复杂系统工程。苹果的原计划是什么?印度扩产进度顺利吗?遇到了哪些始料未及的问题?本文试图用数据和事实,还原这场价值千亿美元的制造业大迁徙的全貌。 为什么要离开中国? 要理解苹果的印度战略,首先要理解它为什么要离开中国——或者更准确地说,为什么要降低对中国的依赖。 一场疫情暴露的致命弱点 2022 年底,郑州富士康因疫情封控导致大规模生产中断。这座被称为"iPhone 城"的超级工厂,巅峰期拥有超过 35 万名工人和约 38 条产线,承担着全球 iPhone 产量的半壁江山。当它停摆时,苹果在圣诞旺季遭遇了严重的供货危机。 这一事件...
沉默的杀手:美军在东南亚留下的未爆弹药深度调查
半个多世纪前,美军在东南亚投下了人类历史上最密集的炸弹雨。战争早已结束,但炸弹从未停止杀人。 本文基于 Landmine & Cluster Munition Monitor、美国国务院、联合国开发计划署(UNDP)、国际红十字委员会(ICRC)、老挝国家监管局(NRA)等权威机构的公开数据,系统梳理美军在老挝、越南、柬埔寨三国留下的未爆弹药(Unexploded Ordnance, UXO)规模、持续伤亡,以及国际社会的回应。 一、历史背景:人类史上最猛烈的轰炸 1.1 老挝——“地球上被轰炸最多的国家” 1964 年至 1973 年间,美国在老挝发动了一场未经国会授权的秘密战争(Secret War)。根据美国国会记录(Congressional Record, 1975 年 5 月 14 日)和 Legacies of War 的数据: 投弹总量:超过 200 万吨弹药 轰炸任务:580,000 次——相当于每 8 分钟投下一架飞机的炸弹载荷,持续 9 年不间断 集束弹药:投下超过 2.7 亿枚集束子弹药(submunitions),当地人称之为"bo...

Java栈帧省略机制详解:为什么异常堆栈会消失?
引言:诡异的异常堆栈消失现象 线上服务报错时,你打开日志准备排查问题,却发现异常堆栈信息神秘消失了: 1java.lang.NullPointerException 只有短短一行异常类名,没有完整的堆栈跟踪。你可能会怀疑:是日志框架出问题了?还是被什么拦截器截断了? 其实,这是 JVM 的一个性能优化机制,叫做 OmitStackTraceInFastThrow(快速抛出时省略堆栈跟踪)。从 JDK 5 开始引入,默认启用。 本文将深入剖析这个机制的设计动机、工作原理、触发条件,以及如何正确应对。 一、问题场景:异常堆栈去哪了? 1.1 复现现象 用一段简单的代码就能复现: 123456789101112public class ExceptionOmitDemo { public static void main(String[] args) { String msg = null; for (int i = 0; i < 500000; i++) { try { ...

Coding Agent 代码检索技术全景:从 GREP 到知识图谱
Coding Agent 的核心能力之一是在陌生代码库中快速定位相关代码。无论是修复一个 bug、实现一个新功能,还是回答一个架构问题,Agent 的第一步几乎总是:找到相关的代码在哪里。 这个看似简单的问题,实际上是整个 Agentic Coding 领域最基础也最棘手的挑战。不同的 Coding Agent 给出了截然不同的答案——Claude Code 坚持用 grep,Cursor 构建了基于 Merkle 树的向量索引,Aider 用 PageRank 算法生成 RepoMap,Graphify 则把代码库变成了一张知识图谱。 这些方案之间是什么关系?是同一层次的竞争方案,还是不同层次的互补技术?各家的取舍逻辑是什么?未来的发展方向又在哪里? 本文从技术原理出发,逐层拆解当前主流的代码检索方案,分析它们的设计哲学与工程取舍,最终给出一个统一的分层理解框架。 全景导图 %%{init: {'theme':'base', 'themeVariables': {'primar...
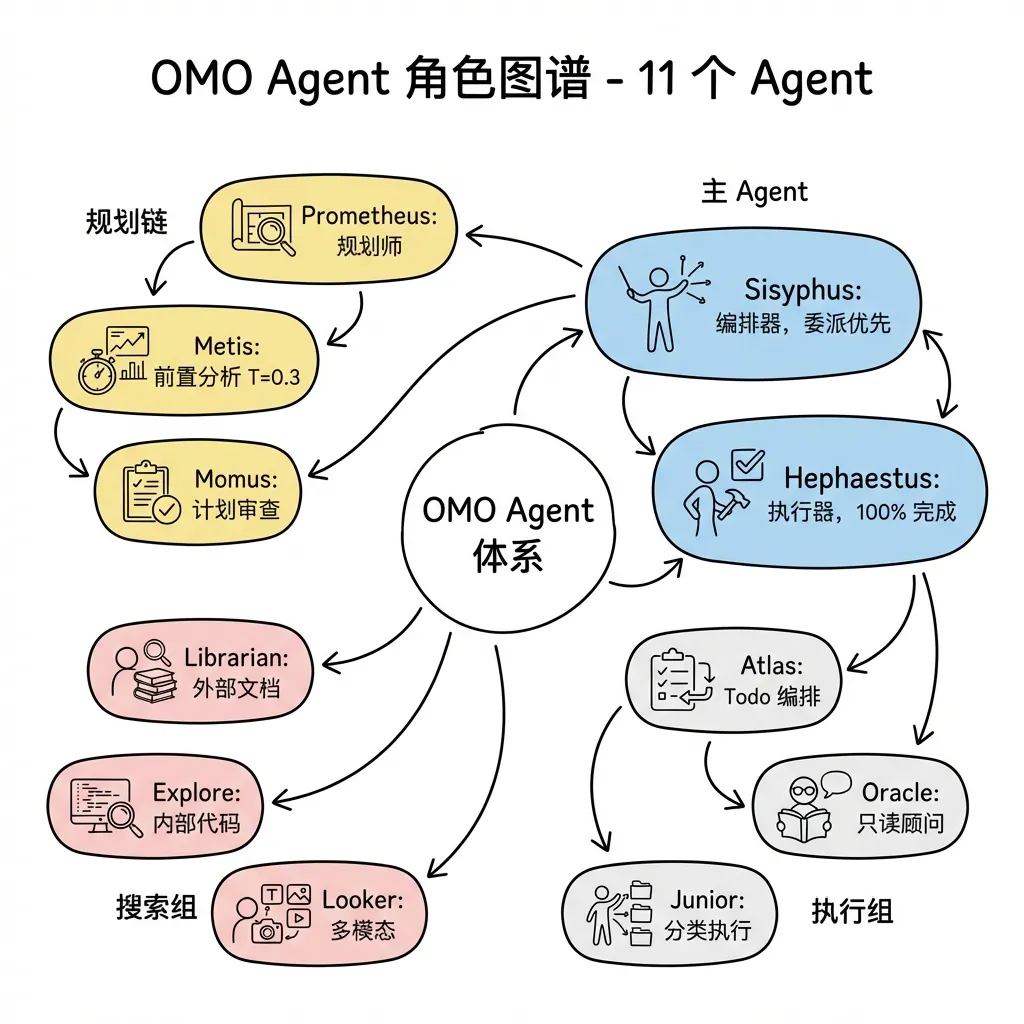
Agentic Coding 深度解析:从架构原理到多 Agent 协作
AI 编程工具的演进,正在经历一次根本性的范式转变:从"补全光标处的代码",到"自主完成端到端工程任务"。这种转变有一个专有名词——Agentic Coding。 围绕 Coding Agent 的讨论,常见两种极端:将其神化为自主智能体,或将其贬为"不过是提示词工程"。两种判断都失之简单。理解这个转变,需要从三个层面展开:工具层(OpenCode 的能力边界)、框架层(多 Agent 协作编排)、方法论层(如何让 Agent 真正服务于工程流程)。本文从真实的架构出发,拆解 Claude Code、OpenCode 等工具的实现模式,厘清各自的设计取舍,深入探讨子 Agent 的本质与多 Agent 协作的核心问题。 什么是 Agentic Coding 传统 AI 编程助手的工作模式是响应式的:开发者提问,AI 回答;开发者选中代码,AI 补全。人始终是执行者,AI 是辅助工具。 Agentic Coding 的工作模式是自主式的:开发者描述目标,Agent 自主规划步骤、调用工具、执行操作、验证结果,直到任务完成...

Graphify 深度解析:用知识图谱重新定义 AI 编码助手的代码理解能力
项目地址:safishamsi/graphify(⭐ 27.6K) 版本:v4(截至 2026-04-16) 一句话总结:把代码、文档、论文、截图丢进去,生成一张可查询的知识图谱,让 AI 编码助手从"逐文件 grep"进化到"按图索骥"。 你有没有过这样的体验——在 Claude Code 里问一个架构问题,它花了 80% 的 token 在 Glob 和 Grep 上翻文件,最后给你一个似是而非的答案? 这不是 AI 不够聪明,而是它看不到全局。 Graphify 就是来解决这个问题的。它不是又一个 RAG 工具,不是又一个向量数据库,而是一个面向 AI 编码助手的知识图谱构建技能——用确定性的 AST 解析 + LLM 语义提取,把你的代码库压缩成一张结构化的图,然后让 AI 先看地图再找路。 它到底是什么 Graphify 是一个 Claude Code skill(现在也支持 Codex、OpenCode、OpenClaw、Factory Droid、Trae 等平台),核心做的事情只有一件:把任意文件夹变成一张可查询的知识图...

为什么你的"AI-First"战略可能是错的——CreaoAI 的全面重构实践
原文链接:Why Your “AI-First” Strategy Is Probably Wrong 作者:Peter Pang(CreaoAI 联合创始人,前 Meta LLaMA 团队) 发布时间:2026-04-13 翻译与总结:2026-04-15 前言 这篇文章来自 Peter Pang 在 X(Twitter)上发布的长文,发布后迅速获得了 3100+ 点赞、9300+ 收藏、160 万+ 阅读,引发了广泛讨论。 Peter Pang 是 CreaoAI 的联合创始人,此前在 Meta 参与 LLaMA 项目。CreaoAI 是一个 Agent 平台,仅有 25 名员工、10 名工程师。他在文中详细描述了如何将整个公司的工程流程、产品流程、测试流程围绕 AI 进行彻底重构,而不是简单地"在现有流程上加一个 AI 工具"。 这篇文章的核心观点与 OpenAI 在 2026 年 2 月提出的 Harness Engineering(驾驭工程) 概念高度一致:工程团队的首要工作不再是写代码,而是让 Agent 能够有效地完成工作。 以下是原文的完整...

Anthropic Managed Agents 深度研究:解耦大脑与双手的架构哲学
原文链接:Scaling Managed Agents: Decoupling the brain from the hands 研究时间:2026-04-14 研究方法:多轮迭代搜索 + 交叉验证 + 结构化综合 前言:从"程序即未设想之物"说起 Anthropic 在 2026 年 4 月发布的 Managed Agents 服务,解决了一个经典的计算机科学问题:如何为"尚未设想的程序"设计系统。 这个问题的答案,早在几十年前操作系统设计时就已经给出——通过虚拟化硬件为通用抽象(进程、文件),使得 read() 系统调用既能访问 1970 年代的磁盘组,也能访问现代 SSD。抽象层保持稳定,底层实现自由演进。 Managed Agents 做了同样的事情:将 Agent 组件虚拟化为三个核心组件——Session(追加式事件日志)、Harness(调用 Claude 并将工具调用路由到相关基础设施的循环)、Sandbox(Claude 可以运行代码和编辑文件的执行环境),并在此基础上通过**两个扩展维度——Many Brains(多...

Claude Code 源码深度解析:五层架构与核心设计模式
全景导图 %%{init: {'theme':'base', 'themeVariables': {'primaryColor':'#e3f2fd','primaryTextColor':'#1565c0','primaryBorderColor':'#1976d2','lineColor':'#42a5f5','secondaryColor':'#fff3e0','tertiaryColor':'#f3e5f5','fontSize':'14px'}}}%% flowchart TD A[Entrypoints 入口层] --> B[Runtime 运行时层] ...

Compound Engineering:当 AI 工程从"模型调优"走向"系统组合"
2024 年,Berkeley AI Research 的文章 The Shift from Models to Compound AI Systems 把一个已经在工程现场发生的变化命名了:AI 应用的能力不再只来自单个模型,而越来越来自多个组件的组合。 模型仍然重要。但在知识更新、工具调用、权限控制、成本预算、延迟约束和可审计性面前,单个模型很难独自承担完整系统的责任。检索器(Retriever)、路由器、工具、工作流、验证器、监控和降级策略开始进入同一个架构图。围绕这种组合方式形成的工程实践,可以称为 Compound Engineering。 先把定义压实 Compound AI System,通常译作复合 AI 系统,指的是由多个相互作用的组件共同完成 AI 任务的系统。这些组件可以包括一次或多次模型调用、检索器、数据库、外部 API、代码执行器、专用模型、规则引擎、评估器和人工审核节点。 BAIR 对这个转向的判断很直接:不少 AI 任务的性能提升,已经不只依赖更大的模型,而依赖围绕模型搭建的系统。Databricks 后续也把复合 AI 系统描述为由模型、工具、检...




