
OKR 笔记
http://arthurchiao.art/blog/short-history-of-okr-zh/ OKR 的历史 ORK 是目标管理领域的新工具。诞生于 Intel,帮助 google 取得成功。在国内主要是美团和字节在使用。 上世纪 50 年代,管理科学(management science)兴起,主要用意是提高公司效率。Peter Drucker 发明了 MBO(Management By Objectives,目标管理制度)。MBO 是一个过程,在该过程中,管理者和员工共同设定一个目标,然后定义各自需要做什么才能完成这一目标。 MBOs 显然是 Objectives and Key Results (OKRs) 的前辈。在 OKR 模型中,经理 设定一个目标之后,不再插手细节管理(micromanaging),而是信任自己的团队能够完成 这一目标 —— 和工业时代的管理方式相比,这是一种巨大和高效的转变。从很多方面 来说,这是第一种真正与新的信息时代相匹配的管理哲学。所以计件式的微管理意味着管理者还不能信任下属能够达成这一目的,但 OKR 就意味着简单高效了。 到了...

Team Topologies
团队是执行力的基础 产品的差异来自于执行力的差异,执行力的差异来团队的差异。人口红利的消失,呼唤精细化管理。 软件开发是一个富有创造性的职业,产品的质量、产品的迭代速度有很大程度上依赖于架构师和工程师的水平。如何让人更高效的发挥自己的价值,并且让个人价值更好的服务于整个团队需要,绝对是一项很重要也很体现个人水平的技能。 两种团队 过分务虚 过分务虚的团队对于业务和技术都比较缺乏深入的见解,运用了许多组织模型但却缺乏明确的解决问题的方向,我相信这些团队长期一定难以做出应有的影响力。 过分务实 过于务实的团队指的是更关注于底层技术细节的准确性,但是缺乏更深层次更高维度的对业务整合的理解、对解决什么问题的解构、对团队协作和团队文化的建设;这种类型很容易很吃力但没什么真正的影响力、或者人心涣散。 系统设计从团队设计开始 这是根据康威定律很自然的一个延伸,当年决定团队架构的时候,你就已经在决定系统架构了。 管理者是不是需要懂技术?根据这条原则管理者是需要懂她负责的业务的,而且需要非常懂。当然业务在这里很多情况下指的就是技术,但不仅限于技术本身,还包括技术和产业的结合,需要解决什么样的问...

如何进行产品需求/项目立项
需求分析的三重境界 第一层次:用户的观点和行为 第二层次:用户的目标和动机 第三层次:用户的人性价值观 用户场景分析 谁遇到了问题[WHO] 什么环节遇到了问题[WHEN] 在哪里遇到了问题 [WHERE] 问题是什么[WHAT] 问题产生原因[WHY] 如何解决[HOW] 解决成本[HOW MUCH] 商户 售后 因为 xxx,不得不退款 造成经营损失 平台出于成本考量,不能对此进行赔付 通过 新建 xxx 产品能力,提供补充能力 待思考,也许是中 需求背景 要讲场景,讲数字,有定性 项目评估 项目收益:某项指标会上升、某项指标会下降。 项目目标:上线时间。 涉及资源:涉及几个部门和团队? 具体产品设计方案 产品到底有几个维度的细节,要建设的细节分别是什么。

机器学习的几个概念
混淆矩阵 混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。 * * True Class True Class * * p n Hypothesized Class Y True Positive False Positive Hypothesized Class N False Negative False Positive 精准、召回与打扰率 precision 精准 策略识别真实 bad case True Positive/策略识别的 bad case True Positive + False Positive 风控识别出 100 个案子,实际上有 20 个是真的,精准率为 20%。 注意,这里我们并不知道所有案子有多少。这里讨论的是已经找出的案子的精准率。 recall 召回 策略识别真实 bad case True Positive /所有真实的 bad case True Positive + False Negative 总共发生了 ...

STARR 法则
STAR 法则最早用于面试,后来演变为 STARR,最后一个 R 是反思/Reflection。 但 STARR 不仅适用于面试,也适用于工作小结,项目报告等各种场景。 什么是STARR行为面试法? 所谓 STARR原则,即 Situation(情景)、Task(任务)、Action(行动)、Result(结果)、Reflection(反思)五个英文单词的首字母组合。 S - Situation - 情景:描述候选人过去经历中某件重要事件背景状况,了解候选人行为背后的动机。我们需要特别关注的是过去行动的背景情况与未来岗位场景之间的相似性。 T - Task - 任务:了解候选人在其背景环境中所执行的任务与角色,从而考察该候选人是否做过其描述的职位及其是否具备该岗位的相应能力。 A - Action - 行动:是考察候选人所担任的角色与执行任务的方式。行动是行为事例(STAR)的核心,因为多个STAR的行为串在一起就能说明候选人是否有某种行为模式。 R - Result - 结果:即该项任务在行动后所达到的效果,我们要关注行为和结果的因果关系,需要特别注意区分和行为无关的结果...

leadership 的境界
修身:以身作则 齐家:regulate 自己的部属 治国:governance 自己的公司 平天下:occupy 占领自己的目标市场 世界上最好的商业模式是,建立一个国家。社会主义和资本主义的区别有很多,其中有一种区别是,不同的治理方式。
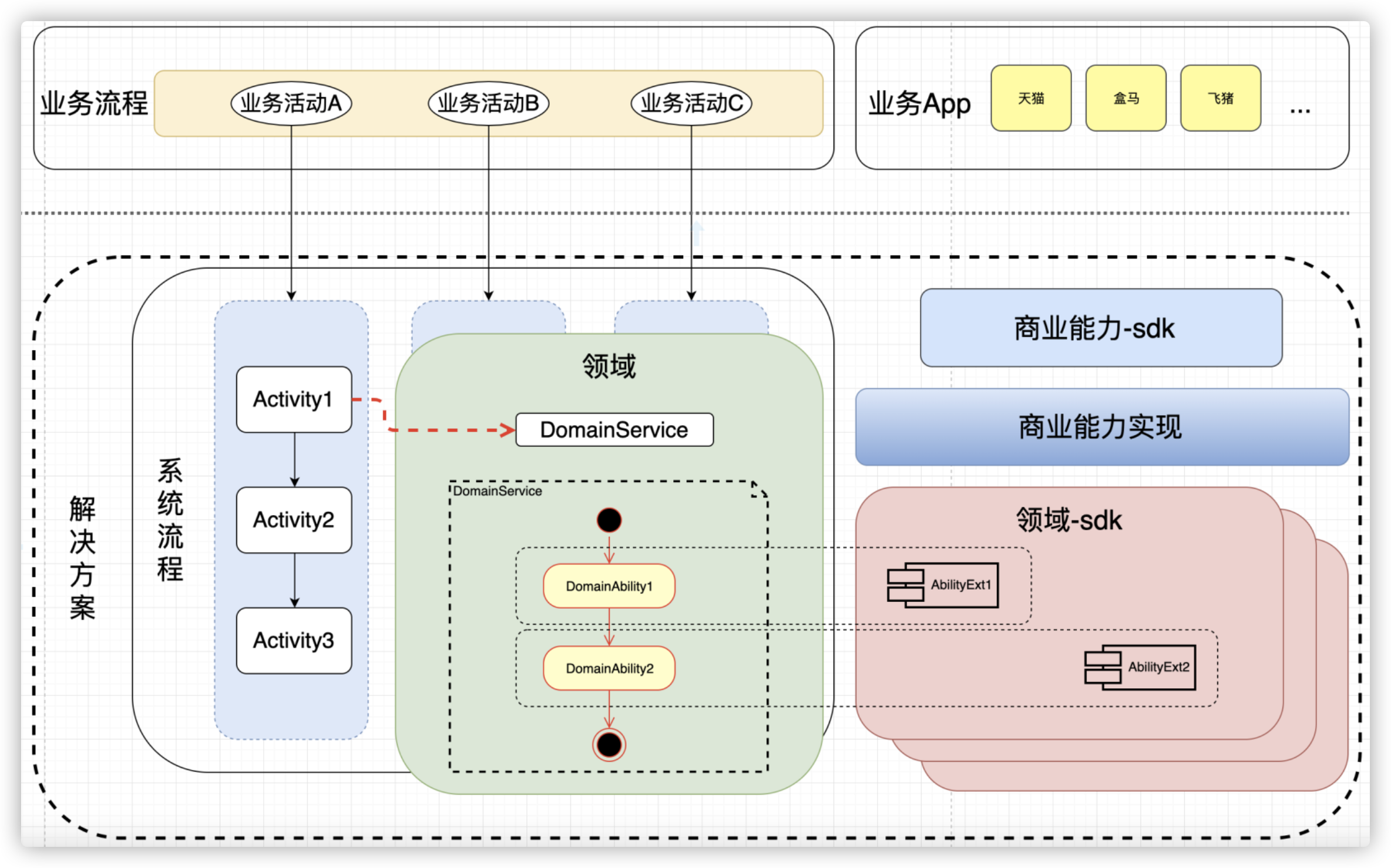
插件化架构
为什么要实现插件化架构 业务和平台要解耦。业务和平台都是多对多的关系。全链路里既有业务,也有平台。大家应该如何 talk by interface。我们看待复杂组织的业务流程,要线性看,看到很多节点;也要分层看,看到复合的层次。在这种情况下,上层架构域和下层架构域之间怎么实现复杂度的管理? 如果我们需要构建大规模的泛交易平台,我们需要靠插件化架构把我们的系统组装起来。 插件化架构通常需要一个 runtime 层(或者 boot 层)、core 层。 从业务视角来看,要解决多团队协同的问题 因为多个业务域/团队没有把能力用统一的方式透出,所以没有人能够知道统一的技术能力应该怎么串联。进行全链路沟通需要大量的沟通对齐工作。 从业务视角来看,复杂性业务要素包含本业务用例里的各种模型。 从平台视角来看,要解决复杂性管理问题 平台要支撑多种业务,业务的复杂性、差异性,以及众多业务需求不确定性,在各平台内部如何管理和支撑?简单的 if-else 不易于管理,确保对业务的支撑能力不相互影响。隔离是最好的管理手法。 从平台视角来看,复杂性业务要素包含本域内标准系统用例里的各种模型。 同一个模型,...

故障演练平台设计
目的 验证故障应急处理能力 验证服务降级及止损能力 验证中间件、存储和服务的稳定性 发现隐患,提升服务可用率 要具备的功能 有环境恢复的能力。 准备演练场景。 感知监控。 权限管理、时间管理。

投资分类
分类 股票 债券 期权 期指 股票期权 互惠基金 衍生权证 衍生品认识

规划结构化
基础结构 LongRangePlan.xmind





