缓存是提升系统性能的第一利器 ,但也是引发故障的第一杀手 。从缓存穿透、击穿、雪崩三大经典问题,到多级缓存架构、分布式锁、热点 Key 治理,缓存设计几乎贯穿后端工程师的整个职业生涯。
本文将系统性地剖析缓存系统的设计原则与生产实践,从单机进程内缓存到分布式 Redis 集群,从理论模型到可落地的代码方案,构建一套完整的缓存知识体系。
Part 1: 缓存的本质与适用场景
什么是缓存
缓存是一种以空间换时间 的优化技术,通过在计算代价较高的数据源(数据库、外部服务等)和消费方之间插入高速存储层,减少重复计算的执行次数。
存储介质延迟对比
存储介质
访问延迟
吞吐量
成本
CPU L1 Cache ~1 ns
—
极高
CPU L3 Cache ~10 ns
—
高
内存(RAM) ~100 ns
~10 GB/s
中
SSD ~100 μs
~500 MB/s
低
HDD ~10 ms
~100 MB/s
极低
网络(同机房) ~500 μs
—
—
网络(跨机房) ~50 ms
—
—
内存访问比 SSD 快 1000 倍 ,比 HDD 快 100,000 倍 。缓存的本质就是用更快的存储介质 保存热点数据 的副本。
何时使用缓存
满足以下全部条件的场景适合引入缓存:
读多写少 :读操作占比显著高于写操作(典型比例 > 10:1)热点集中 :小部分数据承担大部分访问流量(帕累托分布)可容忍最终一致性 :业务逻辑能接受短暂的数据不一致窗口计算代价高 :原始数据源响应慢或资源消耗大
不适用缓存的场景
场景
原因
实时性要求极高(如交易撮合)
毫秒级延迟无法接受任何缓存失效
写多读少
同步成本超过缓存收益
数据变化极快(如股票行情)
缓存命中率趋近于零
数据量极大但无热点
缓存无法有效缩减数据集
缓存命中率
命中率 = 命中次数 / (命中次数 + 未命中次数)
命中率
效果
说明
< 50%
差
缓存几乎没有意义
50-80%
一般
有一定效果
80-95%
好
显著减轻数据库压力
> 95%
优秀
数据库几乎无压力
缓存的分类
类型
位置
代表
适用场景
客户端缓存 浏览器/App
HTTP Cache、LocalStorage
静态资源
CDN 缓存 边缘节点
CloudFlare、阿里云 CDN
静态文件、图片
反向代理缓存 Nginx
proxy_cache
页面缓存
本地缓存 应用进程内
Caffeine、Guava Cache
热点数据、配置
分布式缓存 独立集群
Redis、Memcached
共享数据、Session
Part 2: 缓存的层次与选型
近端缓存 vs 远端缓存
缓存按部署位置分为两类:
维度
近端缓存 (In-Memory)
远端缓存 (Remote)
典型实现 Guava, Caffeine, EhCache
Redis, Memcached
访问延迟 微秒级(~100μs)
毫秒级(~1-5ms)
容量限制 受限于单节点内存
水平扩展
数据共享 进程私有
多进程共享
运维复杂度 低(内置)
高(独立集群)
近端缓存的优势 :接入简单,自己可以把控缓存使用逻辑。近端缓存的劣势 :广播同步一致性难度大,通信成本高,占用应用内存,无法解决海量数据存储。
远端缓存的优势 :自带广播、同步和共识功能,独立集群有专业运维,适合存储海量数据。远端缓存的劣势 :引入复杂依赖,配置和流程不易差异化。
关于多级缓存
多级缓存(本地 + 远端)的设计需谨慎评估:
可行场景
L1:本地缓存(Caffeine)——存储极热数据
L2:远端缓存(Redis)——存储热数据
差异化 TTL:L1 TTL << L2 TTL
风险点
一致性问题:更新时需要同时失效多个层级
复杂性倍增:每个层级都需要独立的容量规划、监控、故障预案
建议
多数应用从单一远端缓存起步即可
仅在 QPS > 10万且 p99 延迟 < 1ms 为硬性 SLA 时考虑多级缓存
Part 3: 缓存读写策略
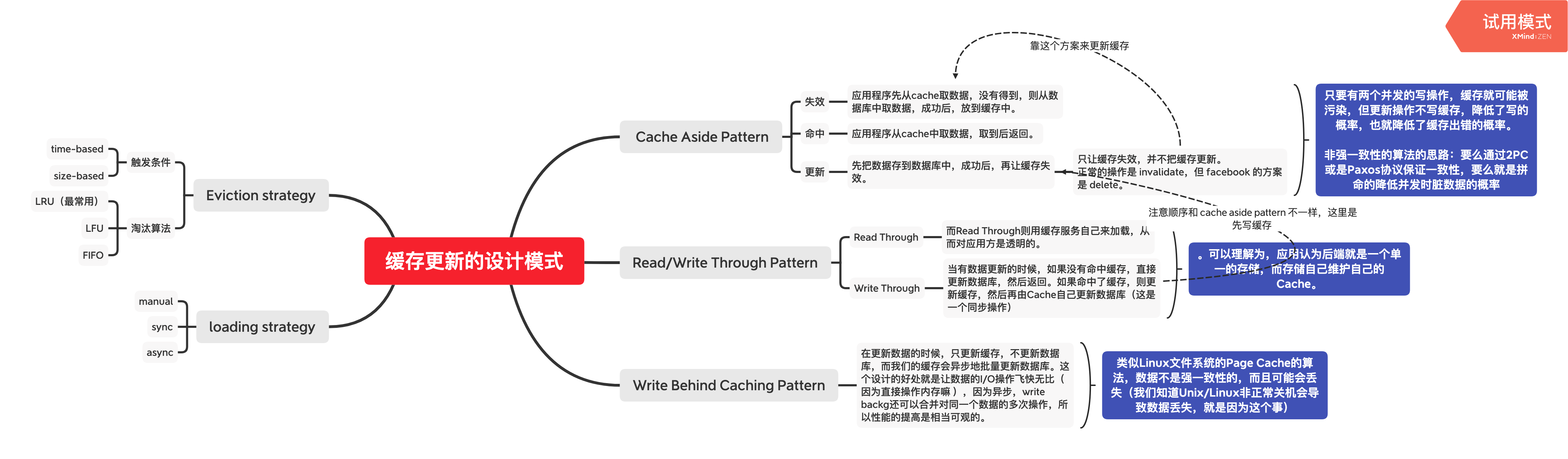
缓存与数据源的一致性维护是核心挑战,业界形成了四种经典模式:
Cache-Aside(旁路缓存)
最常用 的缓存策略,由应用程序显式控制缓存与数据库的交互:
1 2 3 4 5 6 7 8 读取流程:1. 先查缓存2. 缓存命中 → 直接返回3. 缓存未命中 → 查数据库 → 写入缓存 → 返回1. 更新数据库2. 删除缓存(而非更新缓存)
为什么是"删除缓存"而非"更新缓存"?
Update 模式在并发场景下存在竞态条件:
1 2 3 T1: 更新数据库 A =1A =2, 更新缓存 A =2A =1 (覆盖了T2的正确值,导致不一致)
策略
问题
更新缓存 并发写入时可能导致缓存与数据库不一致(后写入数据库的先更新了缓存)
删除缓存 下次读取时重新加载,保证最终一致性
为什么是"先更新数据库,再删除缓存"?
顺序
问题
先删缓存,再更新数据库
删除缓存后、更新数据库前,另一个请求读到旧数据并写入缓存
先更新数据库,再删缓存
更新数据库后、删除缓存前,短暂的不一致(可接受)
Read-Through / Write-Through
缓存层作为数据库的代理,应用只与缓存交互:
1 2 3 4 5 Read - Through :Write - Through :
特点
简化应用逻辑,无需处理缓存细节
强耦合于特定缓存框架
Write-Through 写延迟较高(需等待双写完成)
Write-Behind(异步回写)
写入操作仅更新缓存,由后台线程异步批量刷盘到数据库:
1 应用 → 缓存(立即返回)→ 异步批量写入数据库
优势 :写入延迟极低,可以合并多次写入,降低 DB 压力。劣势 :数据可能丢失(缓存故障时未持久化的数据),实现复杂。
适用场景:计数器、浏览量、点赞数等允许少量丢失的场景。
Refresh-Ahead(预刷新)
在缓存过期之前 ,异步刷新缓存:
1 2 3 4 5 缓存 TTL = 60 秒= TTL × 0.8 = 48 秒48 秒时,异步刷新缓存
优势 :避免缓存过期瞬间的请求穿透。劣势 :实现复杂,可能刷新不再被访问的数据。
策略对比
策略
一致性
读性能
写性能
实现复杂度
Cache Aside
最终一致
高
高
低
Read Through
最终一致
高
-
中
Write Through
强一致
-
低
中
Write Behind
弱一致
-
最高
高
Refresh-Ahead
最终一致
最高
-
高
Part 4: Java 进程内缓存详解
Guava Cache
Guava Cache 是 Google 提供的轻量级缓存库,设计上是对 ConcurrentHashMap 的增强。
核心特性
特性
说明
最大容量限制
基于数量或权重
过期策略
expireAfterWrite / expireAfterAccess
刷新机制
refreshAfterWrite(异步刷新,不阻塞读)
引用类型
支持 weakKeys / weakValues / softValues
统计信息
hit/miss/eviction 计数
基本用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 LoadingCache<String, User> userCache = CacheBuilder.newBuilder()10000 )10 , TimeUnit.MINUTES)1 , TimeUnit.MINUTES) new CacheLoader <String, User>() {@Override public User load (String key) throws Exception {return loadUserFromDatabase(key); User user = userCache.get(userId);
CacheLoader 的 load 方法是原子性的,天然防止并发击穿。
Guava Cache 不支持 null value
Guava Cache 的设计哲学将 null 视为"该 key 无对应数据",因此禁止存入 null。这导致一个实际问题:如何处理缓存穿透?
解决方案是使用 Optional 包装(空对象模式):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static final User EMPTY_USER = new User (); new CacheLoader <String, Optional<User>>() {@Override public Optional<User> load (String key) {User user = loadUserFromDatabase(key);return Optional.ofNullable(user != null ? user : EMPTY_USER);if (result.isPresent() && result.get() != EMPTY_USER) {return result.get();return null ;
允许使用 null 的缓存能够天然抵挡缓存穿透问题,Guava 的缺点就在这里被体现出来了。
Caffeine
Caffeine 是 Guava Cache 的高性能替代品,采用 Window-TinyLFU 淘汰算法,性能显著优于 Guava 的 LRU。
演进关系
1 2 3 4 5 concurrentlinkedhashmap (Ben Manes)Cache (Google)Ben Manes, Java 8 )
Guava vs Caffeine 关键对比
维度
Guava
Caffeine
淘汰算法
Segmented LRU
W-TinyLFU
并发模型
分段锁
无锁 + RingBuffer
刷新机制
同步阻塞
全异步
统计精度
简单计数
频率素描
异步加载示例
1 2 3 4 5 6 7 8 9 10 11 AsyncLoadingCache<String, User> asyncCache = Caffeine.newBuilder()10000 )10 , TimeUnit.MINUTES)10 ))
Caffeine 的 get 类操作具有原子性,保证 function 对每个 key 最多执行一次,可实现线性一致性。
EhCache 3
EhCache 是唯一支持持久化的本地缓存,适合大容量、可容忍磁盘访问延迟的场景。EhCache 3 是 Hibernate 中的默认缓存框架,基于 JSR-107 标准。
堆内外分层配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <config xmlns ="http://www.ehcache.org/v3" > <cache alias ="largeDataCache" > <key-type > java.lang.Long</key-type > <value-type > java.io.Serializable</value-type > <resources > <heap unit ="entries" > 1000</heap > <offheap unit ="MB" > 128</offheap > <disk unit ="GB" > 10</disk > </resources > <expiry > <ttl unit ="minutes" > 60</ttl > </expiry > </cache > </config >
与 Spring Boot 集成
引入依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-cache</artifactId > </dependency > <dependency > <groupId > javax.cache</groupId > <artifactId > cache-api</artifactId > <version > 1.1.1</version > </dependency > <dependency > <groupId > org.ehcache</groupId > <artifactId > ehcache</artifactId > </dependency >
配置类:
1 2 3 4 5 6 7 8 9 10 @Configuration @EnableCaching public class CacheConfig {@Bean public CacheManager cacheManager () {CachingProvider provider = Caching.getCachingProvider();CacheManager manager = provider.getCacheManager();return new JCacheCacheManager (manager);
Part 5: 分布式缓存 Redis
Redis 是目前最流行的分布式缓存,本节聚焦 Java 客户端的最佳实践。
客户端选择
客户端
连接方式
特性
推荐场景
Jedis
直连
成熟稳定,API 丰富
单机或简单分片
Lettuce
Netty + 异步
响应式编程,集群友好
高并发、Reactive
Redisson
高级封装
分布式锁、对象映射
需要分布式协调
Spring Data Redis 配置
1 2 3 4 5 6 7 8 9 10 11 spring: redis: host: localhost port: 6379 lettuce: pool: max-active: 50 max-idle: 20 min-idle: 5 max-wait: 3000ms timeout: 2000ms
缓存序列化配置
默认 JDK 序列化存在性能和空间问题,推荐 JSON 序列化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Bean public RedisTemplate<String, Object> redisTemplate (RedisConnectionFactory factory) {new RedisTemplate <>();new StringRedisSerializer ());new StringRedisSerializer ());new Jackson2JsonRedisSerializer <>(Object.class);ObjectMapper mapper = new ObjectMapper ();new JavaTimeModule ()); return template;
Part 6: 缓存穿透
问题描述
缓存穿透 :查询一个不存在的数据 ,缓存中没有,数据库中也没有。每次请求都会穿透缓存直达数据库。
1 2 3 4 5 攻击者请求 id = -1 的用户users WHERE id = -1 → 空结果
可以针对缓存穿透来刷冷数据,导致整个集群频繁查询冷存储而崩溃。
解决方案一:缓存空值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public User getUser (long userId) {String cacheKey = "user:" + userId;String cached = redis.get(cacheKey);if (cached != null ) {if ("NULL" .equals(cached)) {return null ; return deserialize(cached);User user = userDao.findById(userId);if (user != null ) {3600 , serialize(user)); else {300 , "NULL" ); return user;
注意 :空值的 TTL 应当较短(如 5 分钟),避免数据创建后长时间无法查到。必须有对应的主动更新机制,防止空值被污染。
解决方案二:布隆过滤器
在缓存之前加一层布隆过滤器,快速判断数据是否存在:
1 2 请求 → 布隆过滤器 → 不存在?直接返回 null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class UserService {private final BloomFilter<Long> userIdBloomFilter;public UserService () {this .userIdBloomFilter = BloomFilter.create(10_000_000 , 0.01 public User getUser (long userId) {if (!userIdBloomFilter.mightContain(userId)) {return null ; return getFromCacheOrDb(userId);
解决方案三:参数校验
在入口处进行参数校验,拦截明显非法的请求:
1 2 3 4 5 6 public User getUser (long userId) {if (userId <= 0 ) {throw new IllegalArgumentException ("Invalid user ID: " + userId);return getFromCacheOrDb(userId);
三种方案对比
方案
优势
劣势
适用场景
缓存空值 实现简单
占用缓存空间
空值数量有限
布隆过滤器 空间效率高
有误判率,需要维护
数据集较大
参数校验 零成本
只能拦截明显非法请求
所有场景(基础防线)
Part 7: 缓存击穿
问题描述
缓存击穿 :一个热点 Key 在缓存过期的瞬间,大量并发请求同时穿透到数据库。
1 2 3 4 5 时间线: T0: 热点 Key 过期 T1: 1000 个并发请求同时发现缓存未命中 T2: 1000 个请求同时查询数据库 T3: 数据库被打垮
应对缓存击穿的基本思路:
事前 :在热点数据访问高峰前提前预热;极端热的数据不允许被动失效,必须使用主动更新模式。事中 :严格限制回源流量,引入互斥锁或信号量。事后 :如果系统无法自愈,熔断后手工预热缓存。
解决方案一:互斥锁(Mutex Lock)
只允许一个请求去加载数据,其他请求等待:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public User getUser (long userId) {String cacheKey = "user:" + userId;String cached = redis.get(cacheKey);if (cached != null ) {return deserialize(cached);String lockKey = "lock:user:" + userId;boolean locked = redis.setnx(lockKey, "1" , 10 , TimeUnit.SECONDS);if (locked) {try {if (cached != null ) {return deserialize(cached);User user = userDao.findById(userId);3600 , serialize(user));return user;finally {else {50 );return getUser(userId);
解决方案二:逻辑过期
缓存永不过期,但在值中存储一个逻辑过期时间 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class CacheValue <T> {private T data;private long expireTime; public boolean isExpired () {return System.currentTimeMillis() > expireTime;public User getUser (long userId) {String cacheKey = "user:" + userId;if (cacheValue == null ) {return loadAndCache(userId);if (!cacheValue.isExpired()) {return cacheValue.getData(); String lockKey = "lock:refresh:" + userId;if (redis.setnx(lockKey, "1" , 10 , TimeUnit.SECONDS)) {try {finally {return cacheValue.getData();
解决方案三:热点 Key 永不过期
对于已知的热点 Key,设置永不过期,通过后台任务定期刷新:
1 2 3 4 5 6 7 8 @Scheduled(fixedRate = 30000) public void refreshHotKeys () {for (String key : hotKeys) {Object data = loadFromDb(key);
三种方案对比
方案
一致性
可用性
复杂度
互斥锁 强一致
可能阻塞
中
逻辑过期 最终一致(短暂返回旧数据)
高(不阻塞)
高
永不过期 最终一致
最高
低
Part 8: 缓存雪崩
问题描述
缓存雪崩 :大量缓存 Key 同时过期 ,或者缓存服务整体宕机 ,导致所有请求直达数据库。
1 2 3 4 5 6 7 8 场景一:大量 Key 同时过期 T0 : 系统启动时批量加载缓存,TTL 都设为 1 小时 T0 + 1h : 所有缓存同时过期,数据库瞬间承受全部流量 场景二:Redis 宕机 T0 : Redis 集群故障 T1 : 所有请求直达数据库 T2 : 数据库被打垮,整个系统不可用
从某种意义上,单一缓存的击穿并不可怕,缓存雪崩才是最可怕的。应对策略是大规模使用击穿防护的基础上,把缓存预热和失效行为打散。
解决方案一:随机 TTL
给 TTL 加上随机偏移,避免同时过期:
1 2 3 4 5 6 7 8 public void setWithRandomTtl (String key, String value, int baseTtlSeconds) {int randomOffset = ThreadLocalRandom.current().nextInt(baseTtlSeconds / 5 );int actualTtl = baseTtlSeconds + randomOffset;"user:1001" , userData, 3600 );
对于定时任务刷新的场景,采用阶梯过期 :将数据分批,每批在不同时间点刷新。
解决方案二:多级缓存
1 请求 → L1 本地缓存(Caffeine)→ L2 分布式缓存(Redis)→ 数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class MultiLevelCache {private final Cache<String, Object> localCache; private final RedisTemplate<String, Object> redis; public MultiLevelCache () {this .localCache = Caffeine.newBuilder()10_000 )5 , TimeUnit.MINUTES)public Object get (String key) {Object value = localCache.getIfPresent(key);if (value != null ) return value;if (value != null ) {return value;if (value != null ) {1 , TimeUnit.HOURS);return value;
解决方案三:熔断降级
当数据库压力过大时,启动熔断保护:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @HystrixCommand( fallbackMethod = "getUserFallback", commandProperties = { @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"), @HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50") } ) public User getUser (long userId) {return userDao.findById(userId);public User getUserFallback (long userId) {return User.defaultUser();
解决方案四:Redis 高可用
部署模式
说明
可用性
主从复制 一主多从,读写分离
中
Sentinel 自动故障转移
高
Cluster 分片 + 副本
最高
Part 9: 缓存与数据库一致性
延迟双删
问题 :在 Cache Aside 模式下,先删除缓存再更新数据库,在更新完成之前,如果有读请求进来,会读取到旧数据并写入缓存,导致不一致。
解决方案 :延迟双删策略通过在数据库更新后再次删除缓存来解决这个问题。
1 2 3 4 5 6 7 8 9 10 11 12 public void updateUser (User user) {"user:" + user.getId());"user:" + user.getId());500 , TimeUnit.MILLISECONDS);
时序分析 :
最佳实践 :
延迟时间应大于数据库主从同步延迟 + 业务读请求平均耗时
建议延迟时间设置为 500ms-2s
配合消息队列实现异步删除,避免线程阻塞
强一致性:分布式锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public User getUser (long userId) {String lockKey = "lock:user:" + userId;RLock lock = redisson.getLock(lockKey);try {String cached = redis.get("user:" + userId);if (cached != null ) return deserialize(cached);User user = userDao.findById(userId);"user:" + userId, 3600 , serialize(user));return user;finally {public void updateUser (User user) {String lockKey = "lock:user:" + user.getId();RLock lock = redisson.getLock(lockKey);try {"user:" + user.getId());finally {
代价 :性能下降(所有读写都需要获取锁)。只适用于对一致性要求极高的场景。
Canal/Binlog 方案
通过监听 MySQL Binlog,异步更新缓存,实现应用代码无侵入的最终一致性。
1 2 3 4 5 6 7 8 9 应用 → 数据库(写入)/ Debezium(监听 Binlog)/ 删除缓存)
架构图 :
Canal 工作原理 :
Canal 模拟 MySQL Slave 的交互协议
监听 MySQL Binlog,解析数据变更事件
将变更事件推送到消息队列(Kafka/RocketMQ)
消费者接收事件并执行缓存失效操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Component public class CanalCacheInvalidator {@KafkaListener(topics = "canal-binlog") public void handleBinlogEvent (BinlogEvent event) {if (event.getDatabase().equals("mydb" ) && event.getTable().equals("user" )) {Long userId = extractUserId(event.getData());"user:" + userId);"cache:invalidate" , "user:" + userId);
优势 :保证最终一致性(延迟通常 < 100ms),解耦业务代码和缓存逻辑,支持多级缓存统一失效。劣势 :架构复杂度高,有一定延迟(通常 < 1 秒)。
Facebook Memcache Lease 机制
Facebook 在其 Memcache 论文中提出了 Lease 机制,防止多个客户端同时在缓存未命中时给数据库施加压力:
Lease 机制的核心思想是:缓存服务器在返回 miss 时附带一个 lease token,只有持有有效 lease 的客户端才能写入缓存,其他客户端需要等待或重试。
Part 10: 分布式锁
Redis 分布式锁实现
基本实现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public boolean tryLock (String lockKey, String requestId, int expireSeconds) {String result = redis.set(lockKey, requestId, "NX" , "EX" , expireSeconds);return "OK" .equals(result);public boolean unlock (String lockKey, String requestId) {String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then " +" return redis.call('del', KEYS[1]) " +"else " +" return 0 " +"end" ;Long result = redis.eval(luaScript, Collections.singletonList(lockKey),return result == 1L ;
SET NX EX 的引入背景
在 Redis 2.6.12 版本之前,实现分布式锁需要使用 SETNX + EXPIRE 两条命令,这两个操作之间无法保证原子性——如果 SETNX 成功后、EXPIRE 执行前进程崩溃或网络中断,锁将永久存在。
Redis 2.6.12 引入了 SET 命令的扩展参数,支持原子性加锁:
1 SET lock_key "request_id" NX EX 30
NX:仅在 key 不存在时设置(等同于 SETNX)EX:设置过期时间(秒)整个操作是原子的,要么全部成功,要么全部失败
解锁使用 Lua 脚本的原因 :如果用 GET + DEL 两步操作,在 GET 和 DEL 之间锁可能已经过期并被其他线程获取,DEL 会错误地删除别人的锁。Lua 脚本在 Redis 中是原子执行的。
锁续期(Watchdog)
如果业务执行时间超过锁的过期时间,锁会自动释放,导致并发问题。Redisson 的 Watchdog 机制:
1 2 3 4 1. 加锁时设置 TTL = 30 秒2. 启动一个后台线程(Watchdog),每 10 秒检查一次3. 如果锁仍然被持有,续期到 30 秒4. 如果持有锁的线程崩溃,Watchdog 也会停止,锁自然过期
实现细节 :
Watchdog 基于 Netty 的 HashedWheelTimer 定时器实现
续期操作通过 Lua 脚本原子性执行:pexpire key 30000
只有锁的持有者才能续期,通过比对 requestId 防止误续期
续期失败时会重试,最多重试 3 次,失败后停止续期
RedLock 算法
单 Redis 实例的分布式锁在 Redis 故障时不可靠。RedLock 使用多个独立的 Redis 实例:
1 2 3 4 5 1. 获取当前时间 T12. 依次向 N 个 Redis 实例尝试加锁(超时时间很短)3. 如果在超过 N/2 + 1 个实例上加锁成功,且总耗时 < 锁的 TTL4. 则认为加锁成功,锁的有效时间 = TTL - 加锁耗时5. 否则,向所有实例发送解锁请求
争议 :Martin Kleppmann 指出 RedLock 在某些故障场景下仍然不安全(如时钟跳变)。对于强一致性需求,应使用 ZooKeeper 或 etcd。
Part 11: 热点 Key 与大 Key 治理
热点 Key 问题
定义 :某个 Key 被大量请求访问(如微博热搜、秒杀商品),单个 Redis 节点承受不住。
危害 :
单节点 CPU/内存资源耗尽
网络带宽瓶颈
影响其他 Key 的访问性能
可能导致整个缓存集群不可用
热点探测方案
方案
实现
优势
客户端统计 在应用中统计 Key 的访问频率
实时性好
Redis 监控 redis-cli --hotkeys(基于 LFU)无侵入
代理层统计 在 Redis 代理(如 Twemproxy)中统计
全局视角
京东 HotKey 框架
热 Key 治理方案
方案一:本地缓存兜底
将热点 Key 缓存在应用本地,减少对 Redis 的访问:
1 2 3 4 5 6 7 8 private final Cache<String, Object> hotKeyCache = Caffeine.newBuilder()1000 )1 , TimeUnit.SECONDS) public Object getHotKey (String key) {return hotKeyCache.get(key, k -> redis.get(k));
方案二:Key 分片
将一个热点 Key 拆分为多个 Key,分散到不同的 Redis 节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public Object getHotKey (String key) {int shard = ThreadLocalRandom.current().nextInt(10 );String shardKey = key + ":shard:" + shard;Object value = redis.get(shardKey);if (value != null ) return value;for (int i = 0 ; i < 10 ; i++) {":shard:" + i, 3600 , serialize(value));return value;
方案对比 :
方案
优点
缺点
适用场景
本地缓存
响应快,减轻 Redis 压力
数据不一致,内存占用大
读多写少,一致性要求不高
Key 分散
负载均衡,无单点
读取复杂,可能读到旧数据
写多读少,可接受最终一致
大 Key 问题
大 Key 的定义
类型
大 Key 定义
String
值大小 > 10KB
Hash
字段数 > 5000
List
元素数 > 5000
Set
元素数 > 5000
Sorted Set
元素数 > 5000
危害 :网络带宽占用、内存碎片、慢查询阻塞、主从同步延迟、DEL 等命令可能阻塞 Redis。
发现手段
1 2 3 4 5
治理方案
拆分大 Hash :将大 Hash 按字段哈希拆分为多个小 Hash:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public void splitBigHash (String bigKey) {int shardIndex = 0 ;new HashMap <>();for (Map.Entry<String, String> entry : bigHash.entrySet()) {if (shard.size() >= MAX_HASH_SIZE) {String shardKey = bigKey + ":" + shardIndex;if (!shard.isEmpty()) {":" + shardIndex, shard);
异步删除 :使用 UNLINK 替代 DEL,避免阻塞 Redis 主线程。
压缩存储 :对大 Value 使用 Deflater/Inflater 进行压缩后再存入 Redis,可显著减少网络传输和内存占用。
Part 12: 多级缓存架构实战
经典三级架构
每一层的职责是"挡住上一层的穿透",TTL 必须逐层递增,否则失去分层意义。
JetCache 框架
JetCache 是阿里开源的多级缓存框架,内置 L1 + L2 支持:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Service public class JetCacheUserService {@CreateCache(name = "userCache", expire = 3600, cacheType = CacheType.BOTH, localLimit = 1000) private Cache<Long, User> userCache;@Cached(name = "userCache:", key = "#userId", expire = 3600) public User getUserById (Long userId) {return userRepository.findById(userId);@CacheInvalidate(name = "userCache:", key = "#userId") public void deleteUser (Long userId) {@Cached(name = "userCache:", key = "#userId", expire = 3600) @CacheRefresh(refreshInterval = 60, stopRefreshAfterLastAccess = 3600) public User getHotUserById (Long userId) {return userRepository.findById(userId);
缓存失效广播方案
多级缓存的一致性挑战在于:当数据更新时,需要同时失效 L1(本地缓存)和 L2(Redis)。L2 直接 DEL 即可,L1 则需要通过 Redis Pub/Sub 或消息队列通知所有应用实例。
1 2 3 4 5 6 7 8 9 10 public class CacheInvalidationService {private RedisTemplate<String, String> redisTemplate;public void publishInvalidation (String cacheKey) {"cache:invalidation" , cacheKey);
预热策略对比
策略
优点
缺点
适用场景
全量预热
启动后立即可用
耗时长,占用资源
数据量小,启动时间不敏感
增量预热
快速启动
可能缓存穿透
数据量大,可接受渐进式加载
懒加载
无需预热
首次访问慢
数据量大,访问模式不确定
预热实施要点:
数据源选择 :基于历史访问日志、业务规则或人工配置确定热点数据分批加载 :避免启动时瞬时压力过大,使用线程池分批加载失败重试 :预热失败时记录日志并异步重试,不影响系统启动灰度预热 :对于大规模数据,可采用渐进式预热策略预热验证 :预热完成后进行命中率验证,确保数据完整性
Part 13: Redis 集群缓存设计
CRC16 + 16384 Slots 原理
Redis Cluster 使用 CRC16 算法对 key 进行哈希,计算结果对 16384 取模,确定 key 所在的 slot。每个节点负责一部分 slot,实现数据分片。
在 Redis Cluster 中,不支持跨 slot 的多 key 操作 (如 MGET、MSET、SUNION 等)。
HashTag 使用
使用 HashTag 可以确保相关 key 路由到同一个 slot:
1 2 3 {user:1001 }:profile → 按 "user:1001" 计算 slot1001 }:orders → 按 "user:1001" 计算 slot
最佳实践 :
只在需要多 key 原子操作时使用 HashTag
HashTag 会破坏数据分布均匀性,不要滥用
HashTag 应该是业务相关的标识,如用户 ID、订单 ID
Sentinel vs Cluster 选型
特性
Redis Sentinel
Redis Cluster
数据分片
否
是(16384 slots)
水平扩展
需要客户端分片
原生支持
最大内存
单节点限制
集群总内存
故障转移
自动
自动
复杂度
较低
较高
多 key 操作
支持
受限(需 HashTag)
适用场景
中小规模,简单架构
大规模,高性能需求
Part 14: 生产环境实践
监控指标
指标
健康阈值
报警条件
命中率
> 90%
< 80%
平均加载时间
< 100ms
> 500ms
驱逐率
视容量而定
突增 > 200%
错误率
0%
> 0.1%
容量规划
估算公式:
1 缓存条目数 ≈ 峰值 QPS × 平均访问间隔 / (命中率目标 / (1 - 命中率目标))
示例:QPS=10000,用户平均10分钟访问一次,目标命中率95%:
1 条目数 ≈ 10000 × 600 s × (0.05/0.95 ) ≈ 315,789
故障演练清单
[ ] 模拟 Redis 宕机,验证降级逻辑
[ ] 模拟大 Key 过期,观察数据库压力
[ ] 模拟网络分区,测试最终一致性收敛时间
[ ] 压测缓存满载时的驱逐行为
缓存更新的最佳实践
场景
推荐策略
读多写少 Cache-Aside + 延迟双删
读多写多 Write-Through + 短 TTL
写多读少 Write-Behind(异步写回)
强一致性 分布式锁 或 Binlog 同步
热点数据 本地缓存 + Key 分片
Part 15: 模式速查表
听到的需求关键词
对应模式
推荐方案
口诀
本地缓存要高性能
分层降级
Caffeine + Redis
本地兜底,远程扩展
冷启动加载慢
惰性填充
@PostConstruct 预加载
触发加载,按需扩容
数据更新后不一致
旁路同步
Cache Aside + 延迟双删
先库后删,读写互斥
恶意请求导致 DB 崩溃
空值防御
空对象 + 布隆过滤器
存空防击,短TTL控险
大量 key 同时过期
随机散列
TTL + Random Offset
过期分散,渐进刷新
热点 key 频繁失效
互斥重建
分布式锁 / 逻辑过期
单线回源,排队等待
核心设计原则 :
缓存是加速手段,不是数据源 ——数据库才是 Source of Truth接受最终一致性 ——追求强一致性的代价通常过高防御性设计 ——假设缓存随时可能失效,系统仍能工作监控先行 ——命中率、延迟、内存使用是核心指标
问题
原因
核心解决方案
缓存穿透 查询不存在的数据
缓存空值 + 布隆过滤器
缓存击穿 热点 Key 过期
互斥锁 + 逻辑过期
缓存雪崩 大量 Key 同时过期 / Redis 宕机
随机 TTL + 多级缓存 + 熔断
缓存一致性 缓存与数据库数据不同步
延迟双删 + Binlog 同步
热点 Key 单 Key 访问量过大
本地缓存 + Key 分片
参考文献
陈皓:缓存更新的套路 美团技术团队:缓存那些事 Guava Cache 官方文档 Caffeine Wiki Redis 官方文档 Canal - 阿里巴巴 MySQL Binlog 增量订阅 Martin Kleppmann - How to do distributed locking Designing Data-Intensive Applications - Martin Kleppmann Guava Cache (Baeldung) Caffeine vs EhCache Spring Cache SPEL 表达式