JVM 的内存模型与线程
JVM 的内存模型与线程
Java 内存模型(Java Memory Model, JMM)定义了多线程环境下共享变量的访问规则,是理解并发编程的基石。本文从硬件架构出发,逐步深入到 JMM 的核心机制与实践模式。
mindmap
root((JMM))
硬件基础
CPU缓存层次
缓存一致性协议
JMM 抽象
主内存 vs 工作内存
八种内存操作
happens-before 关系
关键保证
原子性
可见性
有序性
实践工具
volatile
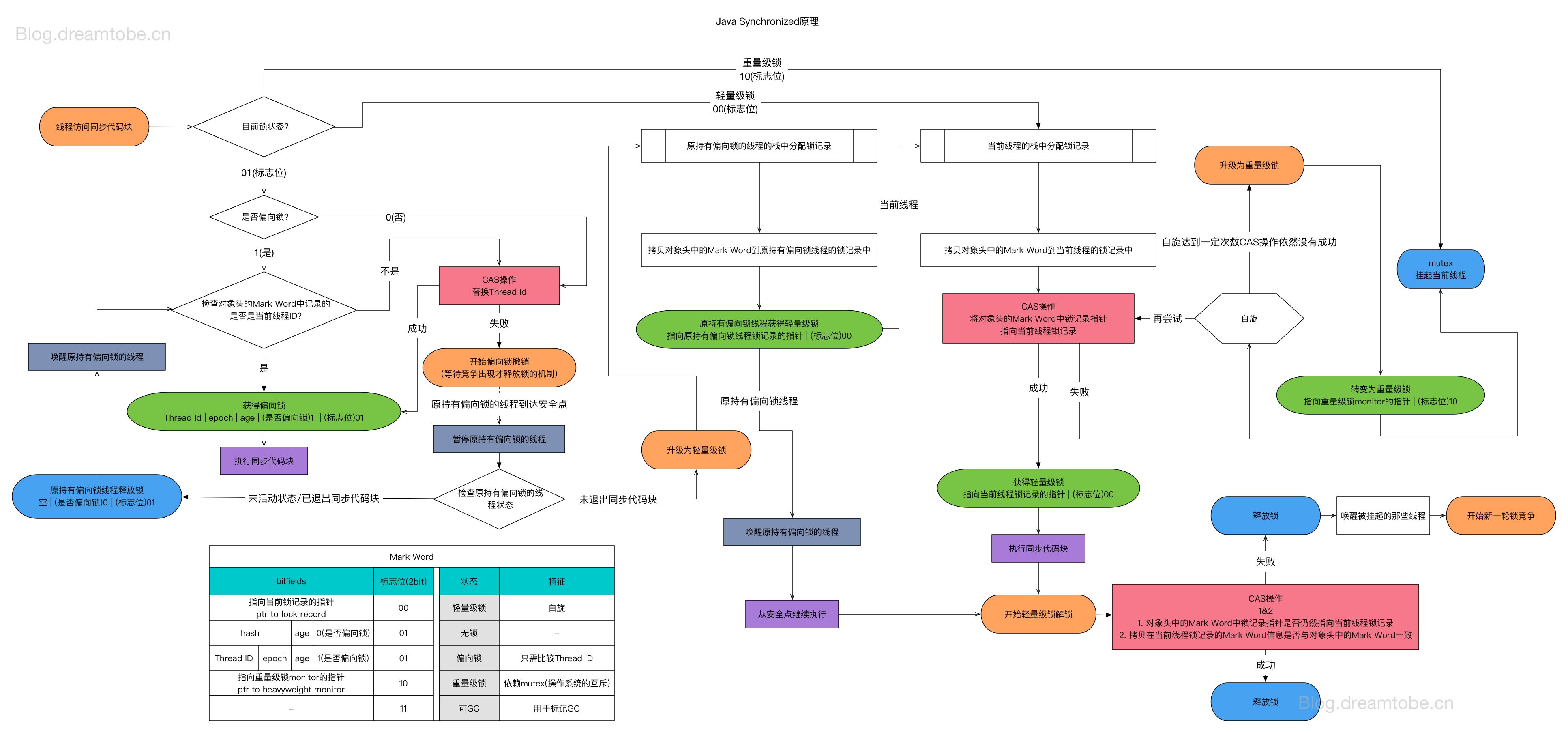
synchronized
final模式总览
| # | 模式名称 | 一句话口诀 | 适用场景 |
|---|---|---|---|
| 1 | 写刷读清 | 写入即刷盘,读取先清空 | volatile / unlock 后的可见性 |
| 2 | 顺序锁 | 同把锁内,串行执行 | synchronized 临界区保护 |
| 3 | 偏序传递 | A先于B,B先于C,则A先于C | happens-before 链式推理 |
| 4 | 不可变安全 | 构造完成前不逃逸,完成后不修改 | final 字段的安全发布 |
一、从硬件到抽象:为什么需要 JMM
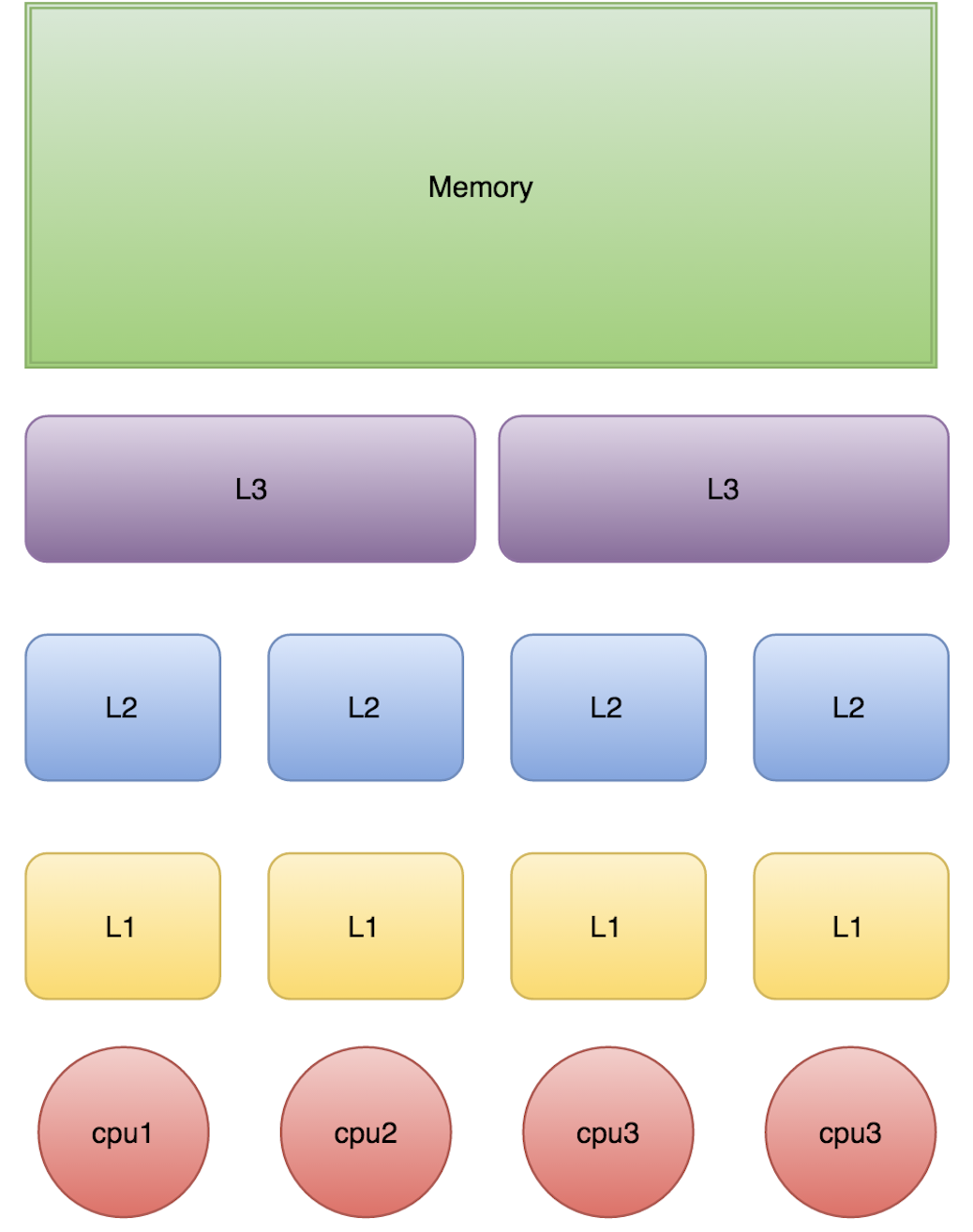
1.1 CPU 架构的性能鸿沟
现代 CPU 的处理速度远超主内存(DRAM)的响应能力。以 Intel Skylake 架构为例:
| 层级 | 典型延迟 | 容量范围 |
|---|---|---|
| L1 Cache | ~4 cycles | 32KB |
| L2 Cache | ~12 cycles | 256KB |
| L3 Cache | ~40 cycles | 8-32MB |
| 主内存 | ~200+ cycles | GB 级 |
这种数量级的差异迫使 CPU 引入多级缓存。但缓存带来了新的问题:多个处理器的缓存如何保持一致?
1.2 缓存一致性协议(MESI)
现代处理器使用 MESI 协议维护缓存一致性,其四个状态为:
| 状态 | 含义 | 说明 |
|---|---|---|
| Modified | 已修改 | 仅当前缓存拥有该数据,且与内存不一致 |
| Exclusive | 独占 | 仅当前缓存拥有该数据,与内存一致 |
| Shared | 共享 | 多个缓存拥有该数据,与内存一致 |
| Invalid | 失效 | 当前缓存该数据无效,需重新加载 |
状态转换示意:
1 | |
1.3 为何需要 JMM
硬件层面的缓存一致性由处理器自动保证,但这对上层程序员是不透明的。编译器和运行时可能进行以下优化:
- 编译器重排序:不改变单线程语义的前提下调整指令顺序
- 处理器乱序执行:利用流水线并行执行无依赖的指令
- 缓存可见性延迟:写操作对其他 CPU 立即可见并非保证
JMM 的作用是在这些底层优化之上,提供一个可预测的编程模型,明确告知程序员什么情况下可以安全地推断多线程间的执行顺序。
二、JMM 核心抽象
2.1 主内存与工作内存
JMM 定义了一套抽象的内存模型(JLS §17.4):
- 主内存(Main Memory):所有变量存储的地方,对应物理内存
- 工作内存(Working Memory):每个线程私有的缓存区域,对应 CPU 寄存器 + L1/L2/L3 缓存
线程对变量的所有操作必须在工作内存中进行,不能直接读写主内存。
1 | |
2.2 八种内存操作(JLS §17.4.1)
JMM 定义了 8 种原子操作描述主内存与工作内存的交互:
| 操作 | 作用域 | 说明 |
|---|---|---|
lock |
主内存 | 将变量标记为线程独占状态 |
unlock |
主内存 | 释放变量的线程独占状态 |
read |
主内存→工作内存 | 将变量值从主内存传输到工作内存 |
load |
工作内存 | 将 read 的值放入工作内存副本 |
use |
工作内存→执行引擎 | 将变量值传递给执行引擎 |
assign |
执行引擎→工作内存 | 将执行结果赋值给工作内存变量 |
store |
工作内存→主内存 | 将变量值从工作内存传输到主内存 |
write |
主内存 | 将 store 的值写入主内存变量 |
基本执行约束(JLS §17.4.2):
read与load必须按顺序执行,但可不连续(中间可插入其他指令)store与write必须按顺序执行,但可不连续- 不允许丢弃最近的
assign,变量改变必须同步回主内存 - 新变量只能在主内存诞生,不可直接使用未初始化变量
典型的完整操作序列:
1 | |
2.3 指令重排序
2.3.1 重排序的本质
指令重排序是编译器和处理器为了提升性能而进行的优化手段。其核心原则是:
As-If-Serial 语义:在单线程环境下,重排序后的执行结果与顺序执行的结果完全一致。
这意味着重排序不会改变单线程的正确性,但无法保证多线程间的可见性和有序性。
2.3.2 重排序的三个层次
| 层次 | 执行主体 | 重排序类型 | 示例 |
|---|---|---|---|
| 编译器重排序 | JIT 编译器 | 调整字节码指令顺序 | 循环展开、公共子表达式消除 |
| 处理器重排序 | CPU 硬件 | 乱序执行(Out-of-Order Execution) | 指令级并行、流水线优化 |
| 内存系统重排序 | 缓存系统 | 改变写操作的可见顺序 | Store Buffer 延迟写入 |
2.3.3 重排序示例
编译器重排序示例:
1 | |
处理器重排序示例:
1 | |
多线程环境的问题:
在多线程环境下,重排序会导致不可预测的执行结果:
1 | |
2.3.4 重排序的代价与收益
| 收益 | 代价 |
|---|---|
| 提升单线程性能 10%-30% | 多线程下需要同步机制 |
| 更好的流水线利用率 | 增加编程复杂度 |
| 减少缓存未命中 | 需要理解 happens-before 规则 |
2.3.5 JMM 的应对:内存屏障
JMM 通过插入**内存屏障(Memory Barrier)**来禁止特定类型的重排序:
| 屏障类型 | 禁止的重排序 | 典型使用场景 |
|---|---|---|
| LoadLoad | Load1; LoadLoad; Load2 → 禁止 Load1 和 Load2 重排 | volatile 读 |
| StoreStore | Store1; StoreStore; Store2 → 禁止 Store1 和 Store2 重排 | volatile 写 |
| LoadStore | Load1; LoadStore; Store2 → 禁止 Load1 和 Store2 重排 | synchronized |
| StoreLoad | Store1; StoreLoad; Load2 → 禁止 Store1 和 Load2 重排 | volatile 写(开销最大) |
核心洞察:指令重排序是系统"自私"的优化——只考虑自身的执行效率,不顾及其他线程的观测。JMM 通过 happens-before 规则为这种"自私"行为划定了边界。
三、happens-before 关系
3.1 什么是 happens-before
happens-before 是 JMM 定义的偏序关系(JLS §17.4.5)。若操作 A happens-before 操作 B,则 A 的结果对 B 可见,且 A 在 B 之前执行。
注意:happens-before 不等于时间上的先后,而是指可见性保证。如果 A 不在 B 的 happens-before 链中,即使 A 实际先执行,B 也可能看不到 A 的结果。
3.2 happens-before 的八条规则
| 规则 | 内容 | JLS 引用 |
|---|---|---|
| 程序次序规则 | 单线程内,书写在前面的操作 happens-before 后面的操作 | §17.4.5 |
| 监视器锁定规则 | unlock 操作 happens-before 后面对同一锁的 lock 操作 | §17.4.5 |
| volatile 规则 | volatile 写操作 happens-before 后面对该变量的读操作 | §17.4.5 |
| 线程启动规则 | Thread.start() happens-before 线程内的每个动作 | §17.4.5 |
| 线程终止规则 | 线程内所有操作 happens-before 线程终止检测 | §17.4.5 |
| 线程中断规则 | interrupt() 调用 happens-before 被中断线程检测到中断 | §17.4.5 |
| 对象终结规则 | 构造函数结束 happens-before finalize() 开始 | §17.4.5 |
| 传递性 | A happens-before B 且 B happens-before C,则 A happens-before C | §17.4.5 |
3.3 推导示例
示例 1:synchronized 保证可见性
1 | |
推导链:
- A happens-before B(程序次序规则)
- B happens-before C(监视器锁定规则:unlock happens-before 后续 lock)
- C happens-before D(程序次序规则)
- 因此 A happens-before D(传递性),线程2 能看到 x=1
示例 2:volatile 的正确使用姿势
1 | |
推导链:
- A happens-before B(程序次序规则)
- B happens-before C(volatile 规则)
- C happens-before D(程序次序规则)
- 因此 A happens-before D,线程B 能看到 value=42
示例 3:Future.get() 的内存可见性保证
ExecutorService 提交任务后,调用线程通过 Future.get() 获取结果时,JMM 保证任务执行线程的所有写操作对调用线程可见:
-
happens-before 传递链:
- 任务执行线程对共享变量的写操作 happens-before FutureTask.set(result)
- FutureTask.set(result) happens-before state的volatile写(NORMAL/EXCEPTIONAL状态)
- state的volatile写 happens-before Future.get()中对state的volatile读
- 传递性:任务执行的所有操作 happens-before Future.get()的返回
-
实际调用链中的happens-before关系:
1
2
3
4
5
6executor.execute(task)
→ Worker线程执行task.run()
→ callable.call()的所有写操作
→ FutureTask状态转换(volatile写)
→ future.get()读取结果(volatile读)
→ 调用线程可见所有之前的写操作 -
关键规范依据:
- 程序顺序规则(JLS §17.4.3):同一线程内,前面的操作happens-before后面的操作
- volatile变量规则(JLS §17.4.4):volatile写happens-before后续的volatile读
- 传递性规则(JLS §17.4.5):A happens-before B,B happens-before C,则A happens-before C
理解 happens-before 关系应从 JLS 规范出发,而非硬件层面的 flushing model(参见 [Flushing model is fundamentally flawed][10])。
四、三大特性保障
4.1 原子性(Atomicity)
JMM 保证基本类型的读写操作是原子的(long/double 在某些平台可能非原子,但 JVM 实现通常保证)。
原子操作类型:
- read、load、use、assign、store、write(对 32 位及以下类型)
- lock、unlock
非原子场景:
1 | |
4.2 可见性(Visibility)
一个线程修改共享变量后,其他线程能够立即看到这个修改。
保证可见性的方式:
| 方式 | 机制 |
|---|---|
volatile |
每次写立即刷新到主内存,每次读从主内存刷新 |
synchronized |
unlock 时 flush 工作内存到主内存;lock 时清空工作内存并重新加载 |
final |
正确构造的对象,其 final 字段对所有线程可见(无额外同步成本) |
volatile 的实现细节:
1 | |
volatile 写操作在 x86 平台上对应 lock addl $0x0 指令,起到两个作用:
- 将当前处理器的缓存行写回内存
- 使其他处理器的该缓存行无效
4.3 有序性(Ordering)
禁止特定类型的指令重排序,确保程序的执行顺序符合预期。
内存屏障(Memory Barrier)类型:
| 屏障类型 | 示例指令 | 作用 |
|---|---|---|
| LoadLoad | Load1; LoadLoad; Load2 | 禁止 Load1 和 Load2 重排序 |
| StoreStore | Store1; StoreStore; Store2 | 禁止 Store1 和 Store2 重排序 |
| LoadStore | Load1; LoadStore; Store2 | 禁止 Load1 和 Store2 重排序 |
| StoreLoad | Store1; StoreLoad; Load2 | 禁止 Store1 和 Load2 重排序(开销最大) |
volatile 的内存屏障插入策略(JSR-133 增强后):
- volatile 写:前面插入 StoreStore,后面插入 StoreLoad
- volatile 读:后面插入 LoadLoad 和 LoadStore
这确保了:
- volatile 写之前的写操作不会被重排到后面
- volatile 读之后的读/写操作不会被重排到前面
五、对象内存布局与指针压缩
5.1 对象的内存结构
HotSpot JVM 中,对象在内存中的布局如下:
1 | |
5.2 Mark Word 的结构
Mark Word 是一个动态数据结构,根据对象状态复用存储空间:
1 | |
5.3 指针压缩(Compressed OOPs)
64 位 JVM 默认开启指针压缩(-XX:+UseCompressedOops),将 64 位引用压缩为 32 位:
- 堆内存 < 4GB:直接位移,无需解码
- 4GB ≤ 堆内存 < 32GB:基址 + 偏移(默认策略)
- ≥ 32GB:无法压缩,回退到 64 位指针
计算公式:
1 | |
启用压缩指针后,对象头的 Class Pointer 从 8 字节降为 4 字节,显著降低内存占用。
六、🔑 模式提炼
模式一:写刷读清
公式:Assign → Store → Write (Flush) || Read → Load → Use (Refresh)
应用场景
| 场景 | Flush 触发点 | Refresh 触发点 | 效果 |
|---|---|---|---|
| volatile 写 | 写后立即 store+write | - | 对所有后续读者可见 |
| synchronized 解锁 | unlock 前 flush | lock 时 refresh | 临界区变更对后续获取者可见 |
| 线程终止 | 线程结束 | join() 返回 | 线程内所有操作对等待者可见 |
核心洞察:可见性问题的本质是"何时把工作内存的脏页刷到主内存",以及"何时废弃本地缓存重新加载"。happens-before 规则就是定义这两个动作的触发时机。
模式二:顺序锁
公式:Lock(A) → { Critical Section } → Unlock(A) 串行化所有临界区
[概念辨析] 关于临界区、同步块与锁保护区域的详细辨析,请参阅 《线程安全与锁优化》 一文中的"临界区、同步块与锁保护区域"章节。
实现机制
1 | |
关键要点
- 锁对象是 monitor 的载体,空对象不能作为锁
- 异常退出时仍保证 monitorexit 执行(try-finally 语义)
- 锁升级路径:无锁 → 偏向锁 → 轻量级锁 → 重量级锁
模式三:偏序传递
公式:A ≺ B ∧ B ≺ C ⇒ A ≺ C
推理链构建示例
1 | |
推导:
- A happens-before B(程序次序)
- B happens-before C(volatile规则)
- 构造函数结束 happens-before finalize(对象终结规则,这里隐含构造完成 happens-before 任何引用获取)
- 因此 A happens-before C,进而 A happens-before D
实践价值:正确使用 volatile/final/synchronized 建立 happens-before 链,可以在无锁的情况下实现线程安全的可见性保障。
七、生产环境实践要点
7.1 volatile 的捎带同步(Piggybacking)
volatile 变量最重要的隐含语义是捎带同步:
线程 A 写 volatile 变量之前的所有写操作,对随后读取该 volatile 变量的线程 B 可见。
这不是 volatile 的「额外功能」,而是 happens-before 传递性的必然结果:
1 | |
典型应用:用一个 volatile 变量「捎带」保证多个非 volatile 变量的可见性,如 FutureTask 用 volatile int state 保证 Object outcome 和 Callable callable 的可见性。
设计原则(volatile 守卫模式):
只需一个 volatile 状态变量,保证它最后被写、最先被读即可守护多个非 volatile 字段的可见性。
1 | |
7.2 volatile 的使用原则
适合场景
- 状态标志位(如
boolean running = true) - 单次写多次读的共享变量
- 配合 synchronized 实现细粒度锁(如 StampedLock 的乐观读)
避免场景
- 复合操作(i++、检查再执行)
- 多个 volatile 变量间的依赖(不能保证整体原子性)
7.3 双重检查锁定的正确实现
Java 5 之前的 DCL 是错的,因为 volatile 不能保证有序性。JSR-133 修复后:
1 | |
不使用 volatile 的风险:线程A 执行到第3步(引用已赋值但未初始化),线程B 判断 instance != null 直接返回未初始化对象。
7.4 伪共享(False Sharing)问题
当两个独立变量位于同一缓存行(通常 64 字节)时,一个线程修改变量A会导致另一个线程的变量B缓存失效。
1 | |
Java 8 引入 @Contended 注解自动处理:
1 | |
7.5 监控与诊断
JVM 参数
| 参数 | 作用 |
|---|---|
-XX:+PrintAssembly |
打印 JIT 生成的汇编代码(需 hsdis) |
-XX:CompileCommand=print,*ClassName.methodName |
指定方法打印汇编 |
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation |
记录编译日志 |
jol(Java Object Layout)工具
1 | |
八、模式速查表
| 遇到的问题 | 应用的模式 | 具体方案 | 关键注意点 |
|---|---|---|---|
| 一个线程的修改对另一个不可见 | 写刷读清 | volatile / synchronized | volatile 只保证单次读写可见 |
| 复合操作结果错乱 | 顺序锁 | synchronized / Lock | 锁粒度尽可能小 |
| 多变量间可见性推理 | 偏序传递 | 建立 happens-before 链 | 确保链条完整,无断点 |
| 对象安全发布 | 不可变安全 | final + 正确构造 | this 引用不要在构造函数逸出 |
| 高并发下锁竞争激烈 | 锁优化 | 偏向锁 → 轻量级锁 → 分段锁 | JDK 15+ 默认禁用偏向锁 |
参考文献
- Java Language Specification, Chapter 17.4 - JMM 官方规范
- JSR-133: Java Memory Model and Thread Specification - 内存模型修订文档
- 《Java 并发编程实战》Brian Goetz 等著
- Mechanical Sympathy Blog - False Sharing
3.JVM 的对象信息
Java Object 除了基本的内存轮廓以外,还有:
- Mark Word(对象的 Hash Code 的缓存值、GC标志、GC年龄、同步锁等信息)。
- Klass Point(指向对象元数据信息的指针,指向 .class 的指针吗?不是,是指向方法区的类型元数据的指针。.Class文件实际上是那个区域的另一个入口了。)。
- padding。如果对象是8位对齐的(也就是最长标量类型对齐的),则不存在padding。
4.内存间(主内存与工作内存)相互操作
Java内存模型(Java Memory Model)定义了八种内存操作(而不是字节码)。虚拟机在是现实必须保证每一种操作都是原子的、不可再分的(对于 double 和 long 类型的变量来说,load、store、read 和 write 操作在某些平台上可以例外):
- lock 把主内存变量为一个线程锁定起来。
- unlock 把主内存的变量解锁,这样其他线程才能锁定。
- read 把一个变量的值,从主内存读到工作内存里。是 load 指令的前置动作。
- load 把read出来的变量,放到工作内存的副本里。
- use 把工作内存的值传给工作执行引擎。
- assign 把执行引擎里得到的值传给工作内存的变量副本。它是一种工作内存的局部写。
- store 把工作内存中的变量的值传递给主内存。
实际上的执行顺序恐怕是 read->load->use->assign->store-> write。
如果要把一个变量从主内存复制到工作内存,那就要按顺序地执行 read 和load 操作,如果要把变量从工作内存同不会主内存,就要执行 store 和 write 操作。 JMM 只要求上述两类操作必须按顺序执行,没有保证必须是连续执行,也就是说在 read 和 load之间、store 和 write 之间是可插入其他指令的。如对主内存的变量 a、b 进行访问的时候,可能出现 read a、read b、load b、load a 的操作顺序。
除此之外, JVM 还规定了额外的指令执行的偏序规则(正好也有八条):
- 不允许 read 和 load、store 和 write 操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起了写回但工作内存不接受的情况。
- 不允许一个线程丢弃它的最近的 assign 操作,即变量在工作内存中发生了改变必须(最终)把该变化同步回主内存里去。
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从线程的工作内存同步回主内存中。
- 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load 或者 assign)的变量,换句话说就是对一个变量实施 use 和 store操作之前,必须经过 assign 和 load 的操作。
- 一个变量在同一个时刻只允许一条线程对它进行 lock 操作,且 lock 操作可以被同一个线程执行多次(多种可重入锁的底层机制就在这里了)。而且只有执行相同数量的 unlock 操作,才能彻底解锁该变量。
- 如果对一个变量进行 lock 操作,会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 和 assign 操作。也就是说,这是一个 flush 加上 reload的过程。
- 如果一个变量没有被 lock 锁住,则 unlock 非法,只有本线程才能unlock。
- 对一个变量进行unlock操作之前,必须先把变量同步回主内存中(执行 store 和 write 操作)。也就是说,变量被线程锁住以后,不是在主内存上工作,而是在自己的工作内存里被使用的,这也印证了上面的八种指令中的 use 必须在 load 之后工作,执行引擎必须使用 use 的印象。
5.volatile关键字
volatile 关键字具有可见性,会使得每次写操作,都会导致全flush 的出现(assign必然导致 store 和 write 回主内存),读操作必须read + load至工作内存, use 到执行引擎(而不能只是use上次留在工作内存里的值),必然总是得到最新的值,不管中间是否有不一致的暂时情况发生,读的语义必然是一致正确的。而如果没有这条语义,use得到的值,可能是之前 use 和 assign 得到的值。
注意,如果使用字节码分析多线程操作,即使只出现一条指令,也不能认为实际执行的机器指令是原子化的,**但如果出现多条字节码指令,那么必然操作没有原子性。**这也是 volatile 修饰的变量只是轻量级同步,不能做到真正互斥原子化的原因。它只保证了可见性。
因此,只有两种情况,不必然要使用标准同步机制:
- 远算结果不依赖指定非栈上变量的当前值,或者能够确保单线程修改指定变量的当前值。
- 变量不需要与其他变量参与同一个不变性约束。
此外,volatile关键字还可以通过插入内存屏障(memory barier)阻止内存指令重排(instruction reorder),阻止特定的赋值顺序被打乱。这点在 Java 5以前是做不到的,也就会经常性导致 Double Check Lock 在 Java 5以前失败。具体地说,相关联的操作是不可重排序的。相关联的read->load->use/assign->store->write可以看做是不可被重排插入中间指令的,一个指令 read 先于另一个指令 read,那么所有相关联的指令都是前者先于后者。这被称为“线程内表现为穿行语义”(Within-Thread As-If-Serial Semantics)。
6.Java内存模型的(Java)的特性
6.1 原子性(Atomicity)##
8个操作,read、load、use、assign、store、write这六个操作是必须原子的(64字节的 long、double 非原子性是可以由lock 和 unlock 的更强原子语义包裹起来规避掉的)。lock 和 unlock 操作虽然不是字节码,但几乎同意的 monitoerenter和monitorexit却是字节码指令。
6.2 可见性(Visibility)##
一个线程的修改,立刻可以被另一个线程看到,方法主要有三个:
- 同步块
- final (final 并不是不可更改的,所以依然有工作内存修改后flush的问题)
- volatile
6.3 有序性(Ordering)##
volatile和同步块可以保证这点。方法内的指令不会被重排,是一个特别重要的不会产生特别副作用的保证。
6.4 volatile 和同步块比较##
volatile不具有原子性,其他场景volatile和同步块都可以使用。
6.5 先行发生原则(happens-before)##
JVM 为程序中所有的操作定义了一个偏序关系(偏序关系 π 是集合上的一种关系,据有反对称、自反和传递属性。但对于任意两个元素x,y来说,并不需要一定满足 x π y, y π x的关系。我们每天都在使用偏序关系表达喜好。),称之为 Happens-Before。只有操作 A 和操作 B 之间满足 Happens-Before 关系,才能保证
保证操作 B 一定能够看到操作 A 的结果。
Happens-Before 的八条原则包括:
- 程序顺序原则(Program Order Rule):在一个线程内,按照程序代码顺序,书写在前面的操作线性发生于书写在后面的操作。这一条并不绝对,首先要考虑控制流循环跳转的问题,其次是,如果后操作无法感知前操作(即不存在依赖关系),则指令重排仍然可能发生。
- 监视器锁定原则(Monitor Lock Rule):一个 unlock 操作时间顺序上先行发生于后面对同一个锁的 lock 操作。(单纯的lock 操作语义只提供了可见性,这条原则还保证了有序性。)
- volatile 变量原则(volatile variable rule):对 volatile 变量的写入操作,必须要在读取操作时间顺序之前进行。
- 线程启动规则(Thread Start Rule):Thread对象的 start()方法先行发生于此线程的每一个动作。
- 线程终止规则(Thread Termination Rule):线程中所有操作,都先行发生于线程的终止检测。常见终止检测是 Thread.join() 的返回,Thread.isAlive()的返回。
- 线程中断原则(Thread Interruption):对线程 interrupt() 方法的调用先行发生于被中断线程检测中断事件的发生。常见检测事件的方法是 Thread.interrupted()。
- 对象终结原则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize()方法的开始。
- 传递性(Transitivity) 操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,操作 A 先行发生于操作 C。