无锁队列
Java
一读一写(SPSC):Memory Barrier + Volatile
1 | |
一写多读(SPMC):Single-Writer Principle + Volatile Publish
1 | |
disruptor 的实现
1 | |
多写多读(MPMC):CAS + Lock-Free Linked Queue
1 | |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2026-01-24
Java 线程池笔记
从执行器到线程池(from executor interface to thread pool implementation) Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management. ——wikipedia “池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。 在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源,使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括: 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。 连接池(Connection Poo...
2026-01-19
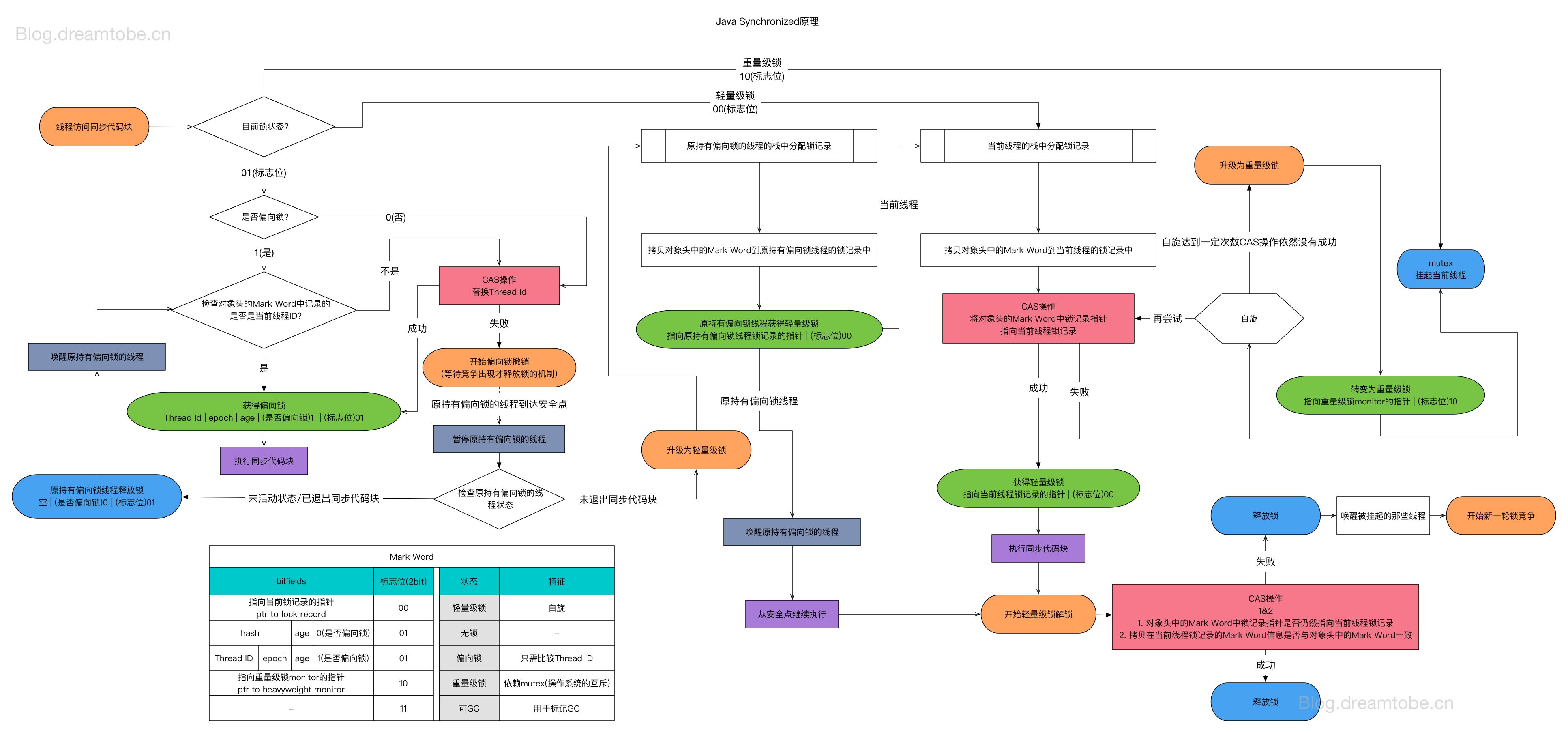
线程安全与锁优化
版本说明:本文主要基于 JDK 6 ~ JDK 14 的 HotSpot 虚拟机实现。需要注意的是,从 JDK 15 开始,偏向锁已被默认关闭并标记为废弃(JEP 374)。如果你使用的是 JDK 15+,文中关于偏向锁的内容仅作为历史参考。 线程安全 什么是线程安全 “当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方法进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。” 相对的线程安全,可以分成五个等级。但在深入讨论线程安全的分类之前,我们需要先理解 Java 内存模型——它是理解线程安全问题的理论基础。 Java 内存模型基础 Java 内存模型(Java Memory Model,JMM)是 Java 语言规范的一部分,定义了多线程程序中共享变量的访问规则。理解 JMM 是理解线程安全问题的基础。 为什么需要内存模型? 现代计算机系统中,CPU 与主内存之间存在巨大的速度差异。为了弥补这一差距,硬件层面引入了多级缓存(L1、L2、L3 Cache)。这带来了一个问...

2026-01-12
Java 并发编程笔记
juc.xmind 写在前面的话 并发编程最早的实践都在操作系统里。高层语言的并发模型都要基于底层系统对硬件抽象和并发的设计来设计和实现,不能超出操作系统允许的范围。所谓的高级抽象总体上是简化对 OS 底层机制的复杂调用。 并发与异步 本文聚焦并发(Concurrency),即多任务在同一时间段内的交替或并行执行,核心问题是资源共享、线程同步与协作。 **异步(Asynchronous)**是另一维度:调用方发起操作后不等结果返回即继续执行,通过回调、Future或事件机制获取结果。异步可通过单线程事件循环实现,也可依托多线程并发实现。 二者关系:并发关注"多任务如何执行与协调",异步关注"调用是否阻塞等待"。并发编程常涉及异步,但本文不展开异步编程模式(如响应式流、协程),相关内容请参阅《Java 线程池笔记》。 管程 理论和实践之间是有鸿沟的,要弥合这种鸿沟,通常需要我们去学习别人的实践。比如并发的标准设计思想来自于操作系统里的管程(monitor),我们应当学习管程,进而了解标准的并发模型-管理共享变量和线程(并发任务)间通信的基本...

2018-10-22
JDWP 与远程调试
JDWP(Java Debug Wire Protocol),它提供了调试器和目标 JVM (target vm)之间的调试协议。 在 target vm 启动时,增加这个 JAVA_OPTS: 1JAVA_OPTS="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=26310" 在服务器端,增加 remote debuging 的时候使用如下配置: 12345678# Java 9 以上-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:8000# Java 5-8-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8000# Java 1.4.x -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,addre...

2026-02-07
Java 结构化并发
结构化并发(Structured Concurrency) 结构化并发是 Java 并发编程的重要演进方向,与虚拟线程紧密配合,旨在解决传统并发编程中的线程泄漏、错误处理困难等问题。 1. 历史背景 1.1 结构化并发的起源与核心类比 术语起源 “结构化并发”(Structured Concurrency)这个术语由 Martin Sústrik(ZeroMQ 作者)在 2016 年首次提出。随后,Nathaniel J. Smith 在 2018 年发表了著名的文章《Notes on structured concurrency, or: Go statement considered harmful》,系统性地阐述了结构化并发的理论基础。 timeline title 结构化并发发展历程 2016 : Martin Sústrik 首创术语 : 在 250bpm.com 发表系列文章 2018 : Nathaniel J. Smith 发表核心论文 : "Go statement considered ha...

2018-10-13
卡表和 RSet
卡表和 RSet 问题定义:为什么需要跨区域引用记录 JVM 垃圾收集器的核心工作之一是确定 live set——哪些对象仍然存活、不可回收。确定 live set 的标准做法是从 GC Roots(栈帧中的局部变量、静态字段等)出发,沿引用链遍历所有可达对象。 问题在于:当堆被划分为多个区域(代、Region)并且只回收其中一部分时,如何高效地找到从"不回收区域"指向"回收区域"的引用? 以 Young GC 为例:只回收新生代,但老年代中可能持有指向新生代对象的引用。如果不处理这些跨代引用,就会错误地回收仍被老年代引用的新生代对象。最朴素的做法是扫描整个老年代来找出这些引用——但老年代通常远大于新生代,这样做的代价过高,违背了分代收集"只回收一部分堆"的初衷。 卡表(Card Table)和 RSet(Remembered Set)正是为解决这个问题而设计的辅助数据结构。二者的关系并非互相替代,而是层次不同、协作互补:卡表是底层的脏标记机制,RSet 是建立在卡表之上的更高层索引结构。 核心概念速览 在深入细节之前,...