数据库写入的潜规则——合并树与 MPP 架构深度剖析
许多开发者在使用 ClickHouse、HBase、Elasticsearch 等现代数据系统时,都会遇到"不建议高频写入"的限制。这一限制常被归因于"列式存储",但这是一个常见的误解。
高频写入受限的根本原因在于数据库的存储引擎架构。本文将深入剖析四大主流架构——LSM-Tree、ClickHouse MergeTree、MPP 和 B-Tree——分析它们各自的写入机制、性能权衡,以及它们"偏爱"批量写入的底层原因。
Part 1: 磁盘 I/O 基础——理解一切的前提
深入存储引擎之前,有必要先理解磁盘 I/O 的基本特性,因为所有存储引擎的设计都是围绕磁盘特性做出的权衡。
随机写 vs 顺序写
| 指标 | HDD(机械硬盘) | SSD(固态硬盘) | 内存(DRAM) |
|---|---|---|---|
| 随机写 IOPS | ~100-200 | 10K-100K | ~10M |
| 顺序写吞吐 | ~100-200 MB/s | 500 MB/s - 3 GB/s | ~10 GB/s |
| 随机写延迟 | ~10ms(寻道时间) | ~100μs | ~100ns |
| 顺序写延迟 | ~1ms | ~10μs | ~100ns |
顺序写比随机写快 100-1000 倍的原因:
- HDD:机械硬盘需要物理移动磁头(寻道)并等待盘片旋转到目标位置。随机写意味着频繁的寻道,而顺序写可以连续写入相邻扇区,几乎不需要寻道。
- SSD:虽然没有机械部件,但 SSD 的写入单位是页(Page,通常 4KB-16KB),而擦除单位是块(Block,通常 256KB-4MB)。随机小写入会导致写放大(Write Amplification)和频繁的垃圾回收(Garbage Collection),严重影响性能和寿命。
Page Cache 与 fsync
操作系统在应用程序和磁盘之间维护了一层Page Cache(页缓存):
1 | |
- write() 系统调用通常只是将数据写入 Page Cache,立即返回。这使得写入看起来很快。
- fsync() 强制将 Page Cache 中的脏页刷写到磁盘,确保数据持久化。这是一个昂贵的操作。
- 数据库通常需要在关键时刻调用 fsync() 来保证持久性(Durability),这是性能的主要瓶颈之一。
WAL:Write-Ahead Log
几乎所有数据库都使用 WAL(预写日志) 来保证崩溃恢复能力:
- 先将修改操作顺序追加到 WAL 文件
- 然后再修改实际的数据文件
- 崩溃恢复时,通过重放 WAL 恢复未完成的操作
WAL 之所以高效,正是因为它是顺序写入的——利用了磁盘顺序写的高吞吐特性。
WAL 的详细工作机制
WAL 的核心协议可以分解为以下步骤:
- 日志记录生成:事务的每个修改操作被序列化为一条日志记录(Log Record),包含 LSN(Log Sequence Number,日志序列号)、事务 ID、操作类型(INSERT/UPDATE/DELETE)、修改前的值(undo 信息)和修改后的值(redo 信息)
- 日志缓冲区写入:日志记录首先写入内存中的日志缓冲区(Log Buffer),以减少磁盘 I/O 次数
- 日志刷盘(Log Flush):在以下时机将日志缓冲区刷写到磁盘:
- 事务提交时(保证持久性)
- 日志缓冲区满时
- 后台定时刷盘(如 InnoDB 每秒刷盘一次)
- 检查点(Checkpoint):数据库定期创建检查点,将内存中的脏页刷写到数据文件,并记录检查点的 LSN。崩溃恢复时只需从最近的检查点开始重放 WAL,而非从头开始
WAL 的写入保证遵循 WAL 协议(Write-Ahead Logging Protocol) 的两条核心规则:
- Undo 规则:数据页刷盘之前,对应的 undo 日志记录必须先刷盘(支持事务回滚)
- Redo 规则:事务提交之前,该事务的所有 redo 日志记录必须先刷盘(支持崩溃恢复)
这两条规则确保了即使在任意时刻发生崩溃,数据库都能通过 WAL 恢复到一致状态:先通过 redo 日志重做已提交但未刷盘的事务,再通过 undo 日志回滚未提交的事务。
Direct I/O vs Buffered I/O
| 模式 | 特点 | 使用者 |
|---|---|---|
| Buffered I/O | 经过 Page Cache,操作系统管理缓存 | 大多数数据库默认模式 |
| Direct I/O | 绕过 Page Cache,直接读写磁盘 | InnoDB、RocksDB(可选) |
Direct I/O 的优势在于:数据库可以自己管理缓存策略(如 InnoDB 的 Buffer Pool),避免与操作系统的 Page Cache 产生**双重缓存(Double Buffering)**问题。
Part 2: 经典 LSM-Tree——为高频更新而生的缓冲合并
发明背景
LSM-Tree(Log-Structured Merge-Tree)由 Patrick O’Neil 等人在 1996 年的论文中提出。其核心动机是:将随机写入转换为顺序写入,从而在机械硬盘时代获得极高的写入吞吐量。
三部曲:MemTable → Flush → Compaction
LSM-Tree 的写入流程可以概括为三个阶段:
1 | |
阶段一:写入 MemTable
数据首先写入内存中的有序数据结构——MemTable。同时,为了防止崩溃丢失数据,写入操作也会被追加到 WAL。
MemTable 的数据结构选择:
| 数据结构 | 使用者 | 优势 | 劣势 |
|---|---|---|---|
| 跳表(SkipList) | RocksDB、LevelDB | 支持并发写入(无锁或细粒度锁) | 内存碎片较多 |
| 红黑树 | HBase(早期) | 严格平衡,查找性能稳定 | 并发写入需要加锁 |
| B+ 树变体 | WiredTiger(MongoDB) | 缓存友好 | 实现复杂 |
阶段二:Flush 到磁盘
当 MemTable 达到阈值(通常 64MB-256MB)时,它会被冻结(变为不可变的 Immutable MemTable),然后作为一个整体的、有序的 SSTable(Sorted String Table) 文件顺序写入磁盘。
SSTable 的内部结构:
1 | |
读路径优化:Bloom Filter
LSM-Tree 的读取需要依次查询 MemTable 和多层 SSTable,读放大是其主要劣势。SSTable 中内置的 Bloom Filter 是缓解读放大的关键优化手段。
Bloom Filter 是一种空间高效的概率数据结构,用于判断某个 key 是否可能存在于当前 SSTable 中:
- 若 Bloom Filter 返回"不存在",则该 key 一定不在此 SSTable 中,可直接跳过
- 若 Bloom Filter 返回"存在",则该 key 可能在此 SSTable 中,需要进一步读取验证
Bloom Filter 的误判率(False Positive Rate) 计算公式为:
[ f = \left(1 - e^{-kn/m}\right)^k ]
其中:
- ( m ) 为 Bloom Filter 的位数组长度(bit 数)
- ( n ) 为已插入的元素数量
- ( k ) 为哈希函数的个数
- 最优哈希函数个数为 ( k_{opt} = \frac{m}{n} \ln 2 \approx 0.693 \frac{m}{n} )
在实际系统中,RocksDB 默认为每个 SSTable 分配 10 bits/key 的 Bloom Filter 空间,对应的误判率约为 1%。LevelDB 同样默认 10 bits/key。通过合理配置 Bloom Filter,可以将点查询的读放大从 O(L)(L 为 SSTable 层数)降低到接近 O(1)。
阶段三:后台 Compaction
随着 Flush 不断产生新的 SSTable 文件,磁盘上会积累大量小文件。后台的 Compaction(合并) 任务负责将多个小 SSTable 合并成更大的 SSTable,同时:
- 删除过期的数据(tombstone 标记的删除)
- 合并同一个 key 的多个版本
- 减少文件数量,提升读取性能
Compaction 策略详解
不同的 Compaction 策略适用于不同的工作负载:
Size-Tiered Compaction(STCS)
1 | |
- 原理:将大小相近的 SSTable 分组,当同一组的文件数量达到阈值时,合并为一个更大的文件
- 优势:写入放大低,适合写多读少的场景
- 劣势:空间放大高(合并期间需要同时保留新旧文件),读取时可能需要查询多个文件
- 使用者:Cassandra(默认)、ScyllaDB
Leveled Compaction(LCS)
1 | |
- 原理:将 SSTable 组织成多个层级,每层的文件 key 范围不重叠。Level 0 的文件与 Level 1 合并时,选择 key 范围有重叠的文件进行合并
- 优势:空间放大低,读取性能好(每层最多查一个文件)
- 劣势:写入放大高(一条数据可能被合并多次)
- 使用者:RocksDB(默认)、LevelDB
FIFO Compaction
- 原理:按时间顺序淘汰最老的 SSTable,不做合并
- 适用场景:时序数据,只需要最近的数据
Universal Compaction
- 原理:RocksDB 提供的混合策略,根据文件大小比例动态选择合并方式
- 适用场景:需要在写入放大和空间放大之间灵活权衡
三种放大问题
LSM-Tree 的核心权衡可以用三种"放大"来量化:
| 放大类型 | 定义 | 影响 | 量化 |
|---|---|---|---|
| 写放大(Write Amplification) | 实际写入磁盘的数据量 / 用户写入的数据量 | 磁盘寿命(SSD)、写入带宽 | STCS: 2-5x, LCS: 10-30x |
| 读放大(Read Amplification) | 读取一条数据需要查询的 SSTable 数量 | 读取延迟 | STCS: 高, LCS: 低 |
| 空间放大(Space Amplification) | 实际占用磁盘空间 / 有效数据大小 | 存储成本 | STCS: 高, LCS: 低 |
代表系统
| 系统 | MemTable | Compaction 默认策略 | 特点 |
|---|---|---|---|
| LevelDB | SkipList | Leveled | Google 开发,单线程 Compaction |
| RocksDB | SkipList | Leveled | Facebook 基于 LevelDB 优化,多线程 Compaction |
| HBase | ConcurrentSkipListMap | Size-Tiered | Hadoop 生态,分布式 |
| Cassandra | ConcurrentSkipListMap | Size-Tiered | 无主架构,高可用 |
| ScyllaDB | 自定义 | Size-Tiered | C++ 重写 Cassandra,性能更高 |
Part 3: ClickHouse MergeTree——为极致分析而生的直接合并
与经典 LSM-Tree 的关键区别
ClickHouse 的 MergeTree 引擎虽然也依赖"合并",但它走了一条更直接、更极致的道路:
MergeTree 不是一个标准的 LSM-Tree,因为它没有 MemTable!
| 特性 | 经典 LSM-Tree | ClickHouse MergeTree |
|---|---|---|
| 写入缓冲 | MemTable(内存) | 无(直接写磁盘) |
| 写入单位 | 单条/小批量 → MemTable | 每个 INSERT → 一个 Part |
| 合并触发 | MemTable 满 → Flush + Compaction | 后台定期合并 Parts |
| 攒批责任 | 数据库内部(MemTable) | 用户/客户端 |
每个 INSERT 直接生成 Part
每一个 INSERT INTO ... VALUES (...) 语句,无论大小,都会被 ClickHouse 直接在文件系统上组织成一个或多个新的、不可变的数据部件(Part)。
Part 的内部结构(列式存储):
1 | |
后台 Merge 的触发与策略
ClickHouse 的后台合并线程会持续地将小 Part 合并成更大的 Part:
- 触发条件:当同一分区内的 Part 数量超过阈值时触发
- 合并策略:选择大小相近的 Part 进行合并(类似 Size-Tiered)
- 合并过程:读取多个 Part 的数据,按主键排序后写入新的 Part,删除旧 Part
为什么 MergeTree 对"批量性"要求更高
由于没有 MemTable 作为缓冲,每个 INSERT 都直接产生磁盘文件:
- 1000 次单条 INSERT = 1000 个小 Part = 1000 个目录 = 海量小文件
- 1 次 1000 条 INSERT = 1 个 Part = 1 个目录
海量小文件会导致:
- 文件系统 inode 耗尽
- 后台合并压力剧增
- 查询性能急剧下降(需要打开和读取大量小文件)
- ClickHouse 可能直接报错:
Too many parts
生产建议:每批至少 1000 行,每秒不超过 1 次 INSERT。
async_insert:ClickHouse 的"外部 MemTable"
ClickHouse 21.11 引入了 async_insert 功能,本质上是在服务端实现了类似 MemTable 的攒批机制:
1 | |
工作原理:
- 客户端发送 INSERT 请求
- ClickHouse 将数据暂存在内存缓冲区
- 当缓冲区达到大小阈值或超时时,将缓冲区中的数据合并为一个 Part 写入磁盘
MergeTree 变体
| 变体 | 用途 | 合并时的特殊行为 |
|---|---|---|
| ReplacingMergeTree | 去重 | 保留同一主键的最新版本 |
| AggregatingMergeTree | 预聚合 | 合并时执行聚合函数 |
| CollapsingMergeTree | 状态变更 | 通过 +1/-1 标记实现"撤销" |
| VersionedCollapsingMergeTree | 带版本的状态变更 | 支持乱序插入的 Collapsing |
| SummingMergeTree | 求和聚合 | 合并时对数值列求和 |
Part 4: MPP 架构的另一种权衡——AWS Redshift
架构概述
Redshift 是一个典型的 MPP(Massively Parallel Processing,大规模并行处理) 架构的列式数据库。
1 | |
- Leader Node:接收查询、解析 SQL、生成执行计划、分发任务、汇总结果
- Compute Nodes:存储数据并执行计算。每个节点被划分为多个 Slice,每个 Slice 独立处理一部分数据
数据分布策略
数据如何分布到各个 Compute Node 上,直接影响查询和写入性能:
| 分布策略 | 说明 | 适用场景 |
|---|---|---|
| KEY | 按指定列的哈希值分布 | 经常 JOIN 的大表,选择 JOIN 键作为分布键 |
| EVEN | 轮询均匀分布 | 没有明显 JOIN 模式的表 |
| ALL | 每个节点存储完整副本 | 小的维度表(< 几百万行) |
| AUTO | Redshift 自动选择 | 不确定最佳策略时 |
COPY 命令:最高效的写入方式
Redshift 最高效的写入方式是使用 COPY 命令从 S3 并行加载数据:
1 | |
此时,每个 Compute Node 会独立、并行地从 S3 拉取属于自己的那部分数据,效率极高。
最佳实践:
- 将数据文件拆分为与 Slice 数量相同(或倍数)的文件
- 使用压缩格式(GZIP、LZO、ZSTD)
- 使用列式格式(Parquet、ORC)
单条 INSERT 的分布式事务开销
执行一条 INSERT INTO ... VALUES (...) 语句时,完整的处理流程如下:
- 请求到达 Leader Node
- Leader Node 解析 SQL,确定数据应该分布到哪个 Compute Node
- Leader Node 启动分布式事务
- 数据被发送到目标 Compute Node
- Compute Node 写入数据
- 分布式事务提交(涉及跨节点的 2PC 协调)
单条记录的写入需要经历完整的分布式事务协调流程,固定开销远大于数据本身的写入开销,导致单条写入的效率极低。
Sort Key 与 Distribution Key
| 键类型 | 作用 | 对写入的影响 |
|---|---|---|
| Sort Key | 数据在磁盘上的物理排序 | 写入后需要 VACUUM SORT 重新排序 |
| Distribution Key | 数据在节点间的分布 | 影响数据倾斜和 JOIN 性能 |
VACUUM 和 ANALYZE
Redshift 的写入和删除不会立即物理删除数据,而是标记为"已删除"。需要定期执行:
- VACUUM DELETE:回收已删除行的空间
- VACUUM SORT:重新按 Sort Key 排序
- ANALYZE:更新统计信息,优化查询计划
与其他 MPP 系统的对比
| 系统 | 架构特点 | 写入方式 | 存算分离 |
|---|---|---|---|
| Redshift | 传统 MPP | COPY 命令 | Redshift Serverless 支持 |
| Greenplum | 基于 PostgreSQL 的 MPP | 外部表/COPY | 否 |
| Snowflake | 云原生存算分离 | COPY/Snowpipe | 是(S3 存储) |
| BigQuery | Serverless | 流式插入/批量加载 | 是(Colossus 存储) |
Part 5: B-Tree 存储引擎——传统 OLTP 的写入机制
原地更新策略
B-Tree(及其变体 B+ Tree)是传统 OLTP 数据库(MySQL InnoDB、PostgreSQL)的核心存储结构。与 LSM-Tree 的"追加写入"不同,B-Tree 采用**原地更新(In-Place Update)**策略:
1 | |
页分裂的开销
当一个 B-Tree 节点(页)已满,插入新数据时会触发页分裂(Page Split)。以 InnoDB 默认的 16KB 页为例,页分裂的具体算法步骤如下:
- 检测页满:尝试插入新记录时,发现当前叶子页的可用空间不足以容纳新记录
- 分配新页:从表空间的空闲页链表中分配一个新的空页,并初始化页头信息
- 确定分裂点:默认情况下,选择当前页中间位置的记录作为分裂点。InnoDB 对顺序插入(如自增主键)有优化:若检测到插入点在页尾,则按约 15:1 的比例分裂(保留大部分数据在原页),而非 1:1 均分
- 数据迁移:将分裂点之后的所有记录复制到新页中,并在新页内维护记录的有序链表
- 更新父节点:在父节点(非叶子节点)中插入一条新的索引记录,指向新页,其 key 值为新页中的最小 key
- 递归分裂:若父节点也已满,则对父节点递归执行相同的分裂过程。极端情况下,分裂可能一直传播到根节点,导致树的高度增加 1
- 更新兄弟指针:更新原页、新页及原页右兄弟页之间的双向链表指针,维护叶子页的有序链表结构
页分裂涉及多个页的读写和指针更新,是一个昂贵的操作。单次页分裂至少需要 3 次页写入(原页、新页、父节点页),加上 WAL 日志写入。在高频写入场景下,频繁的页分裂会严重影响性能。使用自增主键可以有效减少页分裂的频率,因为新记录总是追加到最右侧的叶子页。
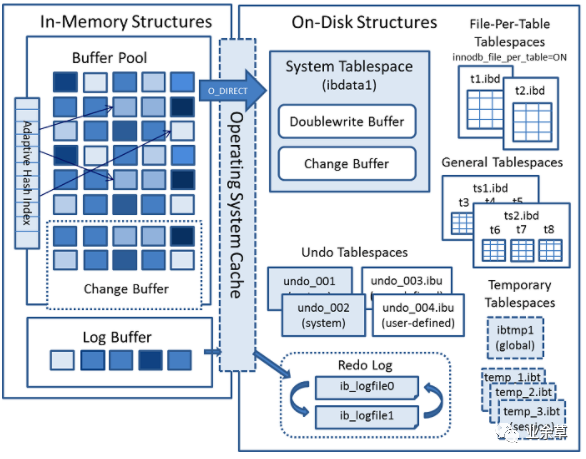
InnoDB 的 Redo Log 与 Doublewrite Buffer
Redo Log 机制
InnoDB 的 redo log 是 WAL 机制的具体实现,采用固定大小的循环写入(circular write)方式:
- redo log 由一组固定大小的文件组成(默认 2 个文件,每个 48MB,共 96MB;MySQL 8.0.30 起默认 100MB),逻辑上构成一个环形缓冲区
- 两个关键指针控制 redo log 的使用:
- write pos:当前写入位置,随新日志写入向前推进
- checkpoint:当前已刷盘的脏页对应的 LSN 位置,随脏页刷盘向前推进
- write pos 与 checkpoint 之间的空间为可用空间。当 write pos 追上 checkpoint 时,InnoDB 必须暂停写入,强制推进 checkpoint(即刷脏页),这就是所谓的 sharp checkpoint,会导致写入抖动
redo log 记录的是物理逻辑日志(physiological log):以页为单位标识修改位置(物理),以页内偏移和操作类型描述具体修改(逻辑)。这种设计兼顾了恢复效率和日志紧凑性。
Doublewrite Buffer 机制
InnoDB 的页大小为 16KB,而大多数文件系统的原子写入单位为 4KB。当数据库将一个 16KB 的脏页刷写到磁盘时,如果在写入过程中发生崩溃(例如只写入了前 4KB),就会产生部分写入(Partial Write / Torn Page) 问题——磁盘上的页处于不一致状态,且 redo log 无法修复(因为 redo log 是物理逻辑日志,需要基于一致的页基础进行重放)。
Doublewrite Buffer 通过两次写入解决此问题:
- 第一次写入(顺序写):将脏页先写入表空间中一块连续的 doublewrite 区域(默认 2MB,128 个页),这是一次顺序写入,性能开销较小
- 第二次写入(随机写):将脏页写入其在数据文件中的实际位置
崩溃恢复时的处理逻辑:
- 若实际数据页完整(校验和验证通过),直接使用 redo log 进行恢复
- 若实际数据页损坏(部分写入),从 doublewrite 区域读取该页的完整副本,先恢复数据页,再应用 redo log
Doublewrite Buffer 带来约 5%-10% 的写入性能开销,但保证了数据页的完整性。在支持原子写入的存储设备(如部分 NVMe SSD 支持 16KB 原子写入)上,可以通过 innodb_doublewrite=0 关闭此特性以提升性能。
InnoDB 的 Change Buffer 优化
InnoDB 针对非唯一二级索引的写入做了优化——Change Buffer:
1 | |
Change Buffer 的本质是延迟写入:避免为了更新一个不在内存中的索引页而产生随机 I/O。
PostgreSQL 的 HOT 更新
PostgreSQL 的 MVCC 实现中,UPDATE 操作实际上是插入一个新版本。HOT(Heap-Only Tuple)优化允许在同一个页内更新,避免更新索引:
- 条件:更新的列不包含任何索引列,且同一页有足够空间
- 效果:避免了索引更新的开销
B-Tree vs LSM-Tree 经典对比
| 维度 | B-Tree | LSM-Tree |
|---|---|---|
| 写入模式 | 原地更新(随机写) | 追加写入(顺序写) |
| 写入性能 | 中等 | 高 |
| 读取性能 | 高(一次 B-Tree 查找) | 中等(可能查多个 SSTable) |
| 空间利用率 | 高(原地更新) | 中等(多版本共存) |
| 写放大 | 低(1-2x) | 高(10-30x) |
| 适用场景 | OLTP(读多写少) | 写密集型工作负载 |
| 代表系统 | MySQL InnoDB、PostgreSQL | RocksDB、HBase、Cassandra |
结论:殊途同归的"批量写入"
完整对比
| 架构 | 代表系统 | 写入瓶颈根源 | 瓶颈类型 |
|---|---|---|---|
| 经典 LSM-Tree | HBase, Cassandra, RocksDB | 后台 Compaction 跟不上 MemTable Flush 产生的小文件速度 | 写后维护成本 |
| ClickHouse MergeTree | ClickHouse | 后台 Merge 跟不上直接 INSERT 产生的小 Part 速度 | 写后维护成本 |
| MPP | Redshift, Greenplum | 分布式事务和数据分发对单条写入开销过大 | 写入时协调成本 |
| B-Tree | MySQL InnoDB, PostgreSQL | 随机 I/O 和页分裂的开销 | 原地更新成本 |
技术选型指南
| 业务场景 | 推荐架构 | 理由 |
|---|---|---|
| 高频 OLTP(订单、支付) | B-Tree(MySQL/PostgreSQL) | 低延迟读写,事务支持 |
| 高频写入 + 实时查询 | LSM-Tree(RocksDB/Cassandra) | 高写入吞吐,可接受的读取延迟 |
| 批量分析(BI 报表) | ClickHouse MergeTree | 极致的分析查询性能 |
| 数据仓库(ETL 后分析) | MPP(Redshift/Snowflake) | 大规模并行查询,SQL 兼容性好 |
| 时序数据(监控、IoT) | LSM-Tree 变体(InfluxDB/TimescaleDB) | 高写入吞吐,时间范围查询优化 |
无论是哪种架构,它们都通过各自的方式,最终指向了同一个最佳实践——"批量、低频次"地写入数据。
理解各架构偏爱批量写入的底层原因,有助于正确使用这些存储系统、避免性能陷阱,并在技术选型时根据业务的真实写入模式做出精准决策。
参考资料