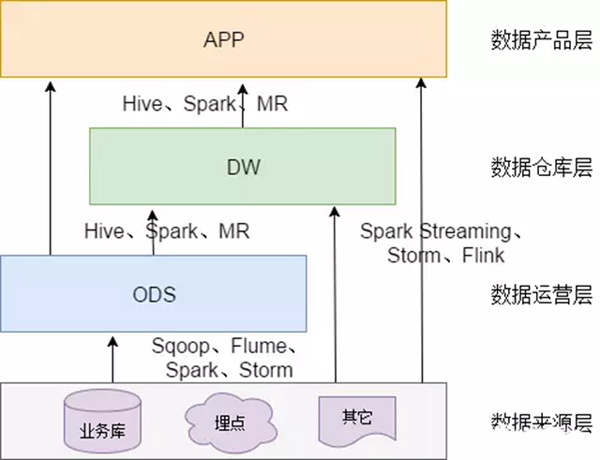
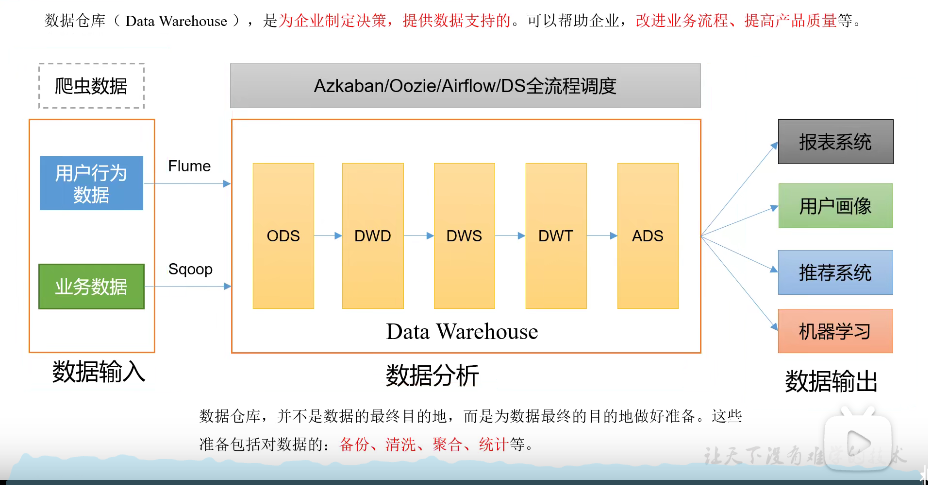
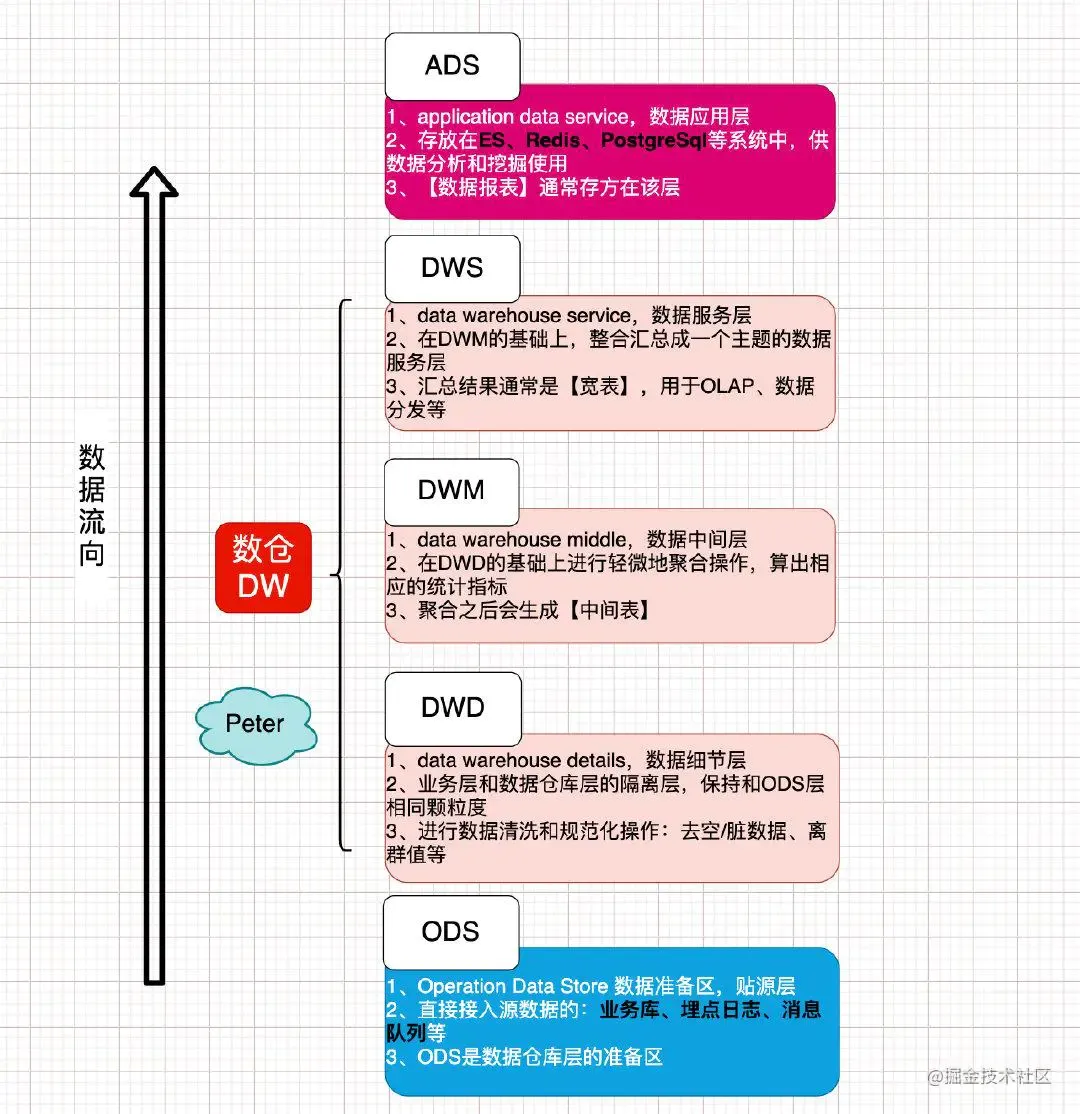
datawarehouse相关

All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-07-13
DataFrame 与 Dataset:类型安全与性能的折中
上一篇解决了 Catalyst 优化器的四阶段流水线。这一篇进入用户 API 层——RDD、DataFrame、Dataset 三代 API 的演进逻辑。 三者的区别容易被简化为"RDD 是低级 API,DataFrame 是高级 API"。更准确的说法是:三代 API 在类型安全和执行优化之间做了不同的取舍。RDD 完全类型安全但无法被 Catalyst 优化;DataFrame 完全被 Catalyst 优化但放弃了编译期类型检查;Dataset 试图兼顾两者,但付出了 Encoder 序列化/反序列化的代价。 本文只抓一个问题:三代 API 在内部表示、优化路径和序列化机制上的具体差异。 三代 API 的内部表示 1234567891011121314RDD[Person] └─ 内部存储: JVM 堆上的 Java/Scala 对象 └─ 优化路径: 无(用户代码是黑盒,Spark 无法查看函数内部) └─ 类型信息: 编译期完整保留(泛型参数 T = Person)DataFrame (= Dataset[Row]) └─ 内部存储: Uns...

2026-07-13
动态资源分配与作业调度:多租户集群的资源博弈
上一篇解决了 Spark 在 YARN 和 K8s 上的部署模式。这一篇进入资源调度——在多个作业共享集群时,Spark 如何动态分配和回收资源。 默认情况下,一个 Spark 应用在启动时申请固定数量的 Executor,作业结束前一直占用。这在单用户开发环境下可以接受,在多租户生产集群中会造成严重的资源浪费——一个空闲的 Spark 应用占着 100 个 Executor 不释放,其他作业排队等待。 本文只抓一个问题:动态资源分配如何按需申请和释放 Executor,以及 FAIR 调度器如何在多个作业之间公平分配资源。 动态资源分配(DRA) Dynamic Resource Allocation(DRA)允许 Spark 应用根据工作负载动态增减 Executor 数量:有 pending Task 时申请新 Executor,Executor 空闲超时后释放。 12345678910111213141516作业生命周期中的 Executor 数量变化: Executor 数量 8 │ ┌────┐ 6 │ ┌────┤ ├──...

2026-07-13
数据源 API 与谓词下推:让存储层帮忙过滤
上一篇解决了 AQE 的运行时优化。这一篇进入数据源层——Spark 如何把计算推到存储层执行。 查询优化不只发生在执行引擎内部。如果存储层能在读取数据时就过滤掉不需要的行和列,引擎需要处理的数据量会大幅减少。Spark 通过 DataSource API 和 Catalyst 的优化规则把这个能力标准化了:谓词下推(Predicate Pushdown)让存储层只返回满足条件的行,列裁剪(Column Pruning)让存储层只返回查询需要的列。 本文只抓一个问题:谓词下推和列裁剪如何从 Catalyst 的逻辑计划传递到数据源实现。 DataSource API 的两代演进 Spark 的数据源 API 经历了两代: 12345678910DataSource V1 (Spark 1.3+): 接口: InputFormat / OutputFormat + createRelation 谓词下推: 通过 PrunedFilteredScan trait 可选实现 问题: API 不够灵活,不支持流式读写,难以做细粒度优化DataSource V2 (Spark 2.3...

2026-07-13
存储体系:Block Manager、广播变量与累加器
上一篇解决了 Tungsten 的内存管理和代码生成优化。这一篇进入存储体系——Spark 如何管理分布在集群中的数据块。 BlockManager 容易被忽略,因为用户代码很少直接和它打交道。但 RDD 的 persist/cache、Shuffle 的中间文件、广播变量的分发、累加器的聚合,底层全部通过 BlockManager 完成。它是 Spark 存储层的统一入口。 本文只抓一个问题:BlockManager 如何在内存和磁盘之间管理数据块,以及广播变量和累加器在这个体系中的位置。 BlockManager 架构 每个 Executor 上运行一个 BlockManager 实例,Driver 上也有一个(主要用于接收广播变量和累加器结果)。BlockManager 内部包含三个核心组件: 1234BlockManager├── MemoryStore 内存存储(堆内/堆外)├── DiskStore 磁盘存储(本地目录)└── BlockTransferService 网络传输(Netty) MemoryStore 负责在 JVM 堆内或堆外内存...

2026-07-13
Spark 与 Flink:两种计算引擎的设计选择
上一篇解决了 Spark 的性能诊断方法。这一篇进入设计对比——Spark 和 Flink 两种计算引擎的架构选择。 这不是一个"谁更好"的问题。Spark 和 Flink 从不同的起点出发,做了不同的设计取舍,各自在擅长的场景中有结构性优势。Spark 从批处理出发,用 micro-batch 扩展到流处理;Flink 从流处理出发,把批看作有界流。两条路线在功能上逐步趋同,但底层架构的差异导致了性能特性和适用场景的持久分化。 本文只抓一个问题:两个引擎在执行模型、状态管理、容错机制和延迟特性上的具体差异及其设计原因。 执行模型对比 Spark 的执行模型是 Stage-based DAG:把计算图按 Shuffle 边界切成 Stage,每个 Stage 包含一组可以 pipeline 执行的窄依赖变换。Stage 之间是全局同步点——上游 Stage 的所有 Task 必须全部完成后,下游 Stage 才能启动。 1234567891011Spark 执行模型: Stage 0: [Task 0] [Task 1] [Task 2] 全部完成 ...

2026-07-13
DAG Scheduler 与 Task Scheduler:从逻辑计划到物理执行
上一篇解决了 Stage 的划分规则——遇到 ShuffleDependency 就切一刀。这一篇进入调度器内部。 Stage 划分出来之后,谁来决定 Stage 的提交顺序?谁来把 Stage 拆成 Task 发给 Executor?Spark 用两层调度器分工完成这件事:DAGScheduler 负责 Stage 级别的依赖分析和提交顺序,TaskScheduler 负责 Task 级别的资源分配和执行调度。 本文只抓一个问题:一个 action 触发之后,从 Job 到 Stage 到 Task 再到 Executor,调度链路上每一步发生了什么。 调度全景 12345678910111213141516171819202122232425用户代码: rdd.count() │ ▼ SparkContext.runJob() │ ▼ DAGScheduler.submitJob() │ 构建 Stage DAG,按依赖顺序提交 ▼ DAGScheduler.submitStage() │ 检查父 S...