
技术拾遗
Java
Java 8
Lambda
Java 8 Lambdas - A Peek Under the Hood
What does $$ in javac generated name mean?
-
lambda 表达式并不总是持有外部 enclosing object 的引用,如果它不访问任何外部变量,即不持有这样的引用。只要设计一个对比实验,就会发现引用过外部变量的lambda实例才会产生一个 arg 的隐式参数引用。而内部类内部总是含有一个
this$0。 -
lambda表达式是词法作用域的-意思是不产生新的作用域,不产生任何shadowing问题。它可以无缝访问外部作用域的东西,就好像从一个 if block 里访问一个方法里的其他变量一样。但,同样地,不能声明新变量。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2023-03-31
Spring Web
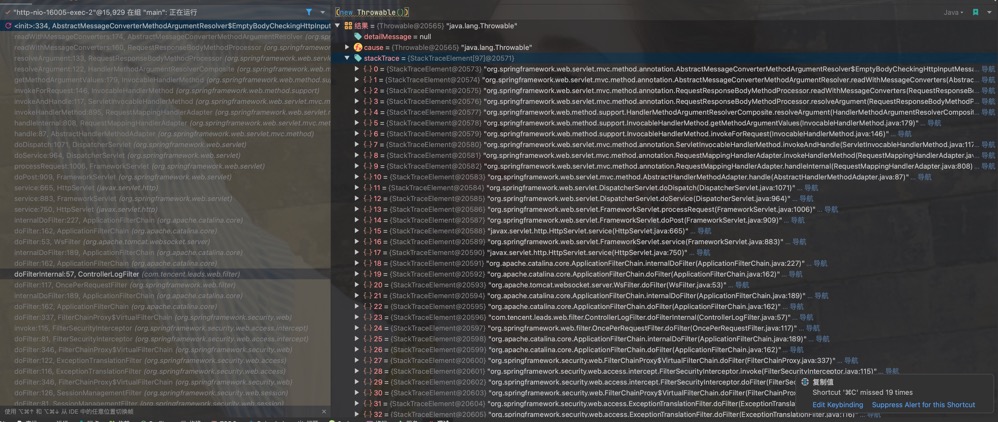
Spring MVC 把 httprequest 放入线程的过程 1234567891011public class ServletRequestAttributes extends AbstractRequestAttributes { /** * Create a new ServletRequestAttributes instance for the given request. * @param request current HTTP request */ public ServletRequestAttributes(HttpServletRequest request) { Assert.notNull(request, "Request must not be null"); this.request = request; }} 在 RequestContextFilter 的子类 OrderedRequestContextFilter: 123456789101112131415161718...
2020-02-23
泛型拾遗
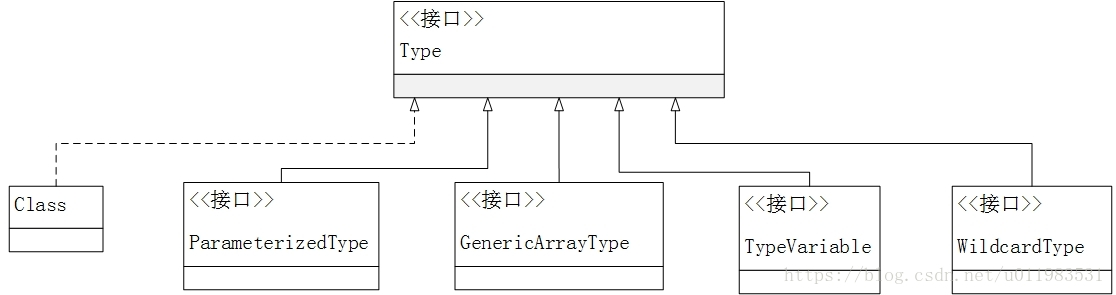
基本设计原则 how codes should vary in different types. compatible with other release. before generic class,generic programming was achieved with inheritance:在所有后来使用T的地方使用Object或者Object数组。经典的猫狗列表问题的来源。 基本语法 java 的泛型没有 template 关键字。表面上(superficially)看和 C++ 并无二致,实际上有大量差别 三种基本概念: Type Parameter(类型形参):在泛型类、接口或方法声明时使用的标识符。 class Box<T> 中的 T。 但是在 Java 核心技术中,List<String>中的String也经常被描述为 Type Parameter。Container.class.getTypeParameters()得到的也是T。 Type Variable(类型变量):类型参数在代码中的引用。 可以认为是类型参数的一...

2021-05-10
ElasticSearch 总结
ES 思维导图 ElasticSearch总结.xmind %% 完整的ES实战决策图 - 基于Leads系统真实案例 flowchart TD %% ========== 字段类型演进 ========== TypeEvolution([ES 5.0 类型演进]) --> StringSplit{string类型拆分} StringSplit -->|全文搜索| TextType[text类型] StringSplit -->|精确匹配/聚合/排序| KeywordType[keyword类型] %% ========== 字段设计部分 ========== Start([开始ES字段设计]) --> FieldType{需要索引该字段吗?} FieldType -->|否| Skip[不索引该字段] FieldType -->|是| DataType{数据类型?} DataTyp...
2020-03-11
Java Logging
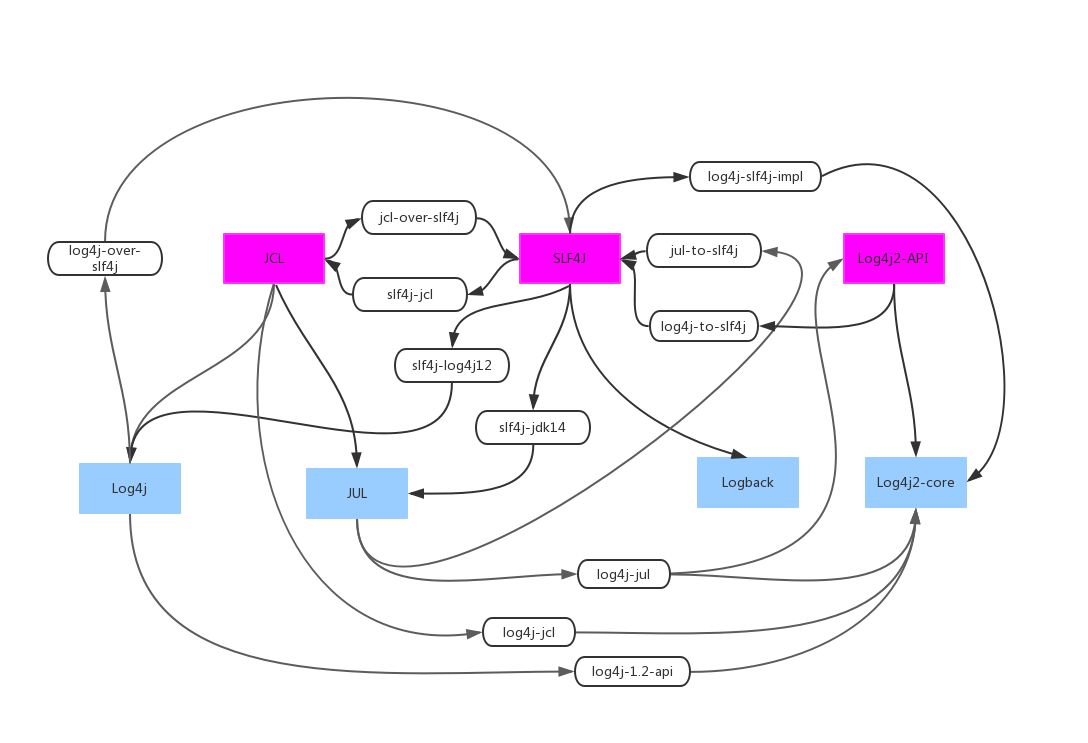
log 历史 阶段 阶段 阶段 阶段 阶段 log4j apache commons logging(JCL) log4j2 JUL simple log logback + slf4j 多个项目使用不同的 logging 库 + 传递依赖等于依赖管理不规范,日志库泛滥以至互斥。 具体框架与门面 所谓的日志框架,指的是日志输出的具体实现,常见的日志框架包括但不仅限于 JUL(Java Util Logging)、Log4j、Log4j2 和 Logback。这些框架的功能不尽相同,比如有些框架支持友好地打印异常,有些不支持,有些框架不支持,不同的框架的日志级别也各有差异。 因此,诞生了日志门面。所谓的门面,就是“使用一个中间层解耦”这一具体思想的应用。使用了门面,可以屏蔽日志使用者对于具体差异的依赖,既让代码变得整洁,而且可以简单地切换实现而不需要修改代码。没有日志门面,不足以统一日志框架的使用。 log facade(定义 interface,早期的 JCL 时代,facade 也被叫做接口)-> log imp...

2021-10-09
JDK 的广泛分支
Oracle Hospot JDK java 8 特定版本以后就不再免费了。 现有的JDK8,2019.1之前的更新都可以免费获取正常使用。 Oracle JDK11是一个长期支持的版本,用于商业环境需要付费。 Azul Zulu builds of OpenJDK Zulu 是Azul公司基于OpenJDK发布的Java SE产品,它没有Oracle JDK对使用场景上的诸多限制,可以放心免费下载和使用。它的核心部分就是原汁原味的OpenJDK,没有任何额外的改动——Azul有时候也会对OpenJDK做bug fix,但这些都是通过提交回到OpenJDK去然后再进入到Zulu Java SE产品中的。它与“自己下载OpenJDK源码,自己build”的最大区别是:Azul会在每次发布Zulu产品之前进行充分的测试,build出来的二进制版本符合Java的兼容性测试;同时,Azul有与Oracle签订合作协议,在critical security fix的方面会比公开发布的OpenJDK源码要更早获得补丁,提前做好build与测试工作,基本上可以跟Oracle在同一时...

2018-06-19
如何做性能测试的问题下的答案
试着回答一下这个问题。 首先要划分系统类型:有状态还是无状态,业务系统还是存储系统。根据不同的业务场景,设立性能测试的目标:是要测 QPS,还是 TPS 还是 TPS,还是任何其他【性能】-从广义来讲,一个存储系统到底能够以多高的平均时延来管理大多的存储空间,可能也是性能的一种。 有了性能测试的目标,接下来就是拆解用例。如果把性能测试归为测试的话,测试就需要测试用例,测试用例只是用例的形式化表达。把用户的使用场景勾勒出来,把每一步拆解成的流程图或者时序图–我们已经得到了一个纸上的集成测试计划,只是没有跟性能挂上钩。 接下来就进入真正写测试用例的环节了。 我们的测试报告如果要涵盖足够立体的信息,则既要了解每一个环节/接口/API 的性能指标,又要了解整体的性能指标。 这个时候测试工具的覆盖面就很重要了。如果我们选择偏黑盒的测试工具,apache ab /JMeter,则我们的测试用例就要围绕着对外交互的 API写,也只能测到外围接口的性能。这样的测试用例写起来最简单,无需侵入任何内部代码中。 如果我们使用了 JMH 一类的工具,则可以自由编写对任何方法的测试用例。但需要对系统有非常...