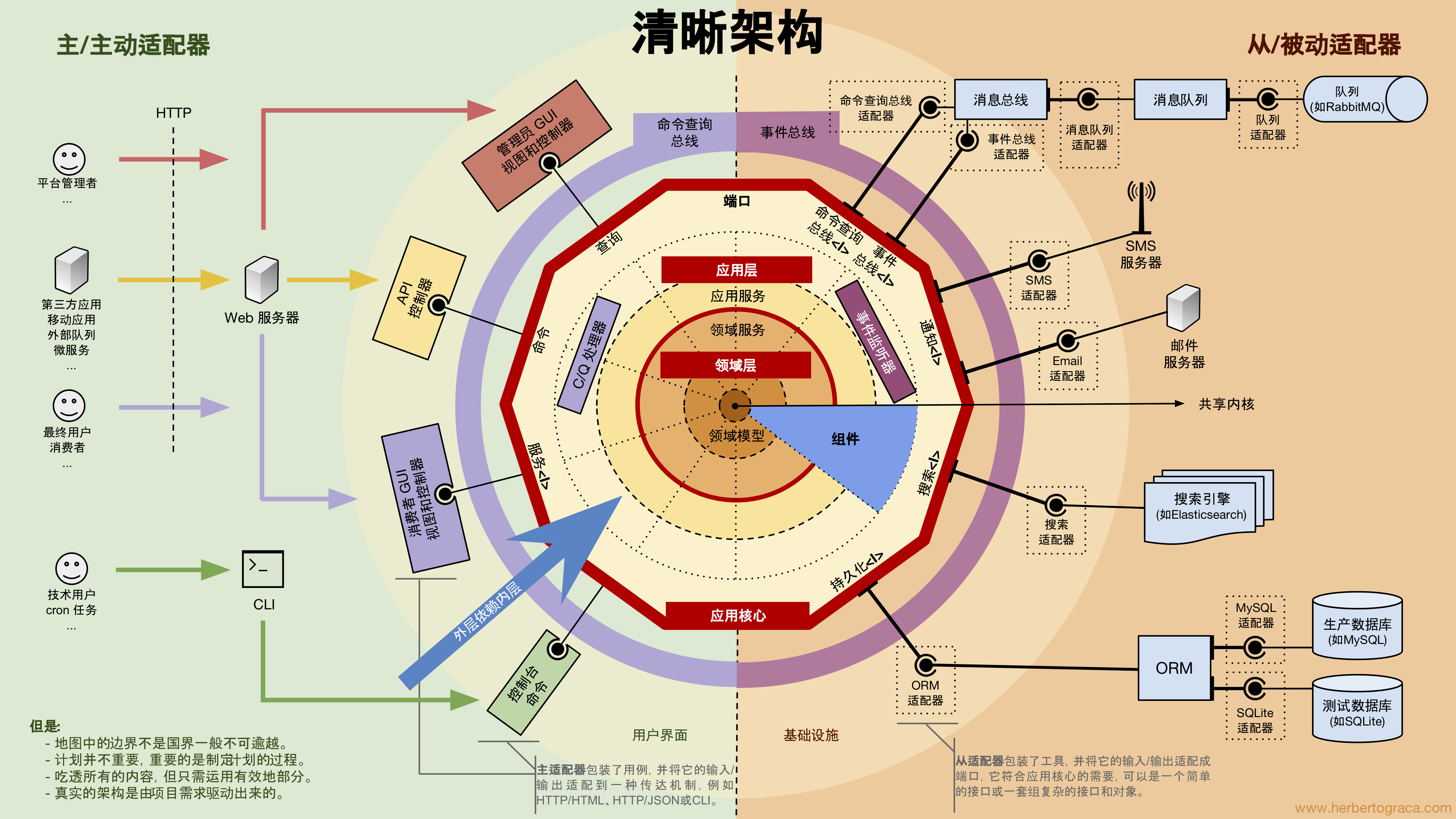
演进式架构
如果读一本书,没有附带正确的复盘(提出反馈并总结反馈),则浪费了这次读书的完整机会。
复盘需要经过痛苦的思索,把一些之前自己没有办法充分接受的观点,充分接受。
本书是一本讲战略的书。
这本书告诉我们很多概念,一旦加上“架构”前缀,突然就有了特殊的含义:架构特征(architectural characteristic)、架构量子(architectural quantum)、架构维度(architectural dimension)、架构模式(architectural pattern)。
新时代的架构愿景-怎样用敏捷的方式来拥抱变化?
架构难以被修改是由架构本身的不变性决定的,架构天然就是难以修改的。
有些人可能认为,就好像建筑业的实践那样,应该先完成这类架构设计,再开始开发。但需求是快速变动的这一事实告诉我们,我们可能要经常修改我们架构,以拥抱需求变化。
“需求总是在动态变化的”,比“架构应该是被预先确定”,更加像是一个事实(后者更加像是一个观点)。
当代的架构是:
- 不断努力的结果
- 【能够响应不断变化的需求和外部人员的反馈】
实施这种架构以替代传统架构,是需要决策者(技术领导者或者架构师)展现技术领导力的。
这种架构的关键只有一个:采取小步变更。这是所有的敏捷团队长期以来一直都已经在实践中执行的动作(实践在此刻先于理论)。但让响应式架构的小步变更不同于其他敏捷实践的一些其他特征还有:要综合运用一些现代交付技术的进步,来帮助演进式架构可控而灵活地演进,这些技术包括:持续交付(最重要的是,它所带来的流水线技术);以及对架构状态的监控-适应度函数(fitness function,这个概念是被演化计算率先引入计算机科学中的,在工程实践中被广泛运用,也有翻译作健康度函数的。遗传算法用它来定义“何为成功”)。
软件是 21 世纪最重要的东西,我们必须学习以更好的姿态来应对变化。
架构的范围与定义
何为演进式架构
架构的范围且内涵是不断变化的,开发人员唯一知道的事情是,“重要的东西”(必须早期就做出的,不易变动的决定)是软件架构。
架构师设计架构时要考虑的第一个因素,是业务需求(在这里我们可以把业务需求当成领域需求来看,甚至可以把领域需求当作一个通用词),但业务需求还要搭配大量的其他因素:安全性、可伸缩性。Neal Ford 与 Mark Richards 在姊妹篇《Fundamentals of Software Architecture》中罗列了高达数十种架构特征(按运维性、结构性、跨领域三类归纳)。架构师只能考虑有限个特征
随着时间的推移,我们的架构要演进,但我们又要保护重要的架构特征。所以演进式架构尝试告诉我们:要用一种新的方式思考架构和时间,引入持续架构(即没有终态的架构)。
在没有演进式架构的思想以前,为未来做战略性规划,就已经是架构师都喜欢做的事。除非因势利导,否则不断变化的软件开发环境会让规划非常难做,很难做得准。
向高度动态的系统引入(单一维度的、极致优化的)变化,容易产生无法预料的结果(下文会提到,这个叫比特退化)。引入一项变化可能会导致旧的平衡被打破,新的平衡出现。
持续交付是一项重大改进,它让过去孤立的功能(如运维)合并到了软件开发的生命周期里,让对软件的改进变得更加可控。
技术发展也让以前我们在架构设计的时候必须考虑的问题变得无足轻重了。比如以前编程的时候,共享资源的效率是必须重点考虑的问题;而在现代的软件架构里,架构师只要考虑怎样合理地运用云,就自动获得了更高的效率。运维问题也可以照此理解——容器化、声明式编排、托管服务把"机器/网络/存储应该长什么样"从开发者的日常关注里抽走了。
预测变化是很难的,而软件架构真的是“难以变更的部分”吗?这类自证式的预言带来的结果是:因为架构师认为架构是难以变更的,所以倾向于不变更架构,于是架构真的是难以变更的了。如果我们改用“易于改变”的原则来看待架构,我们可以期待出现一组全新的架构行为出现。
很遗憾,架构有时候不仅难以变更,而且还可能出现“比特退化”的情况。架构师有可能选择特定的架构模式来满足业务需求,突出某类能力。但这种设计很容易退化,比如,很多开发人员会绕过分层,破坏架构风格,无分层,则所有隔离变化的设计都会逐渐消失。所以这引入一种架构师的思维模式:我们只能选用一种架构模式或者风格,或者使用某些特定的组件,来保证架构具有某些特征。
演进式架构拥有演进能力,否则不足以称为演进式架构。演进能力就是系统演进的时候保护其他架构特征(包括元特征和其他特征)的能力。
演进式架构的定义是:支持跨多个维度的引导性增量变更。
演进式架构的大白话定义:我们有一个架构,已经找到了若干个需要专门保护的架构维度上的架构特征,我们围绕架构特征定义了适应度函数,通过适应度函数指导我们做可控的变更,逐步引入新的功能,或者增强旧的功能。
何为增量式变更(incremental change)
增量式变更具有以下特点:
- 小范围
- 模块化
- 高度解耦
引导性变更(guided change)
适应度函数原本是用来评估某个算法是否能够达到我们的预期。在此处我们是用来表达,我们要有办法度量我们的架构特征,保护他们不随着架构演进而发生退化。
我们有多少种需要关注的架构特征,每个架构特征有多少种可用的适应度函数可用?
guided change 在这里其实指的是 fitness function driven development——之所以不叫"适应度函数变更",是因为适应度函数本身不变更架构,它只是给架构师提供方向盘和仪表盘:架构师可以选择改与不改、怎么改,而函数负责告诉他改完之后有没有偏离既定的架构特征。强调"引导"而非"变更",是为了把"度量"和"动作"分开——度量是客观的,动作是人为的。
多个架构维度
软件架构是多维的,一个例子就是:现代软件架构需要考虑运维问题。
维度一定是正交的,常见的维度的例子是:技术、数据、安全、运维和系统。
我们每定义出一个架构维度,都要谨慎地选取适应度函数来保护这个架构维度的架构特征。
康威定律
康威定律告诉我们,一旦开始划定边界来制造组织的团队,我们就是在制造沟通障碍(如果没有充分解耦的话)。按照职能划分团队,可以提高组件的交付效率,但不一定能提高端到端交付的特性价值。人很难改变其职责范围外的事情。康威定律告诉我们:团队变多,可选的方案反而变少。因此出现了“康威逆定律”,围绕服务边界来构建团队(服务边界可以按照领域划分)。后面我们还会谈到,要按照产品的生命周期,而不是项目的生命周期来制定规划。
三个组成部分
演进式架构由三个部分组成:
- 增量变更
- 适应度函数
- 适当的耦合
适应度函数
适应度函数不仅可以在遗传算法里定义何为成功,也可以在机翼制造领域定义具体的管理指标,使用在架构设计领域只是它的其中一个应用而已。“软件架构的适应度函数为某些架构特征提供了客观的完整性评估”。适应度函数提供了架构特征的保护机制。
性能和安全性经常是矛盾的,性能和伸缩性之间也经常需要权衡。所以一组好的架构维度应该是正交且易于互补的:维度之间彼此独立(变更一个不会让另一个意外退化),又能在系统层面合成出整体的架构特征。能找到这样一组维度并为它们各自配上适应度函数,是架构师真正的工作内容。
我们可以从不同维度划分适应度函数:
- 全系统适应度函数=全系统的各个适应度函数的集合。这种集合并不只是加法效应起作用,也可能有乘法作用和减法作用起作用。集合是相互作用的产物。所以我们得到了原子适应度函数与整体适应度函数。
- 我们可以主动触发事件,使用触发式适应度函数;也可以构建一个持续监控系统运行的体系,收集真实的数据,使用持续式适应度函数。
- 我们的适应度函数使用的目标指标如果是预定好的,那就是静态适应度函数(我们通常理解的函数是这样的);如果目标指标可以动态浮动,那就是动态适应度函数。
- 软件里,函数通常意味着可实现的东西,但适应度函数并不是:我们必须定义适应度函数来指导系统演进,但我们只能尽力让适应度函数自动化,有时候还是需要定义手动执行的适应度函数。适应度函数可能只停留在理念上。所以我们要区分自动适应度函数和手动适应度函数。有时候手动适应度函数表现更好,尽管它易出错,而且效率不高。
- 软件里很多变化不是持续发生的,而是偶尔发生的-比如库升级时,这时候我们需要运用临时适应度函数。
理想的情况下,我们应该尽早理解我们系统中最重要的架构特征,并为它构建适应度函数。这在通常情况下很难被简单做到。这需要架构者要么在这类架构里已经有了很长期的实践经验,要么要求架构者有很强的探索能力和判断力。没能提前确立适应度函数,意味着很多重要的关节点没法被把控,也就可能做出短期内看不到,长期看有问题的架构决策。
本文举了一个例子:如果能够尽早意识到安全是一个需要明确考虑处理的架构问题,那么可以尽早集中化地设计安全组件,而不让职责散落在架构中,要使用更高的成本来维护软件架构。
我们要对适应度函数有所取舍:
- 关键维度
- 相关维度
- 不相关维度
我们应该尽可能多地关注关键维度的问题,如果有必要,把这些适应度函数的执行结果放在最显要的地方,在可视化或者可关注的范围内优先重点处理这些架构维度的问题。
本文作者建议,引入年度会议来审查适应度函数,评估适应度函数是否合适。但在现实的组织中,恐怕没有多少人愿意承担这种流程性改进的职责,也不愿意被这些流程性改动所打扰。
Notes:
- 大部分人都不愿意构建适应度函数。
- 因为大部分人不愿意承担复杂测试的成本。
实施增量变更
把前面三块(增量变更、适应度函数、适当的耦合)落到工程实践上,就要回答"靠什么工具链让这三件事真的发生"。这一节的答案是:持续交付的部署流水线——它把"小步变更"和"度量架构特征"两件事在工程层面合二为一。
持续交付是 2010 年发布的工程实践(Jez Humble 与 David Farley 合著的《Continuous Delivery》)。持续交付带来了如下变革:基于工具的自动化构建和发布软件的机制,让我们对软件的生命周期进行管理得到了更深度的掌控,把开发运维连起来讨论。如果把演进式架构视为持续交付的延伸,则可以看到本书填补了理论的空白:
演进式架构能够支持增量变更,如何支持呢?
- 在开发方面如何 build 一个软件?
- 在运维方面如何 deploy 一个软件?
接着,作者举了一个 PenultimateWidgets 公司的例子:
如果要在服务中引入两个版本的 rating service,我们应该怎么设计我们的系统?
- 首先考虑把我们的各个服务都做成 MSA 的一部分,充分解耦。
- 引入服务发现工具,提供请求路由的功能,并对调用进行解耦。
- 发布新服务,依赖服务发现工具实现新旧服务的隔离。
- 当旧的服务依赖流量枯竭后,自动移除掉旧的依赖。
- 这些操作都在 pipeline 的支持下进行。
这已经是在大公司里很成熟的工作模式了,虽然我们没有把这种实践称作“增量变更”(正如我们虽然大量使用 pipeline,我们也不会强调我们在持续集成一样),但事实上增量变更要求的小范围、模块化、高度解耦,我们都可以通过微服务的一些实践来支持:如小颗粒度服务(组件化(Componentization )与服务(Services))支持了小范围、模块化,而强化终端及弱化通道的服务发现机制,实现了任意的服务通讯调度,让解耦可控,如果加上云,我们还可以实现可伸缩的编排。
notes:有大量的问题实际上总是被大厂的团队所解决,只是我们不把它当作一个专门方法论的实践罢了。
构件
任何一个技术组件,都会有需要被升级的一天。我们的一个技术栈里,今天使用 jdbc,明天就可能使用 jpa。我们的架构能否承受住这种升级呢?架构可以用抽象的图表和方程来描述(这是错误的),但这种描述是抽象的,真正运行起来的应用服务,顶住服务运行后的问题,这才证明架构有生命力。
可测试性
难以被工具自动化支持的特性往往是容易被忽略的功能。
测试又是这其中最难、最繁琐,最需要框架支持的东西。相比执行严格的开发准则(伴随居高临下的说教),我们倾向于构建单元测试来捕捉架构违例。这样,开发人员可以专注于领域逻辑,而架构师可以把规范整合为可执行的构件。
不同的团队角色可能负责提出和维护某个方向的适应度函数,多个方向的适应度函数构成了我们的部署流水线。
部署流水线
在持续集成的实现里,持续集成要求持续集成服务器在构建的时候执行一系列(多得惊人)的任务。
多阶段部署鼓励开发者把更多的阶段编排进工程流程里,包括验证、测试和环境准备。在原本工程师们的印象里,部署流水线看起来只是持续集成里提到的一个工具,但现在部署流水线比持续集成更大,是内涵更广泛,囊括全生命周期的一个工具。事实上,美团的 devtools(前身为 pipeline)和腾讯的蓝盾流水线都呈现出现代的多阶段流水线的特点,每个流水线都可要并行或者串行若干个“插件任务”。
本文专门举了一个例子,说明复杂的部署流水线允许并行验证“当前环境的构建/部署”和“将来状态环境的构建/部署”。这种允许扇入-扇出执行的流水线是一般持续集成不支持的,但“支持演进式架构的部署流水线”应该支持。
本文还举了一个例子,说生产环境中使用功能开关可以保障生产环境中的质量。如果恰当使用用户路由的功能,质量保障部门可以在生产环境中进行测试。这点和部署流水线没有关系,重点应该是讲演进式架构应该支持“不会造成破坏的变更”。
本文的重点恐怕是:部署流水线应该支持部署适应度函数,然后我们对架构就有了客观可量化的评估结果。
组合不同的适应度函数
单元测试、压测、功能性测试、混沌工程都是适应度函数的一种。适应度函数的运行环境很多,它们运行的时机也可能超乎我们想象——在部署之后,由某个独立系统模拟客户端运行。Netflix 的 Simian Army 是这类实践的经典代表,2017 年后停止活跃维护、2021 年 3 月在 GitHub 正式归档,其核心能力被拆分为独立工具继续演进:Chaos Monkey 独立到 netflix/chaosmonkey 仓库,Janitor Monkey 被 Swabbie 替代,Conformity Monkey 的功能并入 Spinnaker 后端。混沌工程的理念则被 Gremlin、LitmusChaos、Chaos Mesh 等开源项目继承。
目标
快和稳定通常是不同角色的人要追求的架构目标,实质上它们是冲突的,要学会妥协。数据的结构的变更应该足够缓慢,以求业务的稳定。很多人意识不到:数据即业务,业务即数据。
假设驱动开发
以往我们是基于需求驱动开发。但 Facebook 的经验和《精益创业》告诉我们,不要用收集需求的方式来构建产品,先构建一个最小可用的产品,然后提出假设,使用科学方法验证假设,然后决定产品的发展方向,我们可以用这种方式来理解到底什么是有价值的产品功能,以及为什么某些功能会失败。
传统的敏捷软件开发讲究的是反馈与控制,而假设驱动开发把客户反馈也有效地纳入到我们的决策流程中,我们因此而构建出更有价值的软件。我们能够使用到的具体手段无外乎:
- A/B 测试
- 特性开关。
我们要得到好的客户结果最好使用某些有**“明确指征”的客户行为指标**,甚至交易数据。
架构耦合
耦合是架构中的必然之恶(necessary evil)。追求解耦要以提高开发效率为目标,如果减少依赖而导致了效率下降,就不要解耦。
模块化
模块化意味着逻辑分组,组件意味着物理分组。
由此出发,库是一类组件,而服务是另一类组件。有库相关的问题,存在于本地地址空间之内;也有服务相关的问题,存在于网络连接的地址空间之内。
架构的量子和粒度
软件系统以各种方式相互联接。软件架构师通过许多不同的视角分析软件。但是组件级的耦合并不是联接软件的唯一方式。许多业务概念在语义上联接系统的各个部分,这便产生了功能内聚。要想使软件成功地演进,开发人员必须考虑所有可打破的耦合点。
架构量子则是具有高功能内聚并可以独立部署的组件,它包括了支持系统正常工作的所有结构性元素。
举例:在单体架构中,量子就是整个应用程序,每个部分都高度耦合,因此开发人员必须对其进行整体部署。我们经常讲的“原子 api ”是架构量子内部的组成元素,虽然这种 api 内部也是“由强核力绑定在一起”,“不可再分也难以再分”的。架构量子是部署单元,api 和各种 bean 是内部组件和库。
到这里本文重点讲了限界上下文:
限界上下文内部的元素(在 DDD 中是模型),在限界内可见,在限界外不可见(此处作者似乎把聚合根的概念专门引入了进来)。限界上下文创建了很多组织梦寐以求的“全局可复用的通用实体”。限界上下文告诉我们,每个领域模型在具体上下文中表现最佳,而且组织内不需要创建统一的单一模型,我们只在集成点协调差异即可。
作者指出了一个洞见:微服务定义了物理限界上下文=架构量子,封装了所有可能变化的部分,划定了架构量子的边界。这种观点真的令人耳目一新。由此推导出去,团队定义了组织限界上下文,他们也应该封装变化。
架构在真正运行起来以前是抽象的,我们要谨慎地选择架构量子的粒度大小,即 DDD 中的 conceptual contour 关注的问题。
不同类型架构的演进能力
软件架构存在的原因是为了实现跨特定维度的某种演进-便于变更是架构模式的原因之一。可以从三个演进条件来考察,不同架构模式的演进能力的好坏:
- 增量变更
- 适应度函数
- 适当的耦合
大泥团架构
Brian Foote 和 Joseph Yoder 在 1997 年的论文中定义了"大泥团"(Big Ball of Mud):一种随意的、甚至草率的系统结构,其组织方式由权宜之计而非设计决定。讽刺的是,这可能是现实中最普遍的软件架构模式。
从演进式架构的三个条件来看,大泥团架构的演进能力都很差:
- 增量变更:由于缺乏模块边界,任何变更都可能产生不可预测的连锁反应,无法做到"小范围"变更。
- 适应度函数:没有清晰的架构特征可以度量,适应度函数无从定义——甚至无法回答"这个系统的架构特征是什么"这一基本问题。
- 适当的耦合:大泥团的本质就是全局耦合,所有组件与所有组件之间都可能存在直接或间接的依赖。
单体架构
单体架构是把所有业务逻辑、数据访问、UI 渲染都打包到一个部署单元里——它仍然是当今最常见的架构形态。按内部组织方式由乱到整,可以分为四类:
-
非结构化的单体架构:本质上和大泥团接近,组件之间随意调用,演进能力极差。
-
分层架构:按 UI / 业务逻辑 / 数据访问层水平切分。技术上职责清晰,但跨层修改一个特性往往要改 UI/Service/DAO 三层,业务变化不沿着分层边界发生。
-
模块化的单体架构:按业务领域(而非技术分层)划分内部模块,模块之间通过明确的接口通信、不允许直接访问内部数据。
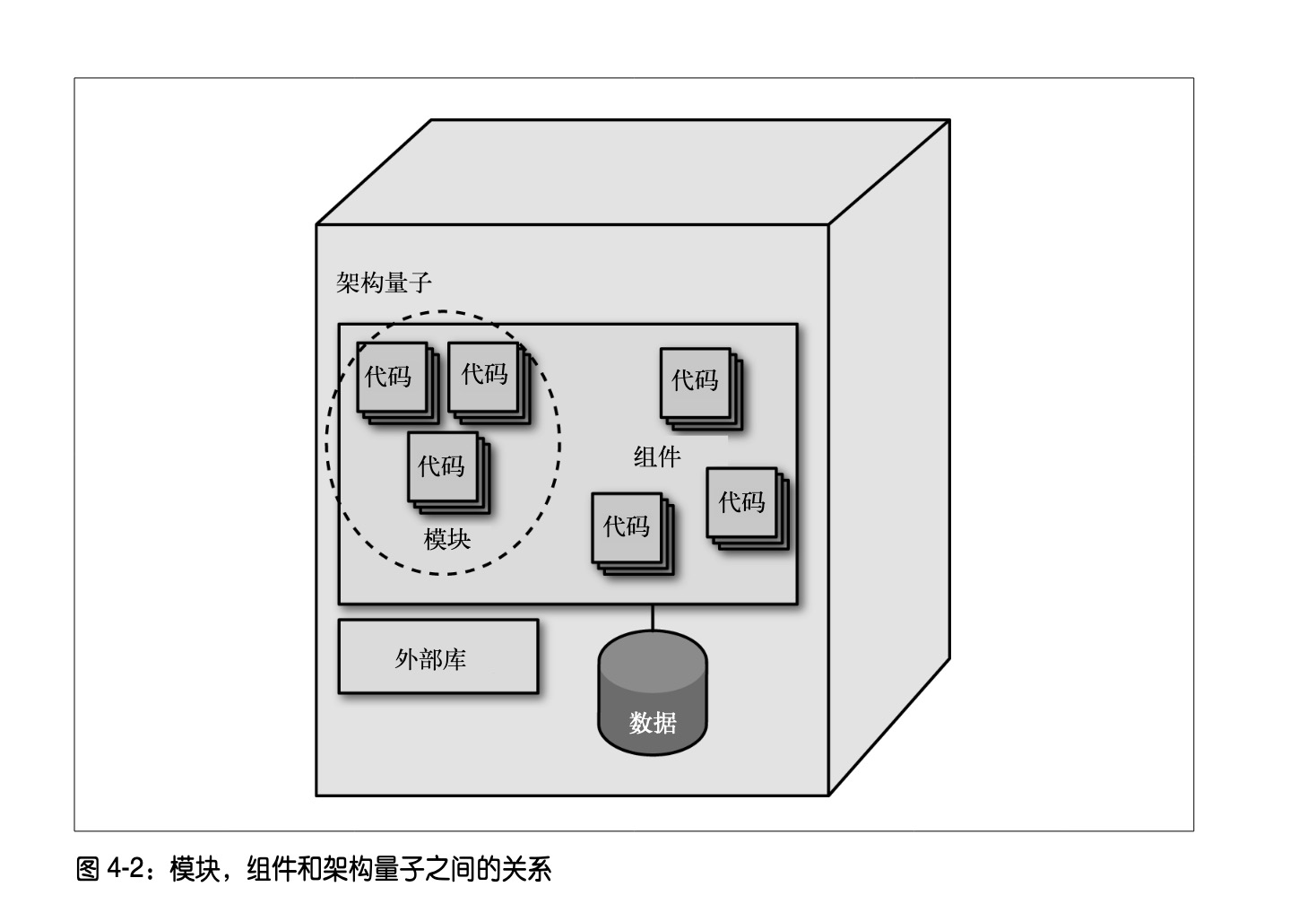
架构量子虽然仍然是整个应用,但模块边界给后续向微服务演进留出了清晰的拆分线。这种架构的演进能力不错。
-
微内核架构:核心系统只提供必要的基础能力和扩展点(钩子),业务功能以插件形式接入。Eclipse、IntelliJ IDEA、VS Code、Chrome 浏览器扩展系统都是典型的微内核实现。它的好处是:
- 扩展点是钩子,新功能不需要修改核心代码,演进局限在插件内部。
- 插件与生俱来有隔离性,单个插件的失败不会拖垮整个内核。
- 这种架构的演进能力不错,但要求架构师在早期就识别出"哪些是核心、哪些是可插拔的扩展"——这条边界画错了,后期纠正成本极高。
事件驱动架构
事件驱动架构(Event-Driven Architecture, EDA)的核心抽象是"事件"——业务上发生的、不可变的事实(如"订单已支付"、“客户已搬家”)。组件之间不直接调用,而是通过订阅事件来响应业务变化。这种架构的演进能力天然较强:新增一个消费方不需要修改生产者,只要订阅事件即可;下线一个消费方同样不会反过来影响生产者。事件驱动架构按协调方式可以分成两个子类——代理模式(broker)和中介模式(mediator)。
代理模式
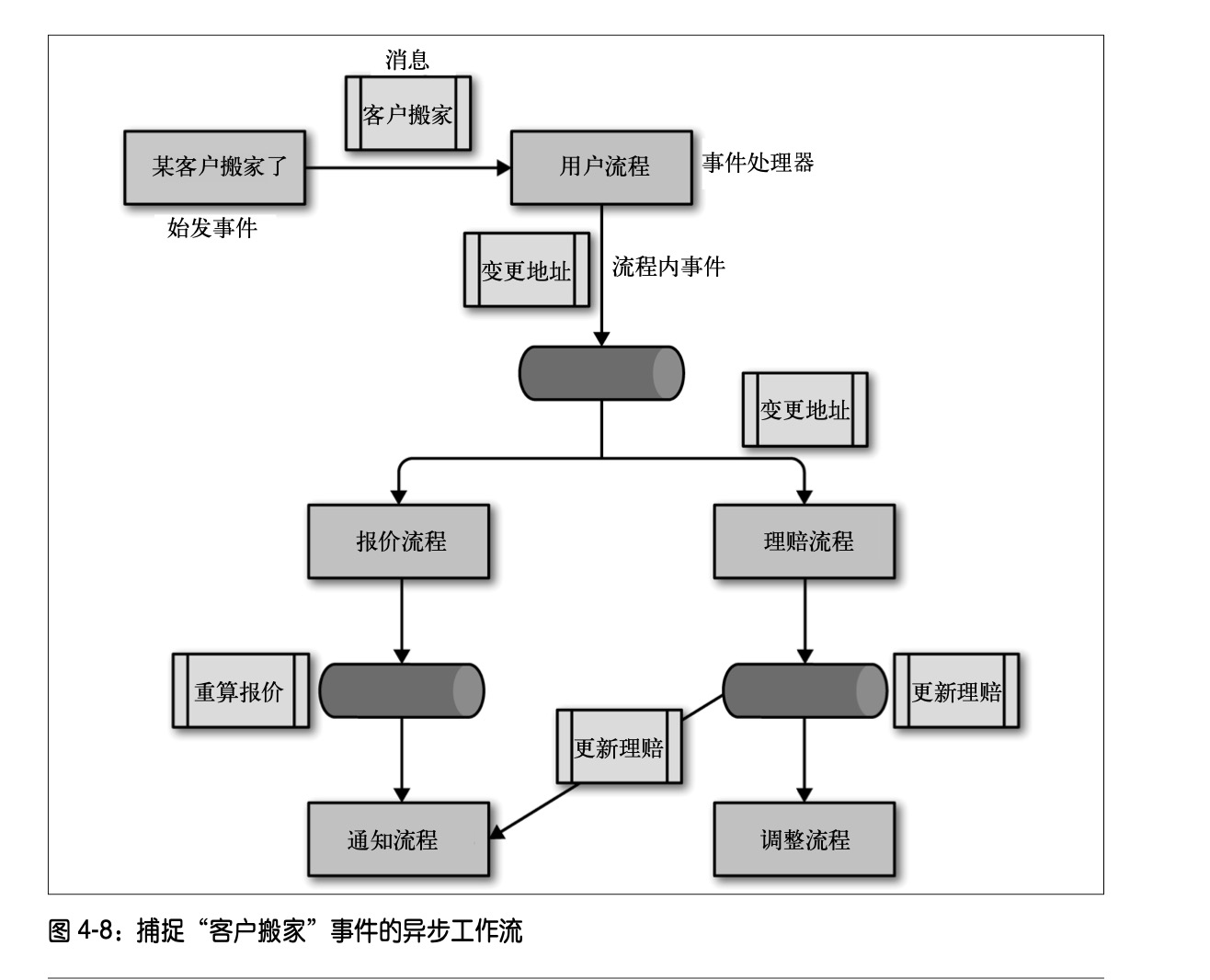
代理模式没有"中央指挥",各组件只认事件不认彼此。它有四大组成部分:
- 消息队列:事件的传输管道,常见实现包括 Kafka、RabbitMQ、Pulsar。
- 始发事件:触发整条业务流的第一个事件,通常由用户行为或外部系统产生。
- 流程内事件:事件处理器处理一个事件并执行业务逻辑后,再发出新的事件来推进流程下一步。
- 事件处理器:彼此不直接通信,因此系统易于横向扩展,这是这种架构模式演进能力强的基础。但松散的通信也让端到端调试和测试变得困难——你需要重建整条事件链才能复现一次业务流。
中介模式
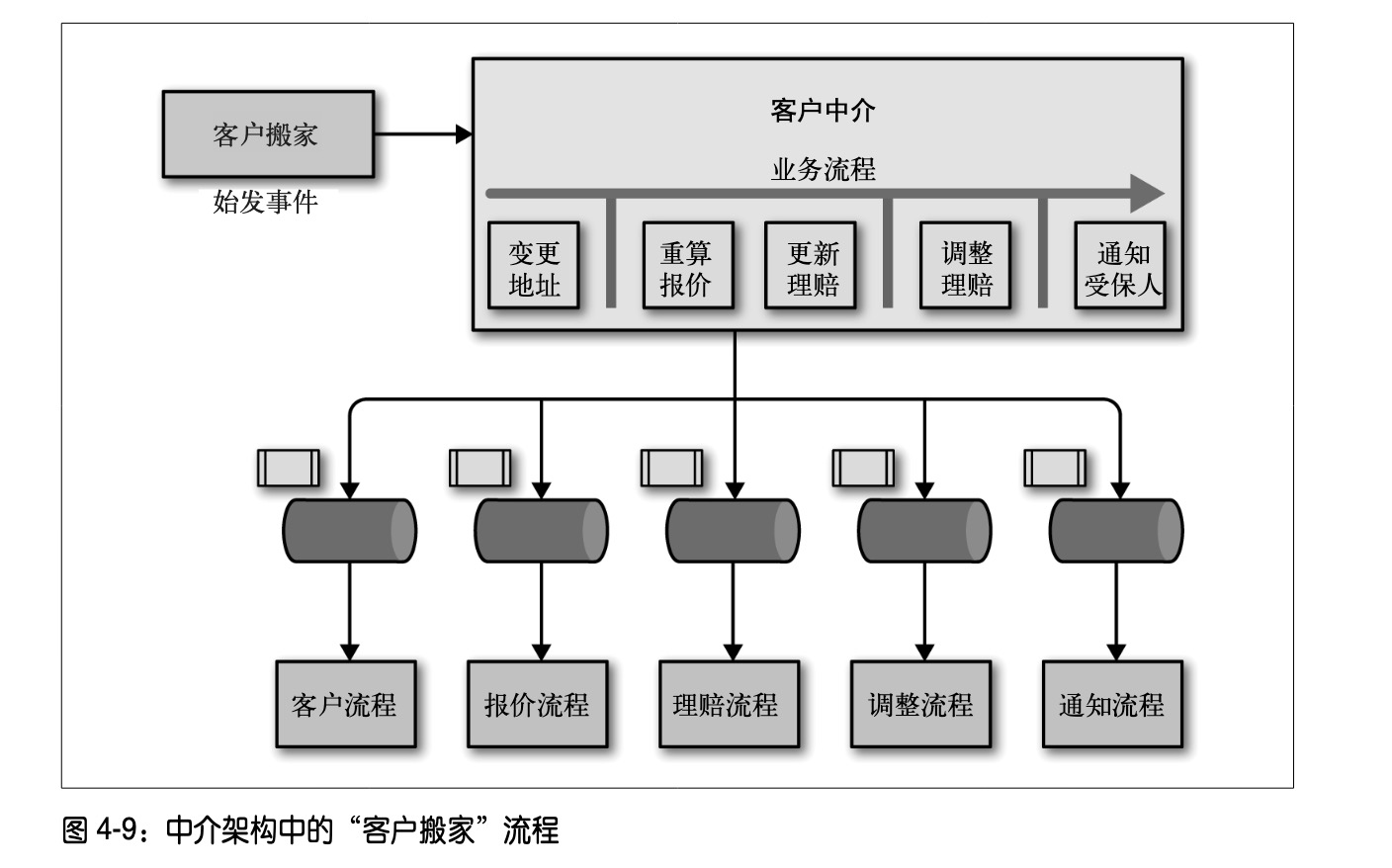
中介模式的中介有一种强协调的特性,一个组件管控大量的流程,主动控制对多个流程和消息队列进行管控,这个组件被称作消息总线。
消息总线的出现,提高了架构量子的颗粒度,易于通过适应度函数进行测试,但也增大了耦合的粒度。
服务导向架构
服务导向架构(SOA)是 2000 年代企业级软件的主流范式,核心思想是把企业能力拆成可被远程调用的"服务"。但 SOA 是一个相当宽的伞——根据"服务的粒度"和"耦合的中心化程度"不同,可以分出 ESB 驱动的重量级 SOA、微服务、基于服务的架构、无服务架构等子类。演进能力沿着这个序列单调递增:架构量子越小、中心化协调越少,演进能力越强。
企业服务总线驱动的 SOA
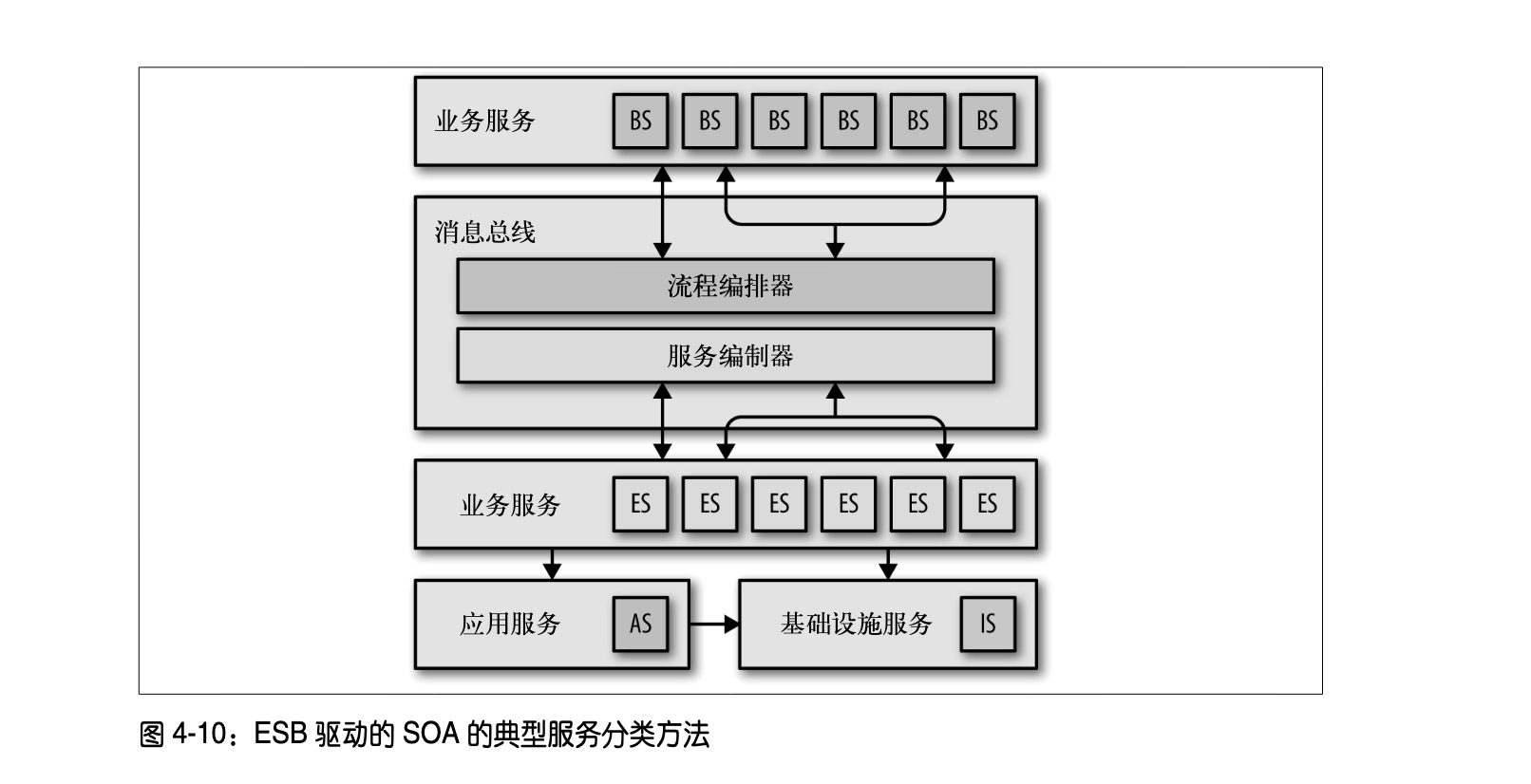
- 每个 ES 和 BS 遵循 BPEL 的描述,通过抽象来描述业务。所有的服务按照 service catalog的分类方法进行分类。
- 使用 ESB,通过编排来缝合服务。
- 应用服务是类似通用域的架构区域。
- 基础设施服务是类似支撑域的架构区域。
ESB 维护注册表,管理调用顺序,能够自带 Translator 和 ACL
ESB 驱动的 SOA 的架构量子很大,基本包含整个系统,而且是分布式的,是很多架构师经常讲的分布式单体(distributed monolithic)。在这种架构模式里,全局有统一的 customer 领域模型,这和ddd和微服务的架构模式相反,但服务分类方法(service catalog)使常规变更变得非常非常困难。
这种架构有如下的缺点:
- 进行常规增量变更需要引入大量的协调——这和"中台战略"要集体排队上线有很大的相似性。实际上单一的领域概念会被打散到很多服务中,任何一次有意义的业务变更都要跨多个 service catalog 中的服务协同。
- 分布式架构让这个单一的架构量子更难以进行适应度函数引导变更。
- 如果这个业务很成熟,这种架构为精华的抽象和软件复用提供了最大的平衡。否则,谈不上合理的耦合。
这种架构不适合演进,只有高度成熟的业务,可以把这种架构作为演进的最终形态。在早期这种架构之所以成为软件架构的主要模式,是因为没有云,需要独立的操作系统和主机,才能支持独立的部署单元。下文讲的微服务架构,改变了这种局面。
微服务架构
可以说,本节讲的微服务天然就和云原生、ddd有密切的关系。
简单的分层架构不能围绕领域来构建,会制造高耦合而不适合变更。
本书作者讲的微服务:
- 围绕业务领域建模,而不是围绕实体建模。
- 隐藏实现细节:每个领域一个物理限界上下文。这样可能出现 domain 大于限界上下文的情况。
- 高度去中心化:share nothing。允许不同服务中拥有 item。其目标是尽可能地减少耦合。通常重复好于耦合
- 独立部署。
- 隔离失败:舱壁模式。
- 高度可观察。
作者在讨论三大特征的时候专门提到服务模板:把一个服务运行所需的基础设施(日志、监控、健康检查、配置中心接入、链路追踪埋点)固化在模板里,团队只要扩展这些模板并编写自己的业务行为即可。这一思路在 Dropwizard、Spring Boot、以及国内的 Spring Cloud Alibaba、Quarkus、字节内部的脚手架工具里都有完整的实现。服务模板既保证了治理能力的统一(适应度函数有地方落地),又让每个团队保有领域自治,是微服务架构在工程层面能跑通的关键基础设施。
从演进能力上看,微服务在三个条件上几乎都是满分:
- 增量变更:每个服务独立部署、独立伸缩,变更范围天然受限于服务边界。
- 适应度函数:每个服务都可以独立挂载架构测试、性能测试、契约测试,CI 流水线粒度与架构粒度对齐。
- 适当的耦合:share nothing 的设计原则把耦合控制在 API 契约层面,"通常重复好于耦合"是这种架构特有的取舍智慧。
代价是分布式系统本身带来的复杂度(服务发现、配置管理、可观测性、分布式事务),这些复杂度需要由平台工程或服务网格(Service Mesh,如 Istio、Linkerd)来吸收,而不是让每个业务团队各自处理。
基于服务的架构
这是一种更大颗粒度的微服务,虽然它仍然围绕领域概念构建。它的典型特征是:
- 更大颗粒度:一个服务通常对应一个完整的业务子域,而不是像微服务那样对应一个限界上下文。
- 使用单体数据库:所有服务共享一个数据库——在金融核心、保险中台这种事务边界极强的场景下,强行拆库反而会引入分布式事务的复杂度,单库共享是务实的妥协。
- 使用集成中间件:甚至直接使用某种总线(如 ESB)来缝合服务,但不像 ESB 驱动的 SOA 那样把业务流程也描述在中间件里。
从演进能力上看,基于服务的架构是"在保留事务一致性"和"获得部分增量演进能力"之间的平衡点——它牺牲了"每服务一库"带来的解耦红利,换来了不必拆分核心事务的工程简单性。典型应用场景是中大型企业的核心系统(核心银行、保险定价、ERP),这些系统对事务一致性的要求往往高于对独立演进能力的诉求。
无服务架构
无服务(Serverless)不等于"没有服务器",而是指开发者不再需要为服务器的存在负责——它把运行时、伸缩、容灾等基础设施关切完全交给云服务商。无服务架构主要有两种形态:
- BaaS(Backend as a Service):把后端能力(认证、数据库、推送、对象存储)整体托管给第三方,业务代码退化为"前端调用 SDK"。Firebase、Supabase、AWS Amplify 是典型代表。
- FaaS(Function as a Service):供应商提供事件触发,开发者只写函数。AWS Lambda、Azure Functions、阿里云函数计算属于这一类。
无服务架构把技术复杂度的架构维度问题转嫁给了云服务提供商,从演进式架构的三个条件来看:
- 增量变更:单个函数粒度的部署,变更范围天然受限——演进能力极强。
- 适应度函数:受平台限制,深度可观测性和复杂的混沌实验较难实施;冷启动延迟、并发上限等约束是函数自身无法独立度量的。
- 适当的耦合:架构量子极小,但对供应商的耦合度极高——一旦云商提价或改变事件契约,迁移成本不可忽视,需要用防腐层和供应商无关的中间抽象(如 Serverless Framework)来缓解锁定。
确保问题域与架构方案相适应,不要强行使用不适合的架构。 无服务对流量稀疏、事件驱动、突发负载的场景(如图片处理流水线、Webhook 处理器、定时任务)几乎是完美匹配;对低延迟、长连接、状态密集的场景则未必划算。
控制架构量子的大小
架构量子越小,演进能力越强。有明确定义的集成点(integration point),会使演进更容易。
演进式数据
数据是架构演进中最棘手的维度。应用代码可以在几天内重写,但数据和数据模式的生命周期往往比应用本身更长——应用是数据的消费者,数据才是业务资产的核心载体。
数据库与架构量子的关系
微服务不适合事务性很强的系统。不要让架构粒度比业务粒度还小,这样的架构量子本身要组成完成业务流,需要分布式事务(如两阶段提交、Saga)来维持一致性,复杂度急剧上升。基于服务的架构——金融核心或者保险中台的模式——在这种场景下是更务实的选择:用更大粒度的架构量子来包含完整的事务边界。
在微服务架构中,“每服务一库”(Database per Service)是理想模式:每个服务拥有独立的数据存储,通过 API 而非共享数据库来交换数据。这种模式的好处是消除了数据层的隐式耦合——服务 A 的数据库 schema 变更不会影响服务 B。但现实中,很多组织的遗留系统使用共享数据库,多个服务直接读写同一组表,这使得任何 schema 变更都可能影响所有消费方。
演进式数据库设计
如果一个系统切换数据库需要 2 年时间,则这个系统是不可演进的;如果只需要 2 周时间,则它是可演进的。
数据库的演进能力依赖于以下实践:
- 数据库迁移工具:Flyway 和 Liquibase 是两个主流的数据库版本管理工具,它们将 schema 变更表达为版本化的迁移脚本,纳入部署流水线管理。每个迁移脚本都是一个增量变更,可以被审计、测试和回滚。
- Expand-Contract 模式:当需要做破坏性的 schema 变更时(如重命名列、拆分表),先扩展(添加新结构,保持旧结构)、再迁移数据、最后收缩(移除旧结构)。这种模式确保在迁移过程中,新旧版本的应用代码都能正常工作,是"不会造成破坏的变更"在数据层面的体现。
- 数据库适应度函数:可以编写自动化测试来验证数据库的架构特征,例如:检测是否存在缺少索引的外键、是否有超过合理阈值的表列数、是否存在违反命名规范的对象。这些测试作为适应度函数纳入部署流水线,防止数据库的架构退化。
共享数据库的解耦策略
对于不得不共享数据库的遗留系统,可以通过以下策略逐步解耦:
- 数据库视图:为每个消费方创建专用视图,隔离底层表结构变更的影响。
- 变更数据捕获(CDC):通过监听数据库的变更日志(如 MySQL binlog、PostgreSQL WAL),将数据变更以事件形式发布给下游消费方,消除直接的数据库访问依赖。
- 渐进式拆分:先在逻辑层面划分 schema 的所有权(哪些表属于哪个服务),再逐步将表迁移到独立的数据库实例中。
构建可演进的架构
构建可演进的架构,核心原则有三条:
原则一:不要用架构拆分破坏事务的边界。 如果一个业务操作需要跨多个实体保持原子性,那么这些实体应该在同一个架构量子内。为了追求微服务的"纯粹性"而将一个事务拆散到多个服务中,结果是用分布式事务的复杂度去解决一个原本不存在的问题。判断标准很简单:如果两个操作必须"要么都成功,要么都失败",它们就属于同一个架构量子。
原则二:所有的架构变更都要留一手,预防回滚。 演进式架构的每次增量变更都应该是可逆的,至少在短期内是可逆的。这意味着:数据库迁移应使用 Expand-Contract 模式而非破坏性变更;服务上线应通过蓝绿部署或金丝雀发布,保留快速回退的能力;特性开关应该默认关闭,在验证通过后才全量开启。
原则三:不要沉迷于元工作。 写框架、写服务器、写部署工具——这些都是元工作(meta-work),即"为了工作而做的工作"。如果市面上已有成熟的开源方案(如 Spring Boot、Kubernetes、Terraform),应优先采用而非自建。元工作的陷阱在于:它让团队产生"很忙"的错觉,但实际上并没有为业务交付任何价值。架构师应把精力集中在业务领域的建模和适应度函数的设计上,而非基础设施的重复造轮子。
可演进架构的起步检查清单
在将一个现有系统向演进式架构转型时,可以从以下维度自检:
- 部署频率(Deployment Frequency):能否做到每周至少一次生产发布?如果不能,先解决持续交付的基础设施问题。
- 变更前置时间(Lead Time for Changes):从代码提交到上线生产平均要多久?前置时间越长,意味着流水线、评审或环境就绪环节存在阻塞。
- 变更失败率(Change Failure Rate):每次发布中,有多大比例的变更需要热修复或回滚?高失败率意味着适应度函数覆盖不足。
- 恢复时间(Mean Time to Recovery):从发现故障到恢复服务需要多长时间?长恢复时间意味着可观测性和自动化回滚能力不足。
这四个维度就是 DORA(DevOps Research and Assessment)研究多年得出的"高效能团队四指标",可以作为演进式架构成熟度的衡量基准。除此之外还应额外自检一项:最重要的三个架构特征是什么?它们是否有对应的自动化适应度函数? ——这是演进式架构特有的、DORA 没有覆盖的维度。
自动化架构治理
2022 年 11 月出版的第 2 版(新增作者 Pramod Sadalage,副标题改为《Automated Software Governance》)专门新增了第 4 章《Automating Architectural Governance》,将适应度函数从理念层面推进到了工程实践层面,给出了内外向耦合(afferent/efferent coupling)、抽象度与不稳定度、与主序列的距离(distance from main sequence)、圈复杂度、OSS 协议合法性等一批可直接编码的治理度量。
架构测试工具
传统上,架构规则靠文档和代码评审来维护,但人工评审的覆盖率和一致性都无法保证。现代架构测试工具将架构规则编码为可执行的测试,纳入持续集成流水线:
- ArchUnit(Java):以 JUnit 测试的形式编写架构规则。例如,可以断言"controller 包中的类不应依赖 repository 包中的类"、“所有 Service 类必须通过接口注入依赖”、“标注了 @Entity 的类只能被 repository 包访问”。ArchUnit 是目前 Java 生态中最成熟的架构适应度函数工具。
- NetArchTest(.NET):功能类似 ArchUnit 的 .NET 版本,可以验证程序集之间的依赖关系、命名规范和分层约束。
- PyTestArch(Python):Python 生态的架构测试库,验证模块间的导入依赖是否符合预定义的分层规则。
这些工具将架构师的"口头规范"转化为"可执行的适应度函数",每次代码提交都会自动验证架构规则是否被违反——这正是"架构师可以把规范整合为可执行的构件"的具体实现。
架构决策记录(ADR)
架构决策记录(Architecture Decision Record)是一种轻量级的文档格式,用于记录架构决策的上下文、决策内容和后果。每个 ADR 通常包含:
- 标题:简短描述决策内容
- 状态:提议 / 接受 / 废弃 / 替代
- 上下文:面临什么问题,有哪些约束
- 决策:选择了什么方案
- 后果:这个决策带来的正面和负面影响
ADR 与演进式架构的关系在于:架构演进的过程就是一系列架构决策的序列。通过 ADR 记录每次决策的理由和权衡,未来的架构师可以理解"为什么当时选了这个方案",从而做出更好的演进决策——而不是因为不理解历史决策,盲目推翻重来。
ADR 存储在代码仓库中(通常是 doc/adr/ 目录),随代码一起版本化,这确保了架构决策与代码实现的同步演进。
演进式架构的陷阱和反模式
技术架构
反模式:供应商为王
路径是:适应→围绕→病态耦合。组织一开始只是为了集成某个供应商的产品而做少量适配,逐渐地,业务代码围绕供应商的 API 和数据模型生长,最终整个架构都被供应商的技术选型所绑定。到了这个阶段,更换供应商的成本已经高到不可接受——供应商知道这一点,因此可以在续约时大幅提价。
正确的做法是:业务需求驱动技术选型,而不是为了集成软件而编写业务。在引入第三方产品时,应通过防腐层(Anti-Corruption Layer)隔离供应商依赖,使核心业务逻辑不依赖于任何特定供应商的接口。
反模式:抽象泄露
Joel Spolsky 提出的"抽象泄露定律"在架构层面同样适用:当底层实现细节穿透抽象边界暴露给上层时,上层被迫处理本不该感知的复杂度。一旦泄露发生,所有依赖该抽象的组件都被迫与底层实现耦合,架构的变更能力急剧下降。
典型表现包括:ORM 框架泄露 SQL 方言差异、消息队列抽象泄露特定中间件的事务语义、缓存抽象泄露一致性模型。架构师应为关键抽象编写适应度函数(如接口契约测试),以便在抽象泄露发生时尽早发现。
反模式:最后 10% 陷阱
某些工具或框架号称能"自动完成 90% 的工作",但剩余 10% 的定制化需求极难实现,甚至需要 hack 框架内部逻辑。结果是:为了简单地获得前 90% 的达成,团队不得不在最后 10% 上投入与前 90% 相当甚至更多的精力。
这种陷阱在低代码平台、可视化编排引擎中尤为常见。选择技术方案时,应评估的不是"它能帮你做多少",而是"当它帮不了你的时候,你怎么办"——逃逸复杂度(escape complexity)才是衡量一个框架是否适合演进式架构的关键指标。
反模式:代码复用和滥用
代码复用性越高,其可用性越低——因为通用化带来了额外的抽象层和配置复杂度。在微服务架构中,跨服务的代码复用(特别是共享库中的领域模型)会制造隐式耦合:一个共享库的变更可能迫使所有消费方同步升级。
"通常重复好于耦合"这一原则在这里得到了体现。每个服务维护自己的领域模型副本,虽然有重复代码,但获得了独立演进的能力。架构师需要区分技术复用(如工具类、日志框架,适合共享)与业务复用(如领域模型、业务规则,应当谨慎共享)。
增量变更
反模式:管理不当
增量变更要求配套的管理机制跟上:如果管理层仍然按照瀑布模式批量审批大版本发布,增量变更在流程层面就会被阻断。常见的症状是"变更审批委员会"要求将多个小变更合并为一次大发布,这恰好是增量变更试图避免的。管理机制应与技术架构同步演进——小步变更需要轻量级的审批流程、自动化的合规检查和可观测的发布过程。
反模式:发布过慢
如果部署一个变更需要数周甚至数月的准备,那么增量变更在技术上可行,在实践中却无法落地。发布过慢通常源于:环境准备手动化、测试反馈周期过长、上下游协调成本过高。这些问题的解决依赖于持续交付基础设施的成熟度——部署频率是衡量增量变更能力的一级指标。
业务问题
陷阱:产品定制
当产品为每个大客户做深度定制时,代码分支和配置矩阵会指数增长。每一个定制分支都在削弱架构的通用演进能力——修改主干逻辑时,必须在所有定制分支上验证兼容性。正确的做法是:通过特性开关和插件化机制将定制点约束在架构的"扩展表面"上,核心领域逻辑保持统一。
反模式:报表
报表需求往往驱动出大量的跨领域查询,这些查询要求多个服务的数据被聚合到同一个视图中。如果为了满足报表需求而在服务之间建立直接的数据依赖,就会产生强耦合。CQRS(命令查询职责分离)模式在这里是经典的解决方案:为报表构建专门的读模型,通过事件流异步聚合数据,避免报表需求对核心交易流程的架构产生侵蚀。
陷阱:规划视野
组织倾向于做长期的技术规划(3~5 年路线图),但软件开发环境变化极快,长周期规划往往在完成之前就已过时。演进式架构建议采用短视野、多迭代的策略:规划视野不超过 6 个月,每次迭代结束后根据实际反馈调整方向。这并不是说不需要长期愿景,而是说长期愿景应该是方向性的(“成为领域内响应最快的系统”),而非技术路径性的(“两年内全部迁移到微服务”)。
实践演进式架构
本章的核心观点是:微服务架构是当代最契合演进式架构理念的架构模式,但架构模式只是技术侧的选择——组织结构、团队文化和预算模式同样决定了架构能否真正演进。
组织因素
全功能团队
全功能团队(cross-functional team)是演进式架构的组织基础。一个全功能团队应包含交付一个完整架构量子所需的所有角色:开发、测试、运维、产品、UX。当团队拥有端到端交付能力时,增量变更不需要跨团队协调,变更的周期自然缩短。
这与 Amazon 的"两个披萨团队"理念一脉相承:团队的规模应该小到两个披萨就能喂饱,职能应该全到不需要排队等其他团队。
围绕业务能力组织团队
按照康威逆定律,团队的组织边界应该与架构量子的边界对齐。围绕业务能力(business capability)而非技术层次(前端团队、后端团队、DBA 团队)来组织团队,可以最大限度地降低跨团队的变更协调成本。
每个团队负责一个或多个限界上下文,拥有从数据库到 API 到 UI 的完整技术栈所有权。这种组织方式让"谁构建,谁运行"(you build it, you run it)成为可能。
产品高于项目
项目有明确的起止时间,项目结束后团队解散,知识流失。产品思维则要求团队长期拥有某个业务能力,持续为其演进负责。
这种转变的本质是:从"交付一个项目"转向"运营一个产品"。产品团队对系统的长期健康度负责,自然有动力投资于适应度函数和技术债治理——因为他们知道,今天偷的懒,明天还是自己来还。
应对外部变化
外部变化包括:第三方 API 的版本升级、安全漏洞的紧急修复、合规要求的调整、云服务商的策略变更。演进式架构要求团队具备快速响应外部变化的能力,这依赖于:松耦合的架构设计、完善的适应度函数(在外部变化发生时快速检测影响面)、以及足够短的发布周期。
团队成员之间的连接数
Brooks 在《人月神话》中指出,团队成员之间的沟通路径数随人数呈二次增长:n 个人有 n(n-1)/2 条连接。当团队超过 7~9 人时,沟通开销显著上升。
这一规律直接影响架构量子的粒度:团队不能无限大,所以架构量子也不能无限大。团队规模对架构粒度的约束,是康威定律在实践中最直接的体现。
团队的耦合特征
文化
演进式架构需要一种拥抱变化的工程文化:团队成员应当视重构为日常工作的一部分,而不是"技术债清理专项"。这种文化的建立需要管理层的支持——如果重构和新特性开发在绩效评估中的权重严重失衡,团队就不会投资于架构的可演进性。
试验文化
试验文化(experimentation culture)鼓励团队在受控条件下尝试新技术和新方案。这与假设驱动开发一脉相承:先构建假设,再设计实验验证,最后根据数据决策。
Netflix 和 Amazon 的试验文化是出了名的激进:Netflix 的 Chaos Monkey 在生产环境中随机终止实例来验证系统的容错能力;Amazon 通过持续的 A/B 测试来优化用户体验。这些实践的前提是:组织必须能够容忍可控的失败,并从失败中学习。
首席财务官和预算
传统的 IT 预算模式按年度分配,项目制审批。这种模式与演进式架构的持续投资理念冲突:演进式架构需要持续的小额投资(重构、适应度函数维护、技术债治理),而不是大规模的一次性投入。
说服 CFO 的关键论据是技术债的复利效应:每推迟一年治理技术债,未来的修复成本会以复利增长。定期的小额投资远比积累到不得不做"架构大重构"时的巨额投入划算。适应度函数在这里有额外的价值——它能把"架构健康度"量化为 CFO 能理解的指标。
构建企业适应度函数
企业级适应度函数覆盖的不是单个服务,而是整个技术生态系统的架构特征。典型的企业适应度函数包括:
- 技术雷达适应度函数:监控组织内使用的技术栈是否偏离技术雷达(ThoughtWorks Technology Radar 是一个经典参考),确保团队不会引入已被标记为"暂缓"(Hold)的技术。
- 依赖健康度函数:检测所有服务的第三方依赖是否存在已知安全漏洞(类似 Dependabot 的机制,但作为适应度函数纳入部署流水线)。
- 服务间耦合度函数:通过分析服务间的调用图谱,检测是否出现了不合理的跨边界直接调用。
从何开始
容易实现的目标
选择架构中耦合度最低、变更风险最小的组件作为试点。通常是无状态服务、工具类服务或 BFF(Backend for Frontend)层。在这些低风险区域验证增量变更和适应度函数的实践模式,积累经验后再向核心业务推广。
最高价值优先
另一种策略是反过来:选择业务价值最高、变更频率最高的组件开始。这种策略的风险更大,但收益也更显著——如果能在核心业务上证明演进式架构的价值,推广到其他组件时阻力会小得多。
测试
测试是适应度函数最常见的实现形式。从单元测试(验证代码行为)到架构测试(验证分层规则、依赖方向),再到混沌工程(验证容错能力),构成了一个多层次的适应度函数体系。起步时不必追求完美覆盖,先为最关键的架构特征建立自动化适应度函数,再逐步扩展。
基础设施
演进式架构对基础设施有明确的要求:自动化的构建和部署流水线、环境即代码(Infrastructure as Code)、可观测性基础设施(日志、指标、链路追踪)。这些基础设施本身也需要具备演进能力——基础设施的僵化同样会阻碍上层业务架构的演进。
演进式架构的未来
基于 AI 的适应度函数
传统的适应度函数需要架构师手动定义规则和阈值。随着机器学习技术的发展,基于 AI 的适应度函数可以通过学习系统的历史行为模式,自动检测异常和退化。例如:AI 可以分析系统的调用链路数据,自动发现"不应该存在的跨边界调用"——这比手动维护调用规则更灵活,也更能适应架构的持续演进。
2022 年出版的第 2 版中,作者对此话题做了更深入的讨论,特别是大语言模型在代码审查和架构合规检查中的潜在应用。
生成式测试
生成式测试(generative testing)使用随机数据生成器来探索系统行为的边界。与传统的基于固定用例的测试不同,生成式测试可以发现开发人员未曾预料到的边界情况。Property-based testing(如 QuickCheck、jqwik)是这一方向的成熟实践。作为适应度函数,生成式测试特别适合验证系统在各种输入组合下是否仍然保持预期的架构特征。
为什么(不)呢
公司为何决定构建演进式架构
- 市场变化快:如果业务需求每个季度都在变,固定架构无法支撑。
- 技术栈老化:需要逐步替换遗留组件,而不是一次性重写。
- 规模增长:系统从单体成长为分布式架构时,需要可控的演进路径。
- 组织成熟度够:团队具备持续交付和自动化测试的能力。
公司为何决定不构建演进式架构
- 业务稳定且变化极少:如嵌入式系统、监管固定的金融核心系统,演进能力的投资回报率不高。
- 团队规模太小:三五个人的团队,直接重写可能比渐进式演进更经济。
- 一次性项目:交付后不再维护的系统,不值得为演进性投资。
- 技术债务过重:现有系统的耦合度高到连增量变更都无法安全进行时,可能需要先做一次战略性重构,再转向演进式架构。
演化性并不是一个特别需要关注的架构维度时,演进式架构就不那么吸引人了。
商业案例
演进式架构的商业价值最终体现在三个维度:上市速度(Time-to-Market)、变更成本和系统寿命。采用演进式架构的系统,能够更快地响应市场机会(因为增量变更周期短),变更的边际成本更低(因为适应度函数兜底,不需要全面回归),系统的有效寿命更长(因为技术栈可以逐步更新,而不需要"推倒重来")。
Guardian 报社是书中引用的一个经典案例:通过将单体系统逐步演进为微服务架构,在不中断业务的前提下完成了技术栈的现代化。
构建演进式架构
构建演进式架构的完整路径可以归纳为六步:
- 识别受影响的架构维度:确定哪些维度对业务最关键(性能?安全?可用性?)。
- 为每个维度定义适应度函数:从最关键的维度开始,逐步覆盖。
- 使用部署流水线自动化适应度函数:确保每次变更都经过适应度函数的验证。
- 选择合适粒度的架构量子:根据团队规模、业务边界和变更频率确定。
- 实施增量变更:小步快跑,每次变更都是可控的。
- 持续审查和调整适应度函数:随着业务和技术的变化,适应度函数本身也需要演进。
模式速查表
| 关键词 | 模式 | 方案 |
|---|---|---|
| 架构退化 / 分层被绕过 | 适应度函数守护 | 用 ArchUnit/NetArchTest 编写架构规则测试,纳入 CI 流水线 |
| 需求快速变化 | 增量变更 | 小范围、模块化、高度解耦的变更 + 部署流水线自动化 |
| 架构特征难以度量 | 适应度函数分类 | 按原子/整体、触发/持续、静态/动态、自动/手动分类定义 |
| 数据库变更困难 | Expand-Contract | 先扩展新结构→迁移数据→收缩旧结构,配合 Flyway/Liquibase |
| 共享数据库耦合 | 每服务一库 + CDC | 逻辑划分 schema 所有权→数据库视图隔离→CDC 事件流→物理拆分 |
| 供应商锁定 | 防腐层(ACL) | 在核心业务与供应商 API 之间插入防腐层,隔离外部依赖 |
| 框架最后 10% 做不到 | 逃逸复杂度评估 | 选型时评估"帮不了你的时候怎么办",而非"能帮你做多少" |
| 跨服务代码复用导致耦合 | 技术复用 vs 业务复用 | 工具类共享,领域模型各服务独立维护,重复优于耦合 |
| 报表需求侵蚀交易流程 | CQRS 读写分离 | 为报表构建专用读模型,通过事件流异步聚合,不污染写模型 |
| 团队越大沟通越慢 | 康威逆定律 | 围绕业务能力(而非技术层次)组织团队,对齐架构量子边界 |
| 长期规划总是过时 | 短视野多迭代 | 规划视野 ≤ 6 个月,长期愿景只定方向不定技术路径 |
| 架构决策无人记得为什么 | ADR(架构决策记录) | 在代码仓库 doc/adr/ 中记录每次架构决策的上下文、选择和后果 |
| 不知道从哪开始演进 | DORA 四指标自检 | 部署频率、变更前置时间、变更失败率、恢复时间(外加:架构特征是否有自动化适应度函数) |
| Serverless 供应商锁定 | 平台抽象 + 防腐层 | 用 Serverless Framework / SST 等中立抽象隔离云商事件契约,核心逻辑写在普通函数里 |
| 单体到微服务的中间态 | 模块化单体先行 | 先在单体内部沿业务领域划模块,模块边界稳定后再按需拆服务,避免一步到位的物理拆分 |
参考资料
- Neal Ford, Rebecca Parsons, Patrick Kua.《Building Evolutionary Architectures: Support Constant Change》. O’Reilly, 2017(第 1 版)
- Neal Ford, Rebecca Parsons, Patrick Kua, Pramod Sadalage.《Building Evolutionary Architectures: Automated Software Governance》. O’Reilly, 2022(第 2 版)
- Mark Richards, Neal Ford.《Fundamentals of Software Architecture: An Engineering Approach》. O’Reilly, 2020
- Jez Humble, David Farley.《Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation》. Addison-Wesley, 2010
- Eric Evans.《Domain-Driven Design: Tackling Complexity in the Heart of Software》. Addison-Wesley, 2003
- Brian Foote, Joseph Yoder. “Big Ball of Mud”. PLoP '97 Conference, 1997
- ArchUnit 官方文档
- 演进式架构官方网站