
如何排查线上问题
cpu 偏高问题排查
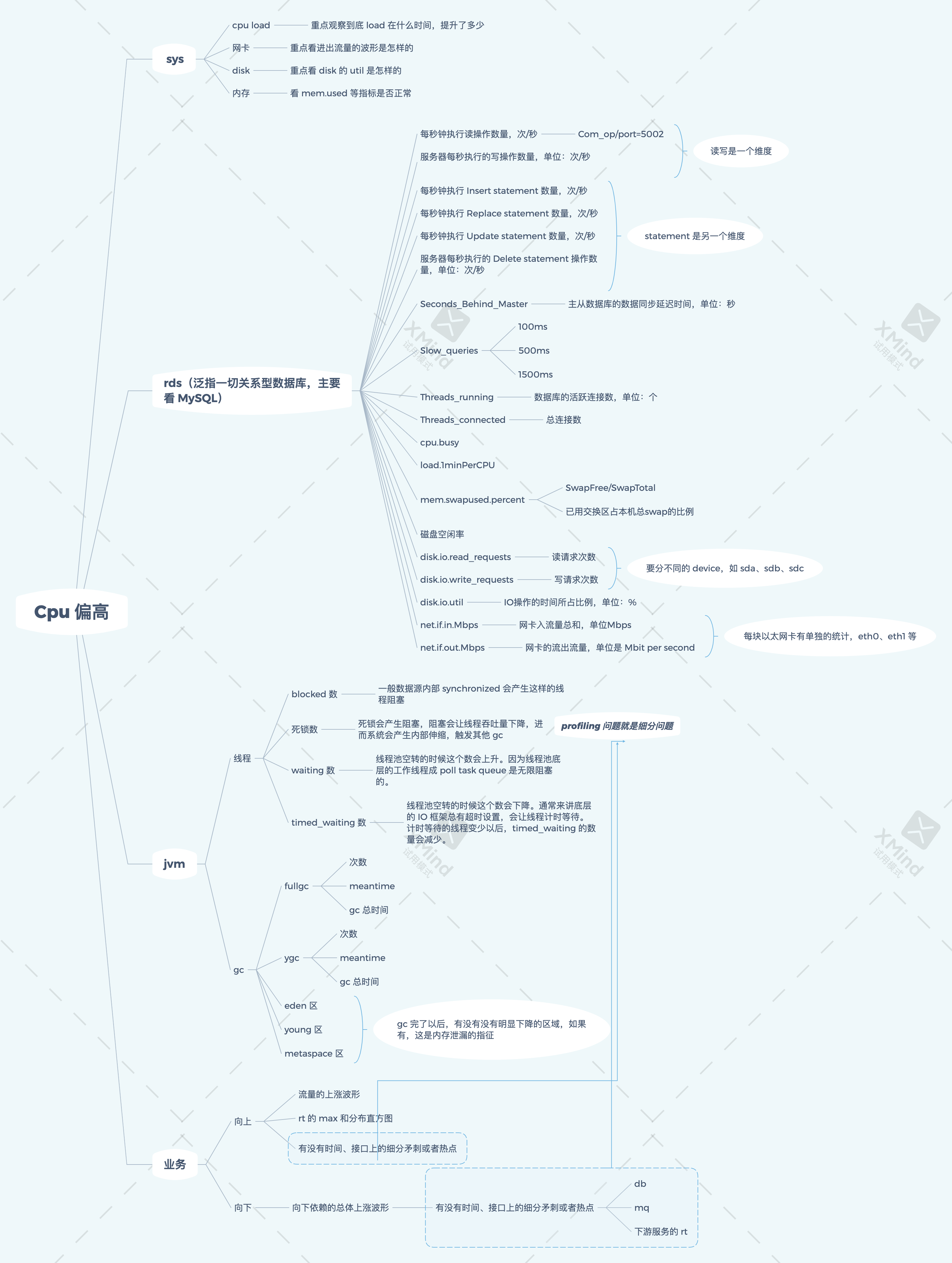
数据库问题排查
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2026-01-19
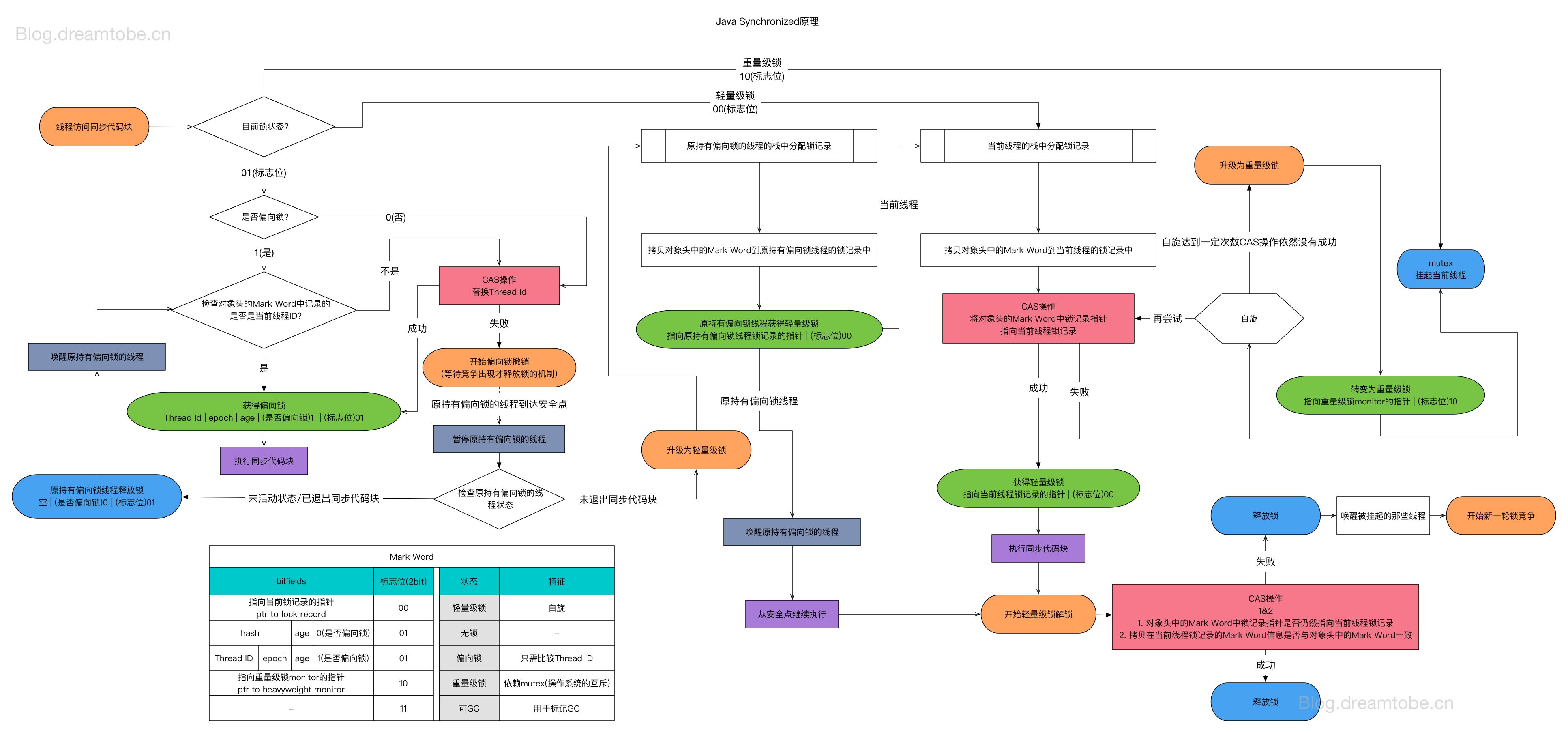
线程安全与锁优化
版本说明:本文主要基于 JDK 6 ~ JDK 14 的 HotSpot 虚拟机实现。需要注意的是,从 JDK 15 开始,偏向锁已被默认关闭并标记为废弃(JEP 374)。如果你使用的是 JDK 15+,文中关于偏向锁的内容仅作为历史参考。 线程安全 什么是线程安全 “当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方法进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。” 相对的线程安全,可以分成五个等级。但在深入讨论线程安全的分类之前,我们需要先理解 Java 内存模型——它是理解线程安全问题的理论基础。 Java 内存模型基础 Java 内存模型(Java Memory Model,JMM)是 Java 语言规范的一部分,定义了多线程程序中共享变量的访问规则。理解 JMM 是理解线程安全问题的基础。 为什么需要内存模型? 现代计算机系统中,CPU 与主内存之间存在巨大的速度差异。为了弥补这一差距,硬件层面引入了多级缓存(L1、L2、L3 Cache)。这带来了一个问...

2026-04-19
Java栈帧省略机制详解:为什么异常堆栈会消失?
引言:诡异的异常堆栈消失现象 线上服务报错时,你打开日志准备排查问题,却发现异常堆栈信息神秘消失了: 1java.lang.NullPointerException 只有短短一行异常类名,没有完整的堆栈跟踪。你可能会怀疑:是日志框架出问题了?还是被什么拦截器截断了? 其实,这是 JVM 的一个性能优化机制,叫做 OmitStackTraceInFastThrow(快速抛出时省略堆栈跟踪)。从 JDK 5 开始引入,默认启用。 本文将深入剖析这个机制的设计动机、工作原理、触发条件,以及如何正确应对。 一、问题场景:异常堆栈去哪了? 1.1 复现现象 用一段简单的代码就能复现: 123456789101112public class ExceptionOmitDemo { public static void main(String[] args) { String msg = null; for (int i = 0; i < 500000; i++) { try { ...
2026-02-07
JVM 的内存模型与线程
JVM 的内存模型与线程 Java 内存模型(Java Memory Model, JMM)定义了多线程环境下共享变量的访问规则,是理解并发编程的基石。本文从硬件架构出发,逐步深入到 JMM 的核心机制与实践模式。 mindmap root((JMM)) 硬件基础 CPU缓存层次 缓存一致性协议 JMM 抽象 主内存 vs 工作内存 八种内存操作 happens-before 关系 关键保证 原子性 可见性 有序性 实践工具 volatile synchronized final 模式总览 # 模式名称 一句话口诀 适用场景 1 写刷读清 写入即刷盘,读取先清空 volatile / unlock 后的可见性 2 顺序锁 同把锁内,串行执行 synchronized 临界区保护 3 偏序传递 A先于B,B先于C,则A先于C happens-before 链式推理 4 不可变安全 构造完成前...
2026-02-07
G1/ZGC/Shenandoah 垃圾收集器对比
垃圾收集的核心挑战 垃圾收集器的设计始终面临三个核心指标的权衡:吞吐量、延迟和内存占用。这三个指标构成了一个不可能三角,优化其中一个指标往往需要牺牲其他指标。 吞吐量指单位时间内完成的工作量,通常用应用程序运行时间占总时间的比例来衡量。对于批处理任务、科学计算等场景,高吞吐量是首要目标。 延迟指垃圾收集造成的应用停顿时间。对于交互式应用、金融交易系统等对响应时间敏感的场景,低延迟至关重要。延迟通常关注最大停顿时间和停顿时间分布。 内存占用指垃圾收集器为了完成收集工作所需的额外内存空间。内存受限的环境下,收集器自身的内存开销成为关键约束。 传统垃圾收集器在三者之间做出明确取舍:Serial 和 Parallel GC 追求高吞吐量,但停顿时间较长;CMS GC 降低停顿时间,但牺牲吞吐量并占用更多内存。现代收集器试图在三者之间找到更优的平衡点。 G1(Garbage First)收集器 G1 收集器在 JDK 7u4 版本正式推出,是 JDK 9 之后的默认垃圾收集器。G1 的核心思想是打破传统分代收集的物理隔离,将堆内存划分为多个大小相等的 Region。 Region 化堆内存...
2017-10-23
昂贵的异常
抛出问题 Joshua Bloch 在《Effective Java》的 Item 57 里明确地提到过,不要试图用 Exception 的跳转来代替正常的程序控制流。他列举了很多原因,但特别提到了抛出异常会使得整个程序运行变慢。抛出异常远比普通的 return、break 等操作对控制流、数据流的性能影响要大,它就只适合拿来作异常分支的控制语句,而不能拿来编写正常的逻辑。 Throwing exception is expensive. 这句话在 Java 的程序员世界里面已经成为老生常谈,却很少有人谈及到底抛出异常比正常的程序跳转返回慢在哪里,有多慢。"不要滥用异常"好像一个猴子定律,人们知道不能这么做,却不明白为什么不能这么做。 此前读了一位同事写的好文《Java虚拟机是如何处理异常的》,深入地分析了 JVM 对异常跳转的处理过程:JVM 会通过异常表的机制,优化异常抛出和正常返回之间的性能差异。仅从程序计数器的移动上来讲,抛出一个异常对栈帧的弹栈并不比直接返回更昂贵。写在前头的结论是:"try-catch 语句块几乎不会影响程序运行性能!...
2017-12-24
client 与 server
client 模式 默认的jit编译器,c1。 默认的gc:serial-serial old。 需要更短的启动时间和初始堆大小,能做更保守的优化。 默认-Xms是1M,-Xmx是64M。 适合 GUI 程序。 server 模式 默认的jit编译器,c2。 默认的gc:ps-serial old即 PS MarkSweep(可以启用parallel old)。 需要更长的启动时间和更大的堆大小,能够做更有深度的优化。 默认-Xms是128M,-Xmx是1024M。 适合长时间运转的程序。 64 位JVM# 在64位 JVM 上有个 -d64 的模式,实际上就是禁止client模式单独启动,只允许server模式或者混合编译模式启动的模式。