HTAP 问题
问题定义
AP 的出现
在互联网浪潮出现之前,企业的数据量普遍不大,单机数据库就足以保存核心业务数据。那时候的存储不需要复杂架构,所有线上请求(OLTP,Online Transaction Processing)和后台分析(OLAP,Online Analytical Processing)都跑在同一个数据库实例上。后来业务越来越复杂,数据量越来越大,问题随之而来:单机数据库支持线上 TP 请求已经非常吃力,再跑较重的 AP 分析任务无以为继。AP 由此从 TP 系统分离,某种程度上 AP 是 TP 的一个分支。
这等于在存储层做读写分离的架构设计;另一种思路是在应用层做读写分离。
AP 的玩法
在这种背景下,以 Hadoop 为代表的大数据技术开始蓬勃发展,它用大量相对廉价的 x86 机器构建了一个数据分析平台,用并行能力破解大数据集的计算问题。
AP 系统的典型技术栈演进:
| 阶段 | 代表技术 | 特点 |
|---|---|---|
| 第一代 | Hadoop MapReduce + Hive | 批处理,延迟高(分钟到小时级) |
| 第二代 | Spark + Spark SQL | 内存计算,延迟降到秒级 |
| 第三代 | Flink + 实时数仓 | 流批一体,延迟降到毫秒级 |
| OLAP 引擎 | ClickHouse、Doris、Druid | 列式存储,面向特定分析场景优化 |
TP 和 AP 的联系
虽然 TP 和 AP 走向独立演进,但核心都需要处理数据,因此必须打通。业内通行做法是把 TP 数据通过 ETL 工具抽取出来,导入独立的 AP 分析系统。业务数据库专注 TP 能力,分析平台专注 AP 能力,各司其职。

为什么需要 HTAP
挑战
通过 ETL 桥接 TP 和 AP,数据基本可以做到 T+1(小时、天、周等)的时效,解决了 TP 系统兼做 AP 的性能与隔离难题,但也带来了一些新问题:
a)复杂性:TP 与 AP 是高度独立的系统,中间搭建 ETL 实质是一次比较复杂的数据集成。业内常见工具如 Sqoop、DataX、DataPipeline 都需要二次开发。ETL 链路本身还要运维和监控,进一步抬高了系统整体复杂度。
b)实时性:ETL 是周期性过程,一般按 T+1 做数据同步,无法满足部分实时分析和统计需求。随着业务对实时性要求越来越高(实时风控、实时推荐、实时大屏),T+1 延迟越来越不够用。
c)一致性:TP 系统数据错乱往往会导致 AP 系统在回溯数据时无法幂等,从而引入不一致。ETL 过程中的失败重试、数据回溯、Schema 变更也都可能引入不一致。
d)成本:维护两套独立系统(TP + AP)以及中间的 ETL 链路,需要投入大量人力与机器资源。数据在两套系统中冗余存储,也抬高了存储成本。
由于以上局限,HTAP(Hybrid Transactional/Analytical Processing)这种既能满足 OLTP 又能满足 OLAP 的融合型数据库方案变得很有必要。
定义
2014 年,Gartner 给出了 HTAP 数据库的明确定义:HTAP 数据库需要同时支持 OLTP 与 OLAP 场景,基于创新的计算-存储架构,在同一份数据上保证事务的同时支持实时分析,省去费时的 ETL 过程。从定义看,它倾向于"一份数据、不同引擎",但工程实现往往百花齐放。
行业分析
业界头部公司针对 HTAP 都开发了独立解决方案,实现各不相同,但有一个共同特征:TP 与 AP 之间一定是隔离的——要么计算与存储完全隔离,要么共享数据但计算层隔离。隔离是趋势。
阿里
架构
PolarDB-X 2.0(前身为 DRDS)实现了在线高并发 OLTP 与 OLAP 海量数据分析的融合,即 HTAP。存储层扩展读节点,由流量接入层统一调度,对用户基本透明。

特性
| 维度 | 方案 | 说明 |
|---|---|---|
| 复杂性 | TP 和 AP 共用统一接入层 | TP 与 AP 入口统一,业务使用简单 |
| 隔离性 | 独立的 AP 节点(计算 + 存储) | TP 与 AP 完全隔离,不互相影响 |
| 实时性 | 实时 | 基本完全实时 |
| 一致性 | 最终一致(基于主从复制日志) | 基于 binlog 的异步复制,存在短暂延迟 |
| 扩展性 | 扩展读节点 | 理论上可以无限扩展 |
- 优点:实现复杂度可控。
- 缺点:业务层 TP/AP 对用户透明且完全隔离,但 AP 节点仍是行存,在压缩率、扫描速度等分析场景上存在性能短板。
PingCAP
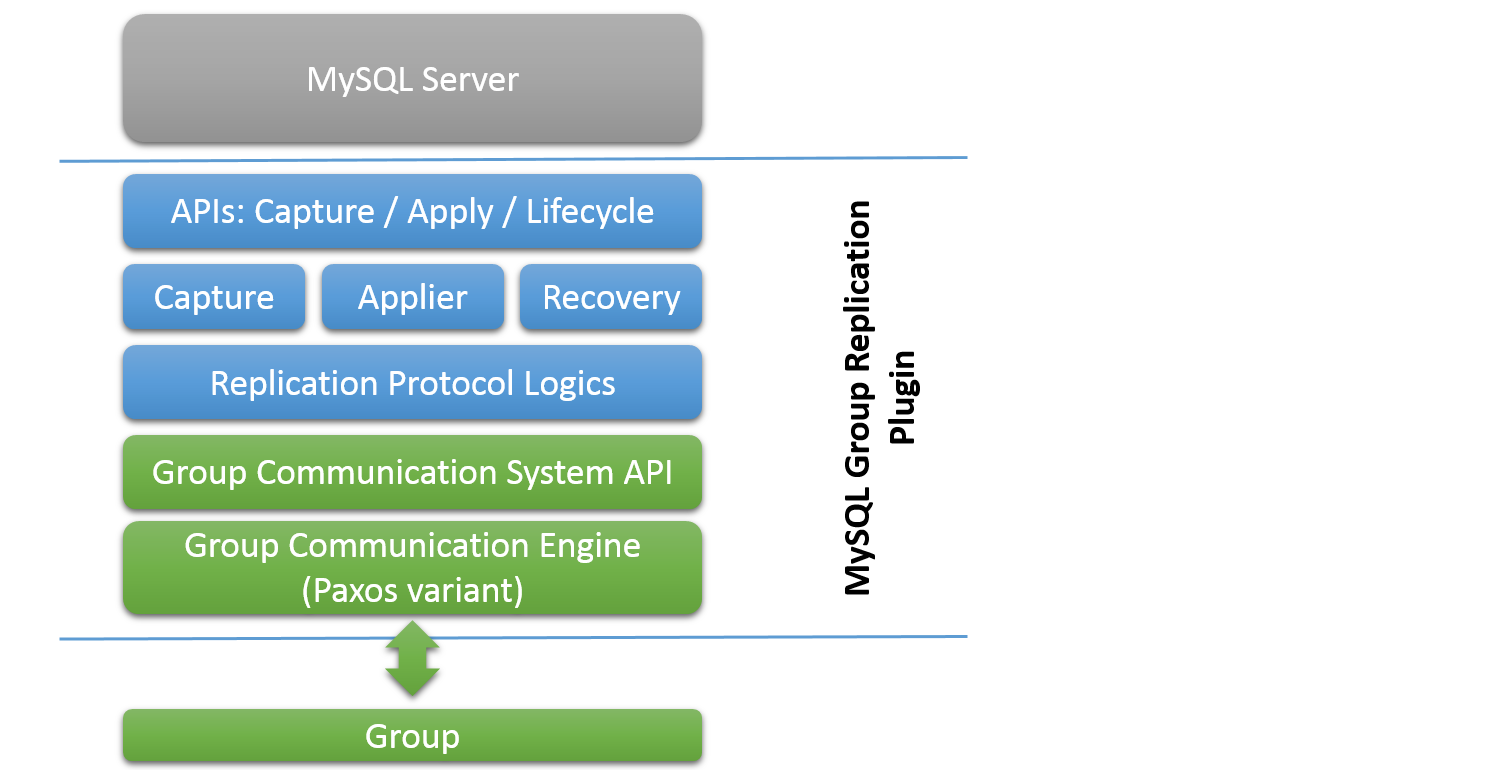
TiDB 4.0 开始支持 HTAP。最初通过 TiSpark(计算层、同一份数据两个引擎)直接读取 TiKV 数据,借助 Spark 增强 AP 端能力;但 TiKV 是为 TP 场景设计的存储层,对大批量数据的提取与分析能力有限。为此 TiDB 引入了新的 TiFlash 组件(列式存储层),做到存储与计算的完全隔离。
TiKV 底层基于 RocksDB,RocksDB 是 LSM-tree 结构,数据按 SSTable 组织,因此存在写放大问题。
架构:

| 维度 | 方案 | 说明 |
|---|---|---|
| 数据复制 | TiFlash 通过 Raft Learner 协议从 TiKV 同步 | 取消 ETL 过程,简化数据开发 |
| 复杂性 | TiSpark 与 TiDB 都可访问 TiFlash 数据 | TP 与 AP 入口统一,业务使用简单 |
| 隔离性 | 独立的 AP 节点(计算 + 存储) | TP 与 AP 完全隔离,不互相影响 |
| 实时性 | 实时 | 基本完全实时 |
| 一致性 | 默认快照隔离 | Raft Learner 为异步复制,可通过 read-index 等机制按需获得强一致读 |
| 扩展性 | TiSpark 与 TiFlash 均可水平扩展 | 理论上可以无限扩展 |
- 优点:TiFlash 采用列式存储,TiSpark 与 TiFlash 扩展性较好,分析性能优势明显。
- 缺点:实现复杂度较高。
总结
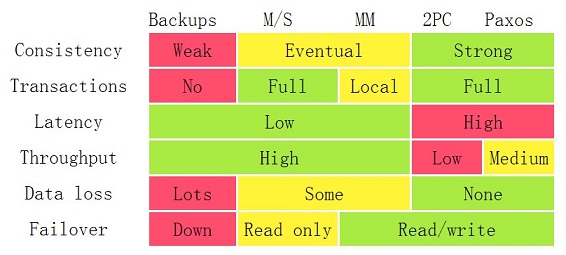
多节点复制、基于日志的方案是基础方案,业界现有方案大致分为:
- 自带主从复制的日志方案,以 MySQL 主从复制为代表;
- 在前者基础上引入自动选主的集群方案,以 Paxos/Raft 类实现为主;
- 自己搭建桥接通道,把 TP 系统数据通过 MQ 等通道导入异构系统,异构系统可以:
- 引入不同的计算层;
- 引入不同的存储层(例如把行存转换为列存)。
使用 RDBMS 的 AP 节点最好可以无限扩展,进阶方案有:
- 在线业务的只读(RO)从库;
- 离线业务的统计从库;
- 混合在线/离线的从库。
传统 OLAP 方案是从 RDBMS 转入大数据生态套件的方案。HTAP 的出现让数据库领域出现技术融合:上层应用可以使用统一的 portal,通过同一套 SQL 同时解决 OLTP 与 OLAP 问题,不再有跨异构存储层的体验割裂感。
读写分离造成的架构隔离,是工程上不可避免的——否则无法保证 OLTP 侧的 SLA。但在抽象层次上抹去这种差异正是 Hybrid 方案的核心价值,因此存储侧支持标准的 JDBC 协议成为必然,只有这样才能实现平滑升级。

HTAP 方案选型指南
选型决策矩阵
| 维度 | 传统 TP+ETL+AP | PolarDB-X HTAP | TiDB HTAP |
|---|---|---|---|
| 实时性要求 | T+1 可接受 | 需要实时 | 需要实时 |
| AP 查询复杂度 | 高(大表 JOIN、窗口函数) | 中(简单聚合、报表) | 高(复杂分析) |
| 团队技术栈 | 已有大数据团队 | MySQL 生态 | 愿意接受新技术栈 |
| 数据规模 | PB 级 | TB 级 | TB~PB 级 |
| 一致性要求 | 最终一致可接受 | 最终一致 | 默认快照,可按需强一致 |
关键设计原则
| 原则 | 含义 | 实践手段 |
|---|---|---|
| TP/AP 隔离 | TP 与 AP 的计算资源必须隔离,避免互相影响 | 独立节点、独立集群、资源配额 |
| 数据同步透明 | TP 到 AP 的同步对业务层透明 | 基于日志的自动复制(binlog/Raft) |
| 统一接入 | 业务层通过统一 SQL 接口访问 TP 与 AP | 统一 SQL 引擎、智能路由 |
| 存储适配 | TP 用行存优化点查,AP 用列存优化扫描 | 行列混合存储、异构存储引擎 |