
CI/CD 方法论
CI/CD 的重要性
Martin Fowler说过,“持续集成并不能消除Bug,而是让它们非常容易发现和改正。”
持续集成和持续交付作为敏捷开发的一种最佳实践,通过包括构建、部署、测试、发布流程的自动化,实现质量内建,让质量问题可以快速发现和消除,从而提升软件交付的质量和效率。
基本策略
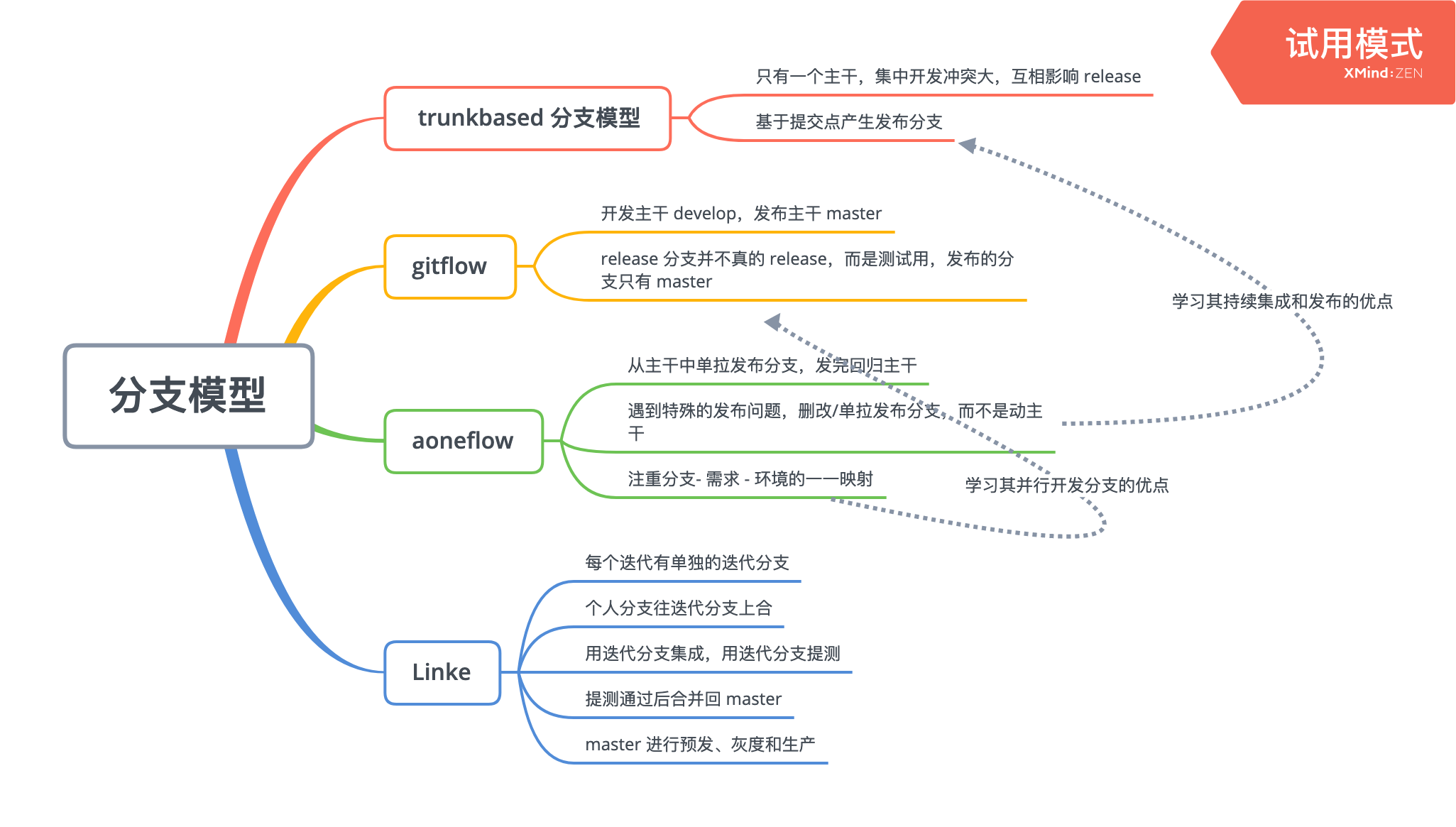
分支模型是CICD落地的源头,研发过程各角色间的协作方式以及研发过程内代码版本的流转方式都取决于分支模型。
首先划分环境。
划分环境后设计分支,注重开发和发布两个场景。
根据分支设计流水线,验证应该发生在全流水线里。
参考文献:
《在阿里,我们如何管理代码分支?》
《What is Trunk-Based Development?》
《提升团队的微服务落地能力》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-05-23
裸模型为什么像抽卡
大模型写代码有一种很危险的爽感:同一个问题,上一轮胡说八道,下一轮突然给出一段漂亮实现。失败的时候像差一点,成功的时候像中奖了。 这种体验很像抽卡。不是因为使用 AI 等同于赌博,而是因为裸模型的反馈结构具备几个相似特征:结果有波动,高分样本偶尔出现,用户很难提前判断下一轮是不是高分,于是自然产生“再试一次”的冲动。 把这种冲动看清楚,比单纯争论模型聪不聪明更重要。很多 AI coding 的燃尽感,不来自模型太弱,而来自人把自己的注意力押在一次又一次低可见度的重试上。工程工作被悄悄改造成了抽卡循环。 flowchart LR A[一次任务] --> B[裸模型采样] B --> C{输出质量} C -->|低分| D[补 prompt / 换模型 / 重试] C -->|高分| E[强奖励: 这次出货了] D --> B E --> F[提高下一轮期望] F --> D D --> G[隐藏成本: review / 归因 / 修复 / 焦虑] ...

2026-02-07
变更日志(Changelog)规范
什么是变更日志 变更日志(Changelog)是一个按时间顺序记录项目所有重要变更的文件。它帮助用户、开发者和利益相关者了解每个版本中发生了什么变化,包括新功能、Bug 修复、破坏性变更等。 为什么需要变更日志 用户友好:让用户快速了解新功能、修复的问题和需要注意的变更 版本追溯:帮助定位问题首次出现或修复的版本 团队协作:统一团队对变更的理解和沟通 发布管理:辅助版本发布流程和发布说明的撰写 与 Git Log 的区别 特性 变更日志 Git Log 目标受众 用户、开发者、利益相关者 开发者 内容粒度 功能级别的高级描述 每次提交的详细记录 可读性 高度结构化、易于阅读 技术性强、包含实现细节 维护方式 手动维护或自动化生成 自动记录所有提交 版本关联 按版本组织 按时间顺序 Git Log 记录所有的代码提交,包括内部重构、测试调整等;而变更日志只记录对用户有意义的变更。 Keep a Changelog 规范 Keep a Changelog 是目前最广泛采用的变更日志规范,由 Olivier Lacan 创建。 变更类型分类 Ke...

2026-05-23
AI 不会吞掉软件,只会吞掉入口
“AI 会吞掉所有软件”这个说法很有传播力,但技术上不够准确。更可能发生的事情是:软件本体继续存在,软件入口被 AI 重写。 计算器、数据库、编译器、PDF 库、浏览器、CAD、CI、权限系统、ERP 不太会因为 LLM 出现而消失。它们处理的是确定性状态、格式、权限、计算和副作用。LLM 不适合直接替代这些系统,却很适合成为它们上方的意图入口。 确定性系统不会消失 裸模型不是确定性程序。它可以写出计算器代码,但不应该代替计算器执行财务计算;它可以解释 PDF 结构,但不应该靠想象修改 PDF 二进制;它可以生成 SQL,但实际执行、回滚、审计和加锁的仍然是数据库。 这不是模型能力不够强时的临时现象,而是范式边界。真实软件世界需要可复现、可审计、可回滚、可授权。神经网络输出可以生成候选方案,却很难成为这些确定性承诺本身。 Claude Code Skills 的 PDF 示例很能说明问题。一个 PDF skill 会把操作流程写进 SKILL.md,再借助 pypdf、pdfplumber、脚本和参考资料处理文件。实际改 PDF 的不是模型“懂了 PDF”,而是模型调度了确定...
2018-05-09
Convention over Configuration over Programming
什么是 Convention over Configuration over Programming 在软件工程中,有一条重要的设计哲学层级: Convention over Configuration over Programming 约定优于配置,配置优于编程。 这条原则的核心思想是:能用约定解决的问题,就不要引入配置;能用配置解决的问题,就不要写代码。 它反映了软件设计中对复杂度管理的追求——越是高层次的抽象,使用成本越低,出错概率也越小。 三个层次的含义 Programming(编程) 编程是最灵活但成本最高的方式。开发者需要编写具体的代码逻辑来实现功能。每一行代码都是潜在的 bug 来源,都需要测试、维护和 review。编程适合处理那些真正需要定制化逻辑的场景。 Configuration(配置) 配置是介于约定和编程之间的中间层。通过外部化的配置文件(如 XML、YAML、properties 等),开发者可以在不修改代码的情况下改变程序行为。配置降低了修改成本,但引入了配置管理的复杂度——配置项越多,理解和维护系统的难度就越大。 Convention(约定) ...

2019-12-31
代码大全
第 1 章 欢迎进入软件构建的世界 第 2 章 用隐喻来更充分地理解软件开发 第 3 章 三思而后行:前期准备 第 4 章 关键的“构建决策” 第 5 章 软件构建中的设计 第 6 章 可以工作的类 第 7 章 高质量的子程序 第 8 章 防御式编程 第 9 章 伪代码编程过程 第 10 章 使用变量的一般事项 第 11 章 变量名的力量 第 12 章 基本数据类型 第 13 章 不常见的数据类型 第 14 章 组织直线型代码 第 15 章 使用条件语句 第 16 章 控制循环 第 17 章 不常见的控制结构 第 18 章 表驱动法 第 19 章 一般控制问题 第 20 章 软件质量概述 第 21 章 协同构建 第 22 章 开发者测试 第 23 章 调试 第 24 章 重构 第 25 章 代码调整策略 第 26 章 代码调整技术 第 27 章 程序规模对构建的影响 第 28 章 管理构建 第 29 章 集成 第 30 章 编程工具 第 31 章 布局与风格 第 32 章 自说明代码 第 33 章 个人性格 第 34 章 软件工艺的话题 第 35 章 何处有更多的信息
2024-09-25
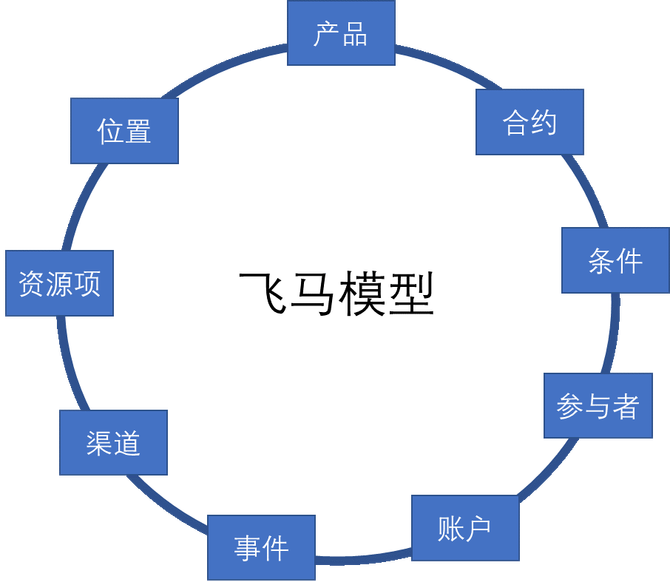
飞马模型
飞马模型来自 IBM 的 FSDM 模型 飞马模型可以覆盖银行、证券和保险业务场景,更加容易实现“全局最优”的金融信息互通、集成标准的建立。 飞马模型包括9类主题:产品、合约、条件、参与者、账户、事件、渠道、资源项、位置 。与FSDM的9大概念( 参与者、合约、条件、产品、地点/位置、分类、业务方向、事件、资源项)相比,飞马模型少了分类和业务方向,增加了账户和渠道两个主题,更加贴合金融业务特点。 账户的概念来源于会计核算中的会计账户。银行账户是客户在银行开立的存款账户、贷款账户、往来账户的总称。银行业务就是在账户体系基础上为个人和对公客户提供各种金融服务。账户体系定义所有的操作均以交易的形式发生,也就是信息模型中的事件。 渠道是银行为客户提供金融产品和服务的场所。渠道的作用在于触达客户、传递产品和服务、达成交易。对于传统金融机构,同时拥有线下渠道和线上渠道。而对于互联网金融来说,完全是线上渠道。这也决定了互联网金融的业务模式与传统金融机构相比存在较大的差异,渠道对于互联网金融来说意义更大。互联网渠道不仅能够完成触达客户、传递产品和服务、达成交易的基本作用,而且其所带来的全新优质...