MySQL 字符串和数字隐式转换的 pitfall
Data truncation: Truncated incorrect
不要小看 MySQL,它出 warning 就一定有错误。
不要滥用 MySQL 字符串到decimal,和 decimal 到 string 的转换。这样有时候 MySQL 不只是 warning。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2022-01-25
Spring 数据库的若干种小技巧
常用命令 12345678910111213141516171819202122232425262728# 登录服务器mysql -u username -pdev -h hostname databaseName# 如何重命名一个 dbmysqldump emp > emp.outmysql -e "CREATE DATABASE employees;"mysql employees < emp.outmysql -e "DROP DATABASE emp;"# mysqldump 的用法mysqldump -u username -h hostname -ppassword databaseName > /exportpath/dump.sql# 使用 brew 控制 mysqlbrew install mysqlbrew services restart mysql# 登录本机 root 用户mysql -uroot# 使用密码登录本机 root 用户mysql -uroot -p# 标准格式mysql -u US...
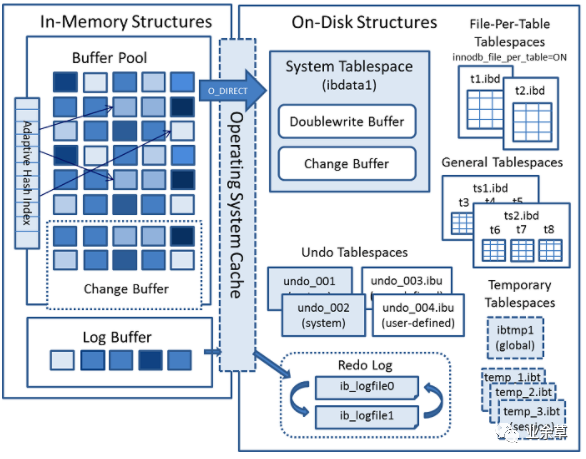
2021-03-28
MySQL 存储引擎 InnoDB 技术内幕
这本书的电子版的一个博客。 InnoDB.xmind 前言 MySQL 是处理海量数据(尤其 是OLTP 写入)时仍能获得最佳性能的最佳选择之一,它的 CPU 效率可能其他任何基于磁盘的关系型数据库所不能匹敌的-但它应该能够匹敌 Redis。 Think Different 而不是 Think Differently,这意味着要思考不同的东西,而不只是思考不同的方式。 不要相信网上的传言,去做测试,根据自己的实践做决定。很多伟大的作者写的伟大的书里面,关于性能的说法都来源于他们个人的随身电脑的直观测试。 change buffer 是 inert buffer 的升级版本。 MySQL 体系结构和存储引擎 定义数据库和实例 数据库:物理操作系统文件或其他形式文件类型的集合。 实例:操作系统后台进程(线程和一堆共享内存)。 存储引擎:基于表而不是基于库的,所以一个库可以有不同的表使用不同的存储引擎。 InnoDB 将数据存储在逻辑的表空间中,这个表空间就像黑盒一样。 存储引擎不一定需要事务。比如没有 ETL 的操作,单纯的查询操作不需要考虑并发控制问题,不需要产生一致性视图。...

2020-02-19
一次大表翻页实验
explain 的解释 https://www.cnblogs.com/butterfly100/archive/2018/01/15/8287569.html 假设慢查询是 100ms。 测试前准备一千万行数据 12345678910111213141516171819202122232425262728CREATE TABLE `tb_ins_pay_order` () ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_unicode_ci COMMENT='';drop database test_db;create database test_db;drop table tb_ins_pay_order;truncate table tb_ins_pay_order;drop procedure if exists doWhile;DELIMITER // tb_ins_pay_orderCREATE PROCEDURE doWhile()BEGI...

2018-05-29
JPA 的 id 生成策略
JPA 有一个@GeneratedValue注解,有一个strategy attribute,如 @GeneratedValue(strategy = GenerationType.IDENTITY)。 常见的可选策略主要有IDENTITY和SEQUENCE。 GenerationType.IDENTITY 要求底层有一个 integer 或者 bigint 类型的自增列( auto-incremented column)。自增列的赋值必须在插入操作之后发生,因为这个原因,Hibernate 无法进行各种优化(特别是 JDBC 的 batch 处理,一次 flush 操作会产生很多条insert 语句,分别执行)。如果事务回滚,自增列的值就会被丢弃。数据库在这个自增操作上有个高度优化的轻量级锁机制,性能非常棒。 MySQL 支持这种 id 生成策略, 使用 MySQL 应该尽量使用这个策略,即使它无法优化。 JPA 用它生成 id,会一条一条地插入新的 entity。 GenerationType.SEQUENCE 数据库有一个所谓的 sequence 对象,可以通过 selec...

2018-11-15
MySQL 中的引号
标准的 SQL 中只允许用单引号表达字符串类型。有些 SQL 方言允许使用双引号包裹字符串,如 MySQL,有些则不允许,如 Oracle。 反引号是专门用来表达 identifier 的。

2021-03-11
MySQL 的 MGR
MySQL 高可用架构的历史 MySQL 自带的主从复制机制,本身并不能实现自动高可用。 早期使用开源组件来搭 MySQL 集群的方案,使用 MMHA。当代 MySQL 官方自己主推的方案是 MySQL cluster。这些老的方案,优先保证MySQL服务的持续可用,在异常切换情况下,可能出现主机上部分数据未能及时同步到从库,造成主从切换后数据丢失。但是包括金融支付在内的一些业务,对于数据库服务既要求持续可用、也要求数据强一致(可以在性能上做出一些让步)。 因此,当代的 MySQL 官方提供了组复制(MySQL Group Replication)的方案,构建了新一代的 MySQL 高可用强一致服务。 Master-Slave(MS)架构高可用概述 MS架构高可用基础 高可用MySQL是依赖复制(Replication)技术实现的,复制解决的基本问题就是,让一台数据库服务器的数据同步到其它服务器上。MySQL数据库的复制有如下三个步骤。 在主库上把数据更改记录到二进制日志(Binary Log)中(这些记录被称为二进制日志事件)。 备库将主库上的日志复制到自己的中继日志(...





