推荐算法笔记
分类的话:
用户画像算法
用户画像算法、聚类算法
分类算法:
gbtd、随机森林 识别完了看哪个变量更重要。要有可解释性。
价格相关数据:体现在什么方面?一定要跟收入密切相关的。要对数据和业务的理解很重要。
分类项目:部分已知,有一部分训练集,用未知的和已知的做一个比较。打标签。寻找标签里最重要的因素。
gbtd(底层是很多决策树)。svm。dnn。可能解释性那么强。
决策树。xgbox。
输出是:分类的概率。
聚类项目:完全未知,从数据本身来发现特征。k-means。层次聚类。
输出是:不同类别的特征。
要理解商业逻辑。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-03-16
QMD:本地智能文档搜索引擎完全指南
QMD:本地智能文档搜索引擎完全指南 引言:你的知识库需要一把钥匙 作为程序员、写作者或知识工作者,我们每天都在产生大量的 Markdown 文档——技术笔记、会议记录、项目文档、博客草稿……这些文档散落在不同的文件夹中,随着时间推移,它们变成了"数字废墟":你知道某篇笔记一定存在,却怎么也找不到。 传统的文件搜索工具(如 Spotlight、grep)只能基于文件名或关键词匹配,无法理解语义。而云端笔记工具(如 Notion、Obsidian)虽然提供了搜索功能,却存在数据隐私和访问限制的问题。 QMD(Query Markup Documents) 正是为了解决这个痛点而生的——一个完全本地运行的智能文档搜索引擎,它结合了 BM25 全文检索、向量语义搜索和 LLM 重排序,让你能够用自然语言快速找到任何文档中的任何内容。 一、QMD 是什么 QMD 是一个开源的 CLI 工具 + 库,由 @tobi 开发,专为 Markdown 文档设计。它的核心特性包括: 特性 说明 完全本地 所有数据和模型都在本地运行,无需联网 混合搜索 BM2...
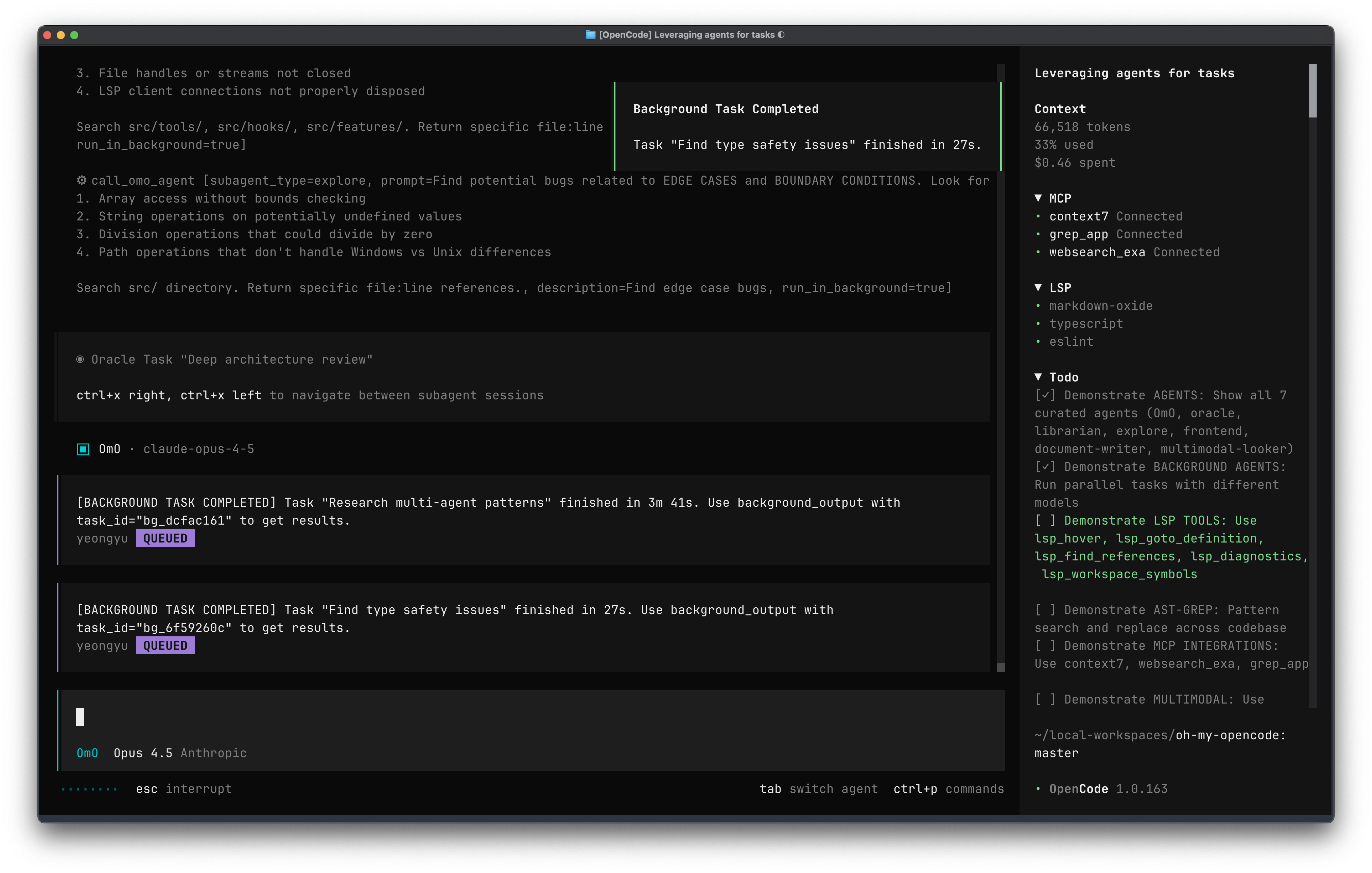
2026-03-18
告别 Vibe Coding:用 OmO 构建可靠的 AI 工程系统
引言:AI 编程的范式跃迁 过去一年,AI 编程工具从对话式代码生成器进化为能够自主执行复杂任务的智能代理。但真正的挑战不在于让 AI 写出代码,而在于如何让 AI 持续、可靠地完成工程任务。 Oh My OpenCode(简称 OmO)正是为了解决这一问题而生。它不是另一个聊天框,而是一套将 AI 从"对话工具"升级为"自动化工程系统"的编排框架。 OmO 的核心定位:工程化交付而非对话回答 从"会不会答"到"能不能交付" 传统 AI 编程工具的评判标准是"回答质量",而 OmO 的核心目标是**“工程交付”**。 OmO 的工作流程遵循"输入 Markdown 描述,输出可运行代码"的心智模型: 12341. 输入任务 → 2. 判断意图 → 3. 组织执行 → 4. 工程输出 (任务描述、 (Intent Gate (并行搜索、 (回到 build/ repo 上下文、 分清提问/修复/ 资料、执行...

2026-03-19
子 Agent 的本质:上下文隔离与专门化
"子 Agent"这个词在多 Agent 系统的讨论中频繁出现,却鲜有人把它说清楚。它是一个能力弱化的 Agent,类似一个 Agent 化的工具?还是一个拥有更小上下文的原始 Agent,像从主 Agent fork 出来的进程?还是一个在指挥体系里听从领导 Agent、但拥有更强资源和能力的 Agent? 这三种直觉都不完全准确。本文从 Anthropic、LangChain、Claude Code 等权威来源出发,厘清子 Agent 的真实本质,并探讨一个更深层的问题:"子 Agent"究竟是能力描述,还是关系描述? 三种直觉,三种误解 在深入定义之前,先把三种常见直觉逐一检验。 误解一:子 Agent 是能力弱化的 Agent 这种直觉来自于"子"字的字面含义——子集、子系统、子进程,往往意味着更小、更弱。但 LangChain 官方文档明确指出: “An interesting aspect of this approach is that sub-agents may have the exact sam...

2026-03-19
Coding Agent 架构祛魅:从 Claude Code 到 OpenCode 的真实实现
围绕 Coding Agent 的讨论,常见两种极端:将其神化为自主智能体,或将其贬为"不过是提示词工程"。两种判断都失之简单。本文从真实的架构出发,拆解 Claude Code、OpenCode 等工具的实现模式,厘清各自的设计取舍,以及那些被反复误解的核心问题。 一个循环统治一切 先说结论:所有 Coding Agent 的核心,都是一个 while(tool_use) 循环。 通过对 Claude Code 实际 API 流量的追踪分析,其核心逻辑可以用伪代码描述如下: 12345678while True: response = llm.call(context) if response.has_tool_call(): result = execute_tool(response.tool_call) context.append(result) else: # 没有工具调用 = 任务完成,等待用户输入 break 没有复杂的状态机,没有多 Agent 协调框架,没有专门的&...

2026-03-18
在智能体优先的世界中利用 Codex
原文作者:Ryan Lopopolo,OpenAI 技术人员。本文记录了 OpenAI 内部一个工程团队历时五个月、以"零人工编码"方式构建并交付真实软件产品的完整经验。 在过去五个月里,我们的团队一直在进行一项实验:构建并交付一款软件产品的内部 beta 版,其中没有一行代码是人工编写的。 该产品有内部日常活跃用户和外部 Alpha 测试者。它经历了交付、部署、故障和修复的整个过程。与众不同的是,每一行代码 — 从应用逻辑、测试、CI 配置、文档、可观察性到内部工具 — 全都是由 Codex 编写的。据估计,我们只用了手工编写代码所需的大约 1/10 的时间就完成了这项工作。 人类掌舵。智能体执行。 我们有意选择这一限制,以便构建必要的内容,从而将工程速度提升数个数量级。我们用了几周的时间来交付最终达到一百万行代码的项目。为此,我们需要了解,当软件工程团队的主要工作不再是编写代码,而是设计环境、明确意图和构建反馈回路,从而使 Codex 智能体能够可靠地工作时,会发生哪些变化。 这篇文章要说的是,在我们与智能体团队一起从零开始打造一款全新产品的过程中,所...
2024-11-01
大模型相关
世界线 大模型发展.xmind RNN的雏形可以追溯到90年代Jeffrey L.Elman的经典文章:Finding Structure in Time(1990) 2013年Google提出的Word2Vec可能是最为人熟知的Embedding技术之一 Encoder-Decoder架构来自论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation(2014) 注意力机制参考论文:Neural Machine Translation by Jointly Learning to Align and Translate(2014) LLM的技术发展和相互关系:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond(2023) Transformer出自一篇经典论文:Attention Is All You Need(2017) 国外模型的对比可以参考大...



