Linux hypervisor
hypervisor 可以被认为等于 virtual hardware。他们的出现,可以有效减少硬件服务器数量。

常见的 hypervisor 分成两类:
- 直接运行在硬件上的,基于内核的虚拟机。 OS as hypervisor。典型例子是 KVM。KVM 是被集成到 Linux 内核之中的完整虚拟化解决方案。
- 运行于另一个操作系统之上。典型的例子是 QEMU 和 WINE。
hypervisor的实现,总是要映射一些磁盘设备和网络设备的。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2026-05-23
页表:CPU 能读懂的翻译结构
上一篇把地址空间组织成一组 VMA,回答了“这个地址原则上是否属于进程,应该按什么规则处理”。这一篇切到另一层结构:页表。VMA 是内核策略的元数据,页表是 CPU 的 MMU 实际查询的硬件数据结构。两层一致时访问能继续,不一致时进入缺页异常。 核心问题可以压成一句话: VMA 决定一个地址原则上是否合法,页表决定一个虚拟页此刻能否被 CPU 翻译。 问题从哪里来 很多教材把页表画成“虚拟页号到物理页号的一张大表”。这张表足够回答“地址能不能翻译”,但解释不了几件实际发生的事。 一次 mmap 成功后,VMA 已经登记,可是第一次访问还会触发缺页异常,进程并没有出错。一段映射可能在 maps 里看得到、长期不被访问、/proc/<pid>/pagemap 报 present=0,进程也没有出错。一个共享文件页可以同时被多个进程访问,每个进程的页表里都有一份 PTE,但物理页只有一份。一个匿名页可能此刻在内存里、PTE present;过一会儿被 swap 出去,PTE 变成 swap 类型;再被访问时通过缺页恢复,PTE 又重新指向 PFN。 把这些现象统一起...
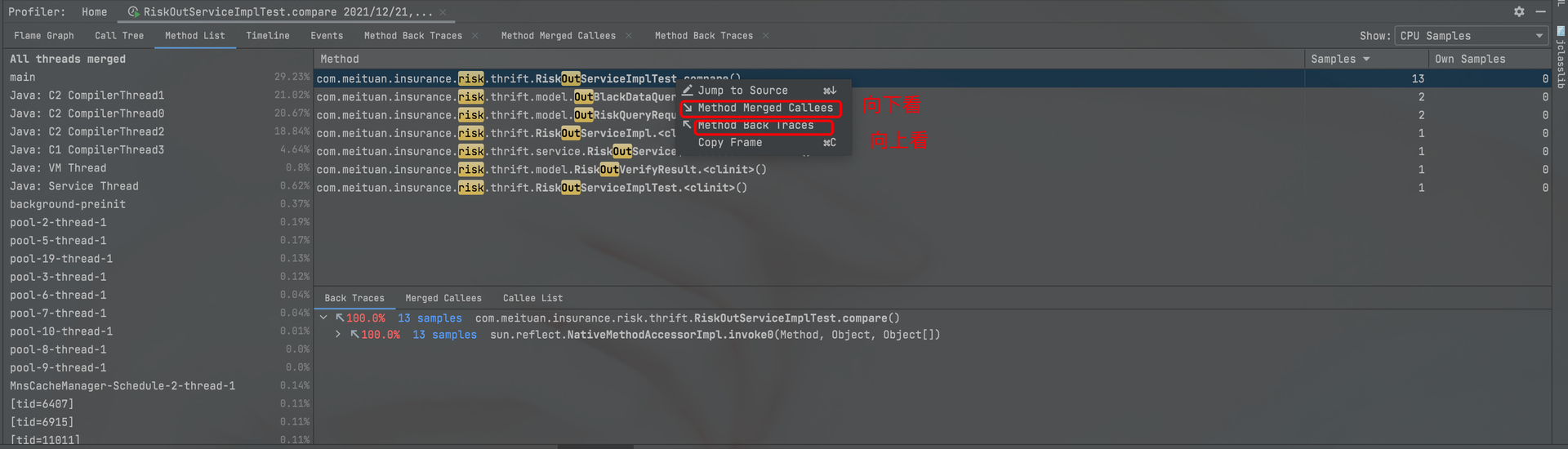
2019-09-02
Java 服务 OOM 排查全链路(Linux 内核 + JVM 工具链 + 问题分析)
Java 进程的 OOM 跨两层:Linux 内核的 OOM Killer 在物理内存或 cgroup limit 触及时 kill 进程,事后只能从 dmesg 还原;JVM 的 OutOfMemoryError 在堆/元空间/直接内存耗尽时抛异常,常带堆栈和 dump。两层工具栈不同:Linux 侧看 dmesg、cgroup、内核参数,JVM 侧看 jstat、jmap、jstack、arthas、JFR、gperftools。 一、Linux 层:OOM Killer 机制 Linux 内核有个 OOM (Out of Memory) Killer 的机制,可以在系统内存不足的时候,通过主动杀死一些进程来释放更多的内存空间。 很多时候,可以 ping 通一台服务器,但无法 ssh 上去,因为 sshd 被 OOM Killer 杀掉了。ping 能 ping 通,是因为处在内核态协议栈还能工作,发出回送报文。sshd 则因为是用户态进程,直接被干掉了。 OOM Killer 工作流程 OOM Killer 的完整工作流程如下: graph TD A[系统内存不足]...

2026-05-24
Huge Page:TLB 压力和页表开销
上一篇讲了 NUMA 如何让内存访问不再均匀。但即使在单 node 系统上,当工作集足够大时,另一类开销浮现:TLB miss 和页表自身的内存消耗。Huge page 通过增大映射粒度来同时缓解这两个问题。 核心问题可以压成一句话: huge page 用更大的映射粒度减少 TLB 和页表开销,但引入碎片、分配时机和回收复杂度作为代价。 问题从哪里来 标准页大小 4KB。一个 64GB 内存的机器有 1600 万个物理页。如果一个进程映射了 8GB 工作集,对应 200 万个 PTE。 TLB(Translation Lookaside Buffer)是 MMU 的地址翻译缓存。现代 CPU 的 L1 dTLB 通常只有 64-128 个条目,L2 sTLB 有 1024-2048 个条目。200 万个活跃页面对 2048 个 TLB 条目意味着 TLB 覆盖率不足 0.1%——绝大多数访问要走 page table walk。 page table walk 不是免费的。它需要 4-5 次内存访问(每级页表一次),即使有 page walk cache 辅助,在 TLB...

2026-05-24
OOM Killer:内核什么时候决定杀进程
上一篇讲了 memcg 如何把全局内存资源划分成层级预算。当预算用尽且回收无力时,最后一道防线是 OOM killer——通过终止进程来释放内存。这不是内存管理的常规路径,而是所有正常手段都失败后的兜底。 核心问题可以压成一句话: OOM killer 是多轮分配、回收、压缩、写回、swap 都无法满足请求后的兜底路径,不是内存管理的常规目标。 问题从哪里来 内存分配失败的处理有一个基本问题:内核不能简单地对调用者返回"分配失败"。很多内核代码路径不检查分配失败(GFP_KERNEL 分配假设不会失败),即使返回错误,用户空间进程通常也没有合理的 fallback 逻辑。 所以内核的策略是:在返回失败之前,尽可能通过各种手段释放内存。如果所有手段都用尽仍然无法满足分配请求,最后才走 OOM kill——选择一个进程杀掉以释放它占用的内存。 到达 OOM kill 之前的完整路径: 1234567891011121314__alloc_pages() 分配请求 → 检查 zone 水位线:有空闲页? → 成功返回 → 唤醒 kswapd 后台回收 →...

2026-05-23
反向映射:从物理页找回虚拟地址
上一篇把 folio 作为缓存与回收的管理单位。一旦讨论“回收”,立刻冒出一个问题:内核拿到一个准备回收的 folio,怎么知道哪些进程的页表还指着它?正向页表只能从虚拟地址走到物理页,反过来走不通。反向映射就是为这件事存在的。 核心问题可以压成一句话: 正向页表回答“这个地址翻译到哪一页”,反向映射回答“这一页被哪些地址空间映射”。 问题从哪里来 页表只解决一个方向:拿到一个虚拟地址,按 PGD→P4D→PUD→PMD→PTE 走下去,最终得到 PFN。这是 MMU 在用户态访问路径上需要的。 但内核在很多场景需要反方向:拿到一个物理页(或 folio),找到所有当前映射它的虚拟页和对应 PTE。典型场景包括: 回收一个 folio。释放前必须撤销所有指向它的 PTE,否则用户态访问会拿到已释放的物理页。 迁移一个 folio。把内容搬到新物理页之后,所有原指针都要改写到新 PFN。 COW 写入触发时。即使是 do_wp_page 的判断,也要确认有没有其他映射方共享同一物理页。 在大页拆分、NUMA balancing、kernel same-page mergin...

2026-05-23
缺页异常:一次访问如何进入内核
上一篇区分了 VMA 与页表:VMA 是地址区间策略,页表是 CPU 当前可消费的翻译记录。当 VMA 合法、PTE 却不满足这次访问时,硬件会把异常抛回内核,由内核的缺页处理路径接管。这一篇把这条路径走一遍。 核心问题可以压成一句话: page fault 不是错误的同义词,它是 Linux VM 延迟兑现承诺的主要入口。 问题从哪里来 “缺页异常”这个翻译容易引误解。它在英文里是 page fault,词义中性,本意只是“缺一次翻译”。大量正常程序每秒会产生上百次甚至数千次 page fault,进程跑得很好,没有任何错误。 mmap 完成后第一次访问、fork 后子进程写共享只读页、读一个尚未在 page cache 的文件、被回收过的匿名页再次访问、栈在合法范围内增长,都会触发 page fault。这些 fault 走完之后,程序继续执行下一条指令,用户态察觉不到任何异常。 只有少数情况会让 page fault 变成可见错误:访问完全不属于任何 VMA 的地址、对只读 VMA 写入、对不可执行区段取指令、内核回收阶段无法找到合适页面来满足需求。这些情况要么导致信...