
Java 并发编程笔记
juc.xmind 写在前面的话 并发编程最早的实践都在操作系统里。高层语言的并发模型都要基于底层系统对硬件抽象和并发的设计来设计和实现,不能超出操作系统允许的范围。所谓的高级抽象总体上是简化对 OS 底层机制的复杂调用。 并发与异步 本文聚焦并发(Concurrency),即多任务在同一时间段内的交替或并行执行,核心问题是资源共享、线程同步与协作。 **异步(Asynchronous)**是另一维度:调用方发起操作后不等结果返回即继续执行,通过回调、Future或事件机制获取结果。异步可通过单线程事件循环实现,也可依托多线程并发实现。 二者关系:并发关注"多任务如何执行与协调",异步关注"调用是否阻塞等待"。并发编程常涉及异步,但本文不展开异步编程模式(如响应式流、协程),相关内容请参阅《Java 线程池笔记》。 管程 理论和实践之间是有鸿沟的,要弥合这种鸿沟,通常需要我们去学习别人的实践。比如并发的标准设计思想来自于操作系统里的管程(monitor),我们应当学习管程,进而了解标准的并发模型-管理共享变量和线程(并发任务)间通信的基本...
常见故障整理
手写 sql if 条件的字段为空则不应该拼接条件,是一个很容易被忽略的编程错误。如果线上发生了这个问题,则可能导致数据同步出错。 极度危险的错误 元素内容必须由格式正确的字符数据或标记组成,这通常是因为>``<``>=``<=类的标签没有经过转义。 防止手写 sql 被注入 所有 condition 用()圈起来。单独在 condition 里面拼装。用 and 来连接这些 condition。 在最外围使用随机化的()来包裹整个 where 的条件,防止有人猜到()的层次。 mybatis 的替换难点 #{} 是预编译处理,${} 是直接替换。直接替换会有 sql 注入的风险。 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192939495969798991...
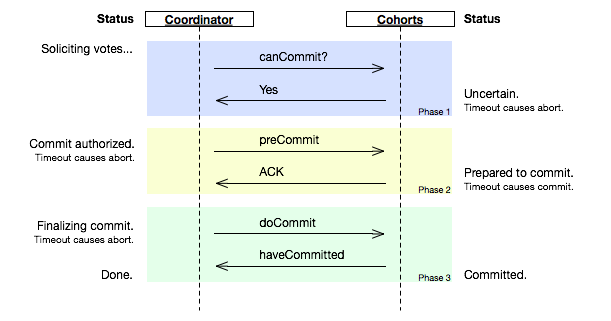
分布式事务
问题定义 对经典的电商场景而言:下单是个插入操作,扣减金额和库存是个更新操作,操作的模型不同,如果进行分布式的服务拆分,则可能无法在一个本地事务里操作几个模型,涉及跨库事务。 CAP 定义 根据 Eric Brewer 提出的 CAP 理论: Consistency:All Nodes see the same data at the same time。所有节点看到同一份最新数据(线性一致性)。 Availability:Reads and writes always succeed。非故障节点必须在合理时间内响应。 Partition tolerance:System continues to operate despite arbitrary message loss or failure of part of the system。网络分区时系统继续运行。 由此诞生三种设计约束和取舍方向: CA:放弃P,仅适用于单点系统,非分布式,如 MySQL主从同步。 AP:放弃强一致性,保证高可用。Cassandra,DynamoDB。Gossip协议可实现最终一致性。 CP...

系统设计
System Design 总结 面试前你需要了解的16个系统设计知识 《搞定系统设计:面试敲开大厂的门》 从 0 到 100 万用户的扩展 数据库的选择 先把服务器里计算和存储的服务器分离开来。 在如下情况下,可以考虑 NoSQL: 低延迟。 非结构化非关系型。 只需要序列化格式-或者对序列化格式友好。 需要存储海量数据。 《你到底用 NoSQL 来做什么?》 scale up vs scale out 纵向扩展的缺点: 有硬性限制。 没有冗余。 横向扩展对大型应用更合适。 负载均衡器 failover 基于负载均衡器就够了,有了 LB 我们才能装多台服务器。 数据库复制 从换主很容易丢失数据,先要恢复脚本才能实现对数据的合法写和读。 缓存 读写模式 我们常用的缓存策略叫 Cache-Aside Cache,完整介绍在《Caching Strategies and How to Choose the Right One》。 如果是应用自己加在缓存,就是 cache aside;如果缓存自己带有 load 方法-比如 guava 的 loader 实现,则意味着 ...

《编程之美》
序言 下水道井盖为什么是圆的 “下水道井盖是圆的,因为圆形不会掉进井口,而且圆形具有均匀分布压力的优势。” 一个屋子有一个门(门是关闭的)和3盏电灯。屋外有3个开关,分别与这3盏灯相连。你可以随意操纵这些开关,可一旦你将门打开,就不能变换开关了。确定每个开关具体管哪盏灯? 答:将一盏灯开一段时间,再关掉,在剩余2盏灯里随机开一盏,进屋去看,发热的灯对应第一个碰的开关,亮着的灯对应开关开着的开关,灭的灯对应没碰过的开关。 游戏之乐 如何写一个程序让 cpu 占用率保持在 50%? 不要用 if-else 来解决,要把比例转成不同的 worktime。 解法的精确与否其实取决于“多久时间内测度一次已占用的时间”和“睡眠”两类 api 的精度。 基本思路: 先计算一下某个周期内的目标时间: 假设我们使用 1s 为一个完整周期,则这个周期的 50% 为0.5s。 我们就用当前时间 + 0.5s 得到一个真正目标时间,比如当前时间在 15:06秒,目标时间就是15:06.5。如果有毫秒偏差,以此类推。 找一个无限 while 循环,内部只做两件事: 进行一个稍微复杂的数学计算,如开平...

Grokking the System Design
设计一个电梯系统 项目链接 myElevator 思路 1. 这道题考察候选人的什么知识? 面试官不是真的想让候选人造一台电梯,而是想通过这个问题评估候选人的综合能力,主要包括: 需求分析与沟通能力:这是最重要的一点。一个优秀的工程师在动手前,会先问问题,明确需求和边界。直接埋头开始写代码的候选人通常会失分。 面向对象设计 (OOD) 能力:这个问题是考察OOD的绝佳场景。如何将现实世界的实体(电梯、楼层、按钮、乘客)抽象成清晰、低耦合的对象和类? 算法与数据结构:电梯调度策略是整个系统的核心,这直接考察候选人的算法设计能力。如何选择合适的数据结构来存储和处理请求,以实现高效的调度? 状态机建模能力:电梯的运行本身就是一个状态机(静止、上升、下降、开门、关门等)。能否清晰地定义这些状态以及它们之间的转换条件,是衡量逻辑思维严谨性的关键。 并发与同步问题:多部电梯、多个乘客请求,这些都是并发场景。候选人是否能意识到可能存在的竞态条件(Race Condition)和资源同步问题? 系统扩展性 (Scalability):设计是只针对一台电梯,还是一个拥有多台电梯的系统?如何将单...

HTTP 请求体只读一次之谜——Go 与 Java 的应对之道
在后端开发中,日志记录、签名验证、请求重放等场景都需要在中间件(Middleware/Filter)中读取 HTTP 请求体(Request Body)。然而,请求体在被读取一次后便无法再次获取——后续处理程序收到的是一个空的 Body,导致逻辑中断。 这并非 Bug,而是网络 I/O 流处理的基本特性。本文将从操作系统内核的 Socket 缓冲区出发,剖析这一现象的根源,并详细对比 Go 和 Java 在"可重复读 Body"问题上的解决方案及其背后截然不同的设计哲学。 第一部分:问题的根源——流的"阅后即焚"本质 为什么 HTTP 请求体默认只能读取一次? 请求体本质上是一个从网络连接中实时到达的字节流,而非一块已经完整存放在内存或磁盘上的数据块。理解这一点是理解"只读一次"问题的关键。 操作系统层面:Socket 读取缓冲区 当客户端发送 HTTP 请求时,数据通过 TCP 连接到达服务器的网络套接字(Socket)。操作系统内核维护着一个接收缓冲区(Receive Buffer),TCP 数据包到达后被暂存在这里...

Java 字符编码与 Unicode 完全指南——从 BMP 到增补平面,从代码单元到字形簇
“一个 char 就是一个字符”——这个直觉在 Java 中是错误的。一个 emoji 👨👩👧👦 在 Java 中占 11 个 char,但在用户眼中只是一个字符。本文将从 Unicode 的基础概念出发,深入剖析 Java 的字符编码机制,揭示 char、码点、代码单元、字形簇之间的层次关系。 Part 1: Unicode 基础——字符集的大一统 从 ASCII 到 Unicode 的演进 编码 年份 字符数 位宽 覆盖范围 ASCII 1963 128 7 位 英文字母、数字、控制字符 ISO 8859-1 1987 256 8 位 西欧语言 GB2312 1980 6,763 汉字 双字节 简体中文 GBK 1995 21,886 汉字 双字节 简繁中文 Shift_JIS 1982 ~7,000 变长 日文 Unicode 1.0 1991 7,161 16 位(最初设想) 多语言 Unicode 16.0 2024 154,998 21 位(实际) 全球所有文字 + emoji Unicode 之前的世界是编...

MESI 协议与 Java 并发可见性——从硬件到 JMM
为什么 volatile 能保证可见性?为什么 synchronized 既保证原子性又保证可见性?答案藏在 CPU 缓存一致性协议和内存屏障中。本文将从硬件层面的 MESI 协议出发,逐步上升到 Java 内存模型(JMM),揭示并发可见性问题的完整因果链。 Part 1: CPU 缓存架构 为什么需要 CPU 缓存 现代 CPU 的运算速度远超内存访问速度,两者之间存在巨大的速度鸿沟: 操作 延迟 相对速度 CPU 寄存器访问 ~0.3 ns 1x L1 Cache 访问 ~1 ns 3x L2 Cache 访问 ~4 ns 13x L3 Cache 访问 ~12 ns 40x 主内存访问 ~100 ns 333x 如果 CPU 每次都直接访问主内存,大部分时间都在等待数据。缓存利用了时间局部性和空间局部性,将最近和附近的数据保存在更快的存储中。 多级缓存架构 12345678910111213141516171819┌──────────────────────────────────────────────────────┐│ ...

Java 集合框架完全指南
Java 集合框架完全指南 本文系统性地介绍 Java 集合框架的核心概念、实现原理和设计模式。内容涵盖集合框架体系结构、列表与队列机制、哈希表家族的扩缩容策略、缓存淘汰算法实现以及系统级扩缩容设计。通过深入分析源码实现和性能特征,帮助理解各集合类的适用场景和最佳实践。 第一章:全景导图 文章结构 mindmap root((Java集合框架完全指南)) 集合框架体系 Iterable接口 Collection体系 Map体系 Sorted接口 Navigable接口 抽象类层次 列表与队列 ArrayList扩缩容 队列六操作 PriorityQueue DelayQueue Deque体系 哈希表家族 HashMap结构 扩容机制 扰动函数 树化反树化 ConcurrentHashMap LinkedHashMap EnumSet/Ma...





