
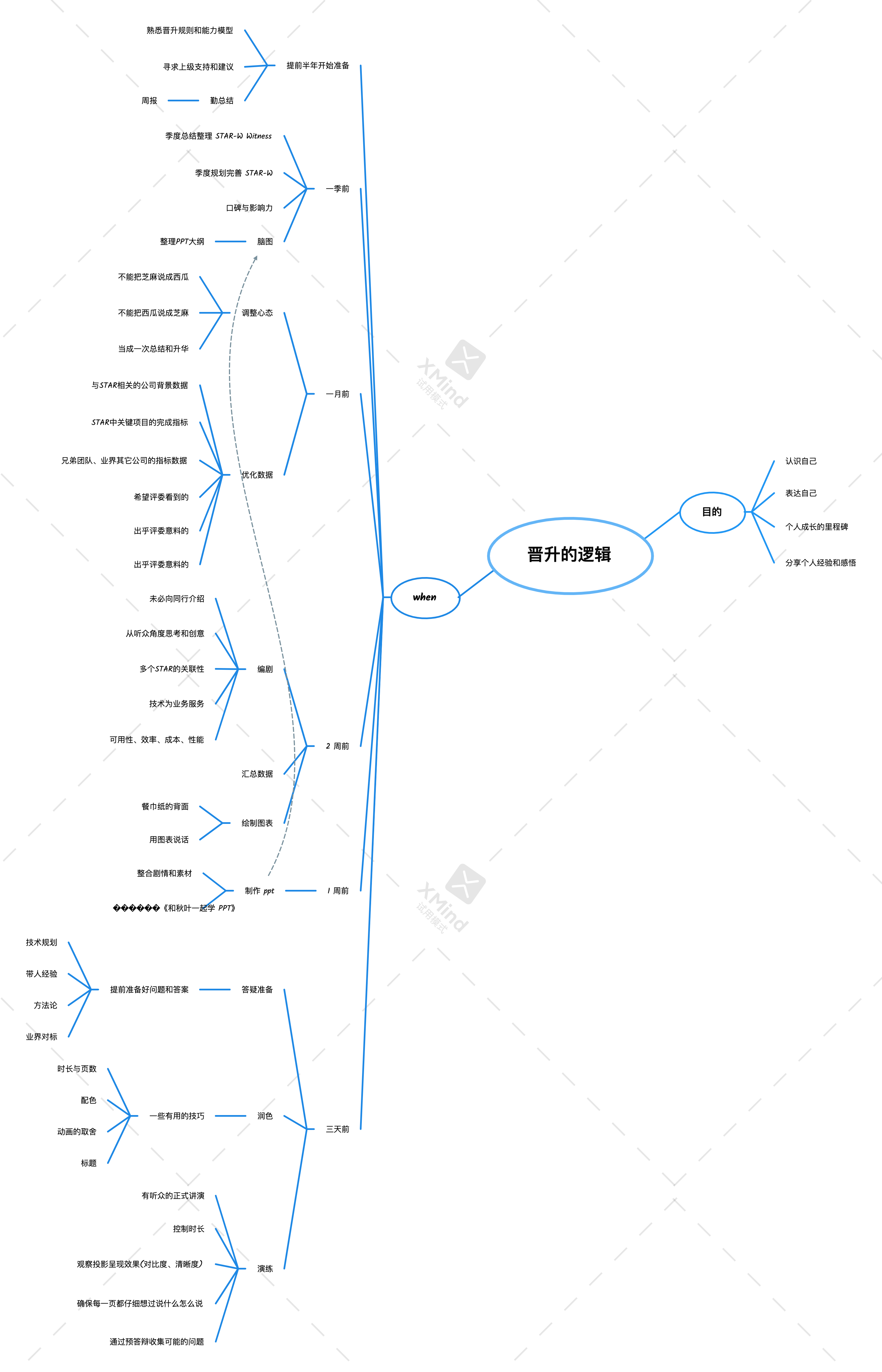
面向职场编程
学习的衰减和回归 读了 100 分的书籍。 只能学会 80 分的知识。 做出 60 分的软件。 参加多人协同的项目,最后只能拿到 40 分的产出。 去参加晋升评审的时候,因为讲得不够好,只能得到 20 分的输出效果 提升自己的职场收获的法门有:在 1 上加大努力,让 5 也跟随 1 增长;练习 soft skill,让 4 和 5 的衰减变少。 不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。没有输入,谈不上学习;没有复制,谈不上学习;没有创造与运用,谈不上学习。学习就好像爬喜马拉雅山,你从北坡上山,要从南坡下山,你体会的山才完整,没有体会过知识的接受者视角和使用者视角的经历的是不完整的。 上士闻道,勤而行之;中士闻道,若存若亡;下士闻道,大笑之。 不笑不足以为道。 故建言有之:明道若昧;进道若退;夷道若颣;上德若谷,大白若辱,广德若不足,建德若偷,质真若渝;大方无隅;大器晚成;大音希声;大象无形。 道隐无名。 夫唯道,善始且善成。 从信仰者成为践行者。 职位的 max 和 min 不要让评委进入 min 模式,那样评委很容易成为你的挑战者。不要让评委进入攻击者模式。...

贝索斯在普林斯顿大学毕业典礼上的演讲-We are What We Choose
原文链接:《2010 Baccalaureate Remarks》 小时候,我经常到外公外婆家的德州牧场过暑假,帮忙修理风车、帮牛打疫苗、做些杂活。每天下午,我们还会在一起看电视连续剧。 外公和外婆是我挚爱、崇拜的两位老人。他们都是露营拖车俱乐部的会员,这是一群由Airstream露营车车主组成的车队,车队成员定期结伴在美国、加拿大到处旅游。我们每隔几年参加一趟,直接把路用车挂在外公的车子后面,就上路了。三百多辆拖车连成一线,非常壮观。 其中一次,大约在我10岁时。一路上,我都在车子的后座上随意打滚。外公在开车,外婆坐在他旁边,不停地抽着烟。而我很讨厌香烟的味道。 那个年纪的我,只有有机会就喜欢算来算去,做些简单的加减乘除练习。比如,估算汽油的行驶里程数,或者计算买东西花了多少钱。 抽一口烟,短命两分钟 当年,有个警告抽烟的广告,我已经忘了细节,只记得大意是说,你只要抽一口烟,就会减少几分钟的寿命,好像是两分钟吧。那天,我决定帮外婆算算看:她每天抽多少根烟、每根烟要抽几口等等。 最后,我很满意地算出来一个差不多的数字,把头伸到车子前座,拍了拍外婆的肩膀,很得意地说:“如果抽一口烟...

如何成为一名优秀的架构师
成为一个架构师:为了这一刻,你准备了多久? 架构师的关注点:顶层设计、长期视角。 寿命:数据 > 代码(特指业务逻辑)> 技术(特指业务逻辑的载体) 不是传道受业,而是观点分享。 架构师的几种 profile:有架构能力、以架构为生也是一种架构师。 长期战略:对于任何一家公司,架构设计一定是必要的,而且需要自行解决。架构师的职责是保证组织拥有正确的设计,控制复杂度。 架构师的关键特质: 目标正确:限制条件和目标价值产生理解偏差。是架构师最常见的问题。 能力满足:为组织带来更好的外部适应性。 持续减熵:好架构等于发现、规划和演化。 思考深度和实战经验最重要:这是任何的书本都不能带给我们的。包容、求真、良知、勇气。 有没有德?考虑组织长期利益(基于良知做判断)。 有没有勇气?承担责任,决定命运。 有没有眼光?是否擅于思考? 独立、理性、有深度的思考。长期感召力,来自于良知、成功、经验和勇气。 从复盘中学习。 郭东白.pdf

项目管理
比起重要紧急排序法,MoSCow优先级排序法更适用 FORM:https://www.jianshu.com/p/f165dff094bb Must have:必须有。如果不包含,则产品不可行。Must Have的功能,通常就是最小可行产品(MVP)的功能。比如微信的聊天信息、通讯录、朋友圈。 Should have: 应该有。这些功能很重要,但不是必需的。虽然’应该有’的要求与’必须有’一样重要,但它们通常可以用另一种方式来代替,去满足客户要求。 Could have: 可以有。 这些要求是客户期望的,但不是必需的。可以提高用户体验,或提高客户满意度。如果时间充足,资源允许,通常会包括这些功能。但如果交货时间紧张,通常现阶段不会做,会挪到下一阶段做。 Won’t have(nice to have): 这次不会有。 最不重要,最低回报项目,或在当下是不适合的要求。不会被计划到当前交货计划中。 “不会有”会被要求删除,或重新考虑。 总的来说,”这次不会有”在项目讨论阶段,就会被去除。所有要求看上去都很重要,但是如果交货时间紧,“”可以有”将第一批被删除,”应该...
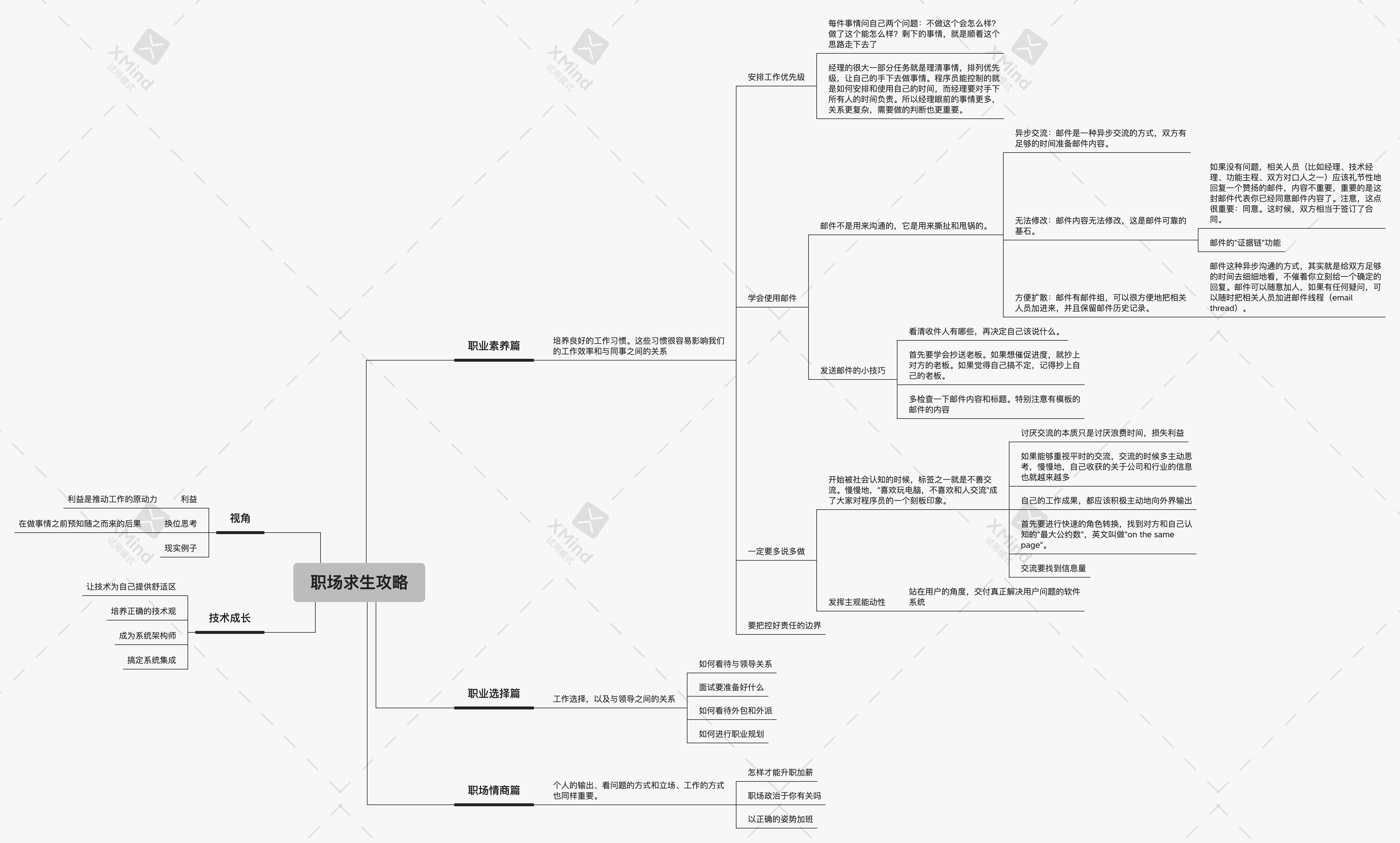
职场求生攻略
职场求生攻略.xmind

Java中的条件编译
一个流传已久的传说 在中文 Java 圈子里有这样一段传说:Google(或某家硅谷大厂)有一种「Java 条件编译」技术,可以在同一份源码里写「测试开关打开时才走的代码」,非生产流水线编译时整段代码都在,可以照常调试;上了生产、关掉开关,被 if 包围的那段 Java 代码就会被编译器当成死代码,从字节码里直接抹掉,线上绝对跑不到。 这段传说混杂了三个独立的问题: Java 是否真的存在「if 块在生产编译时从字节码消失」这种机制? 这是 Google 独有的私货,还是标准 Java 的能力? 如果代码真的被编译器去除,那调试还能怎么做? 回答它们需要三种证据:JLS §14.21、§13.4.9、§15.28 的规范条文给出语言契约;一组可复现的 javap 字节码实验给出实证;feature switch 工业谱系(javac 死代码消除、BuildConfig.DEBUG + R8、Manifold 预处理器、AspectJ 类加载织入、OpenFeature 运行时开关、HotSpot C2 运行时死分支折叠)给出工程参照系。 文中代码示例基准 Java 8,字节...

《战争论》
“数量上的优势不论在战术上还是战略上都是最普遍的致胜因素。 战略上最重要而又最简单的准则是集中兵力。 人们必须承认,数量上的优势是决定一次战斗结果的最重要的因素,只不过这种优势必须足以抵消其他同时起作用的条件。从这里得出一个直接的结论:必须在决定性的地点把尽可能多的军队投入战斗。 在一般条件下进行的大小战斗中,不论其他方面的条件如何不利,只要有显著的数量上的优势,而且无需超过一倍,就足以取得胜利了。 如果我们不抱偏见地研究现代战史,那就必须承认,数量上的优势越来越起着决定性的作用。因此,在决定性的战斗中尽可能多地集中兵力这个原则,在现在必须提到过去更高的地位。 数量上的优势应该看作是基本原则,不论在什么地方都是应该首先和尽量争取的。 一切用于某一战略目的的现有兵力应该同时使用,而且越是把一切兵力集中用于一切行动和一个时刻就越好。” 《孙子-谋攻篇》:故用兵之法,十则围之,五则攻之,倍则分之,敌则能战之,少则能逃之,不若则能避之。
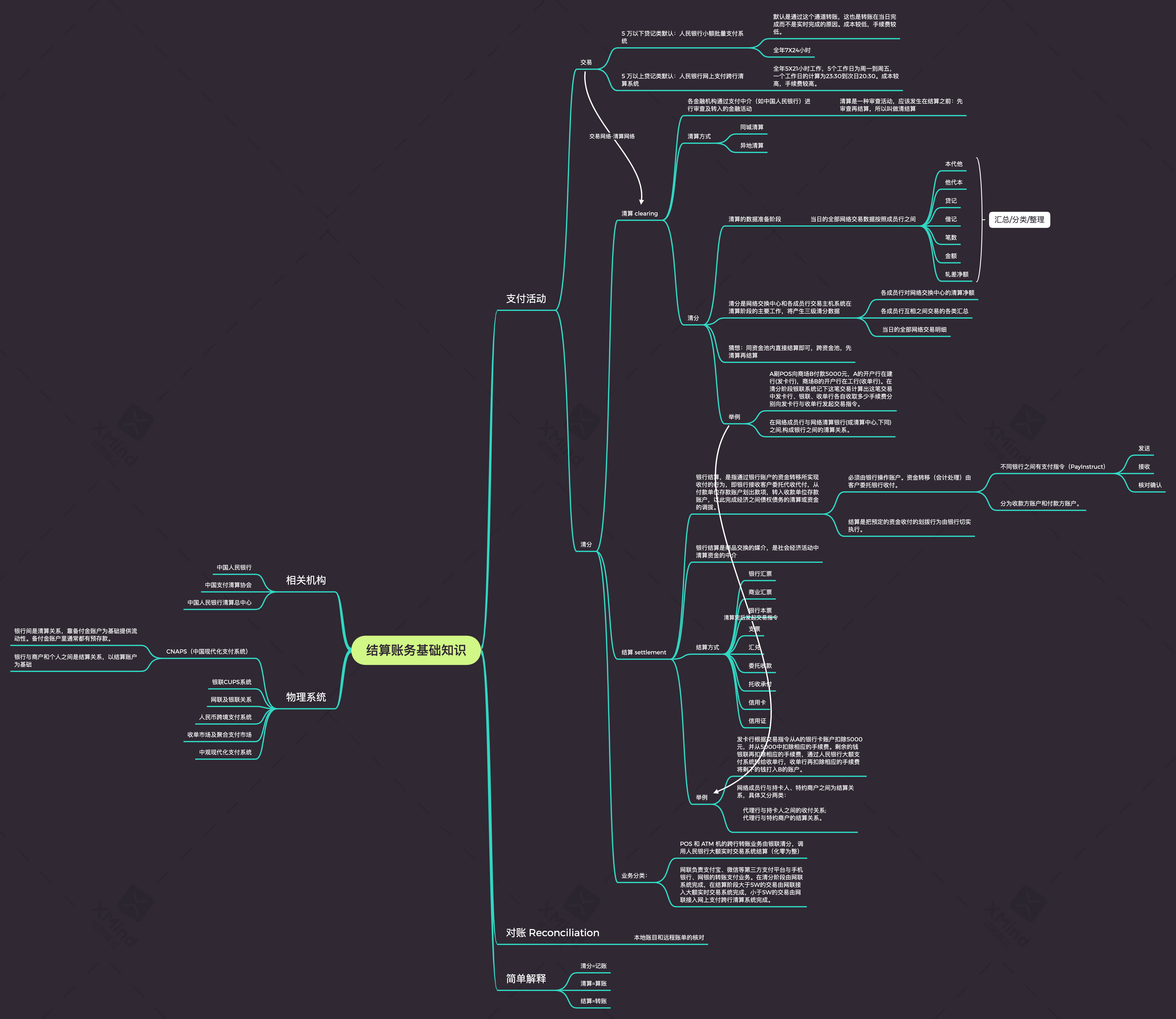
清分知识汇总
结算账务基础知识.xmind 本文来自于: 《中国央行支付清算系统概述(上)》 《清分、结算、清算、对账》 《银联清算业务基础知识介绍 VIP》 我国清结算架构 我国银行的(倒置)清结算架构图: 清结算属于底层架构,清算是发生在银行之间的。 在整个体系里,第三方支付公司扮演的角色是收单机构,银行提供资金服务能力。 两个例子 从以上示意图中可知,参与支付清结算的市场主体有消费者、商户、商业银行、中国人民银行、收单机构(第三方支付公司)。上面介绍的内容相对比较抽象,我们先用现实生活中一个消费场景来分析下支付活动到底发生了什么。 比如,消费者A在沃尔玛买了300元的东西,A持招商银行借记卡在建设银行铺设的线下POS机上进行付款,则整个过程分为支付、清算、结算三步骤。 A在建行POS机上刷卡时,建行POS会判断下发卡行(为招行),并询问招行A所持卡内余额是否大于300元,如果大于,则招行会告诉建行可以消费,此时A需要输入支付pw,建行将支付信息传送至招行,招行会实时借记A300元,并告知建行POS扣款成功,此时支付完成,消费者得到商品,债权债务关系变更为招行与建行之间的债权债...
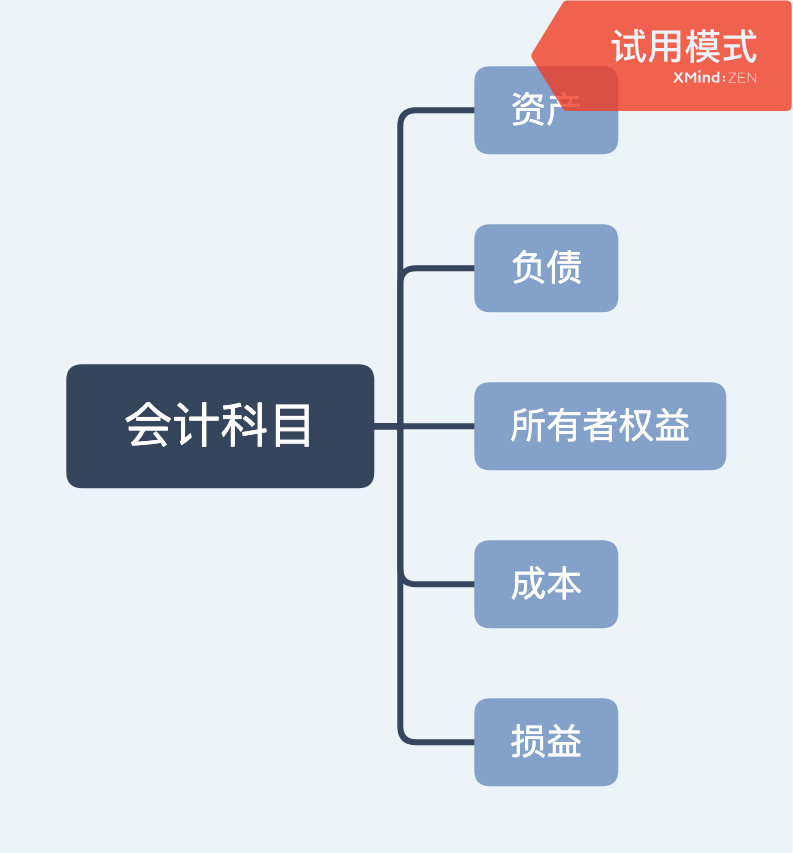
财务知识
会计科目 会计科目.xmind 财务报表 三大财务报表.xmind

《架构师修炼之道》
刻戒于碑,铸法于鼎 软件特性、质量属性。 将两个元素以某种方式连接在一起,就形成了结构。 module component-connector 就是我们经常讲的系统交叉点 allocation 就涉及到我们的部署设计 每一本书都会讲到利益相关者,也就是 stakeholder。 主动撰写设计决策,承担设计职责。 软件之所以叫软件,是因为它灵活而易于变动。架构是软件里硬的部分,为变动提供了章法,也制造了约束-否则我们不用经常“对架构产生冲击”,而需要打破架构。 设计原则: 以人为本(能落地能产生价值的架构才是真的好架构) 推迟决策 善于借鉴 化虚为实 推迟决策不是推迟大的设计决策,要推迟的是细枝末节的决策。不要陷入舍本逐末的优化中,导致项目无法受控。 忽视前人的设计,是最低效的设计方法之一。所以寻找架构风格是很重要的。 设计思维模式: 理解:换位思考 探索:尝试各种结构组合,找到最能提升目标质量属性的那种组合。-大多数情况下,是我们手头最简单最现成的解决方案。 展示:用图、表、模型、原型来展示,探讨。原型应该尽量具有交互性,可以直接和客户评审。 评估:评估到底我们要做什么东西...




