副本复制算法与架构——PacificA、Elasticsearch、Kafka、Pulsar 全面对比
本文将深入剖析 PacificA、Elasticsearch、Kafka、Pulsar 四大分布式系统的副本复制机制,揭示它们在一致性、可用性和性能之间的精妙权衡。这些系统虽然都通过副本复制来保证数据可靠性和高可用性,但在具体的实现策略上各有特色,反映了不同的设计哲学和适用场景。 引言:为什么需要副本复制 数据可靠性与高可用性 在分布式系统中,硬件故障是常态而非例外。Google 的统计数据显示,一个拥有 10,000 台服务器的数据中心,每天平均会有 2-3 台服务器发生故障。如果数据只存储在一台机器上,那么这台机器的故障就意味着数据的永久丢失。 副本复制(Replication) 是解决这个问题的核心手段:将数据复制到多台机器上,即使部分机器故障,数据仍然可用。 CAP 定理的实际影响 CAP 定理告诉我们,在网络分区(Partition)发生时,分布式系统只能在**一致性(Consistency)和可用性(Availability)**之间二选一: 选择 含义 代表系统 CP 网络分区时拒绝服务,保证一致性 ZooKeeper、etcd、HBase AP...

原码·反码·补码——从环形数轴到 CPU 减法器
CPU 只有加法器,没有减法器。为了让 A - B 直接变成 A + (-B),人们发明了补码;原码、反码只是推导脚手架。本文将从最基础的原码出发,经过反码的过渡,最终抵达补码的本质——环形数轴上的模运算,并深入探讨补码在不同编程语言中的体现。 Part 1: 原码——人类的直觉 符号位 + 绝对值 原码是最直观的有符号整数表示方法:最高位表示符号(0 正 1 负),其余位表示绝对值。 以 8 位为例: 十进制 原码 说明 +5 0000 0101 符号位 0(正),绝对值 5 -5 1000 0101 符号位 1(负),绝对值 5 +0 0000 0000 正零 -0 1000 0000 负零 +127 0111 1111 最大正数 -127 1111 1111 最小负数 表示范围:-127 到 +127,共 255 个不同的值(因为 +0 和 -0 占了两个编码)。 原码的致命缺陷 缺陷一:双零问题 +0(0000 0000)和 -0(1000 0000)是两个不同的编码,但它们表示的是同一个数学值 0。这给硬件判断"结果是...
数据库写入的潜规则——合并树与 MPP 架构深度剖析
许多开发者在使用 ClickHouse、HBase、Elasticsearch 等现代数据系统时,都会遇到"不建议高频写入"的限制。这一限制常被归因于"列式存储",但这是一个常见的误解。 高频写入受限的根本原因在于数据库的存储引擎架构。本文将深入剖析四大主流架构——LSM-Tree、ClickHouse MergeTree、MPP 和 B-Tree——分析它们各自的写入机制、性能权衡,以及它们"偏爱"批量写入的底层原因。 Part 1: 磁盘 I/O 基础——理解一切的前提 深入存储引擎之前,有必要先理解磁盘 I/O 的基本特性,因为所有存储引擎的设计都是围绕磁盘特性做出的权衡。 随机写 vs 顺序写 指标 HDD(机械硬盘) SSD(固态硬盘) 内存(DRAM) 随机写 IOPS ~100-200 10K-100K ~10M 顺序写吞吐 ~100-200 MB/s 500 MB/s - 3 GB/s ~10 GB/s 随机写延迟 ~10ms(寻道时间) ~100μs ~100ns 顺序写延迟...

经典面试问题的大数据解法——Spark 与 Flink 实战
“100 亿个数中找出最大的 1000 个”、“两个 10GB 的文件找出共同的 URL”——这些经典面试题的本质都是内存放不下。单机方案围绕分治展开,分布式方案则把分治思想映射到集群节点上。本文按问题类型组织,每类问题给出从单机到 Spark/Flink 的渐进式解法,并附上概率数据结构(布隆过滤器、HyperLogLog、Count-Min Sketch)在近似场景中的应用。 引言:大数据问题的共同特征 为什么"内存放不下" 面试中给出的数据规模往往是精心设计的——刚好跨过单机内存的边界: 数据规模 内存需求 典型服务器内存 能否放入内存 1 亿个 int 400 MB 16 GB ✅ 10 亿个 int 4 GB 16 GB ✅(但留给程序的余量不多) 100 亿个 int 40 GB 16 GB ❌ 10 亿个 URL(平均 100 字节) 100 GB 16 GB ❌ 上表只计算了裸数据大小。实际使用 HashMap、HashSet 等容器时,对象头、指针、负载因子会使内存占用膨胀 3-5 倍。 通用解题框架 123...

设计一个亿级 IM 即时通讯系统
如何设计一个支撑亿级用户的即时通讯(IM)系统?这是系统设计面试中最经典的题目之一,也是实际工程中最复杂的分布式系统之一。本文将从需求分析出发,逐步构建一个完整的 IM 系统架构,涵盖长连接管理、消息投递、在线状态、多设备同步、群聊优化等核心问题。 Part 1: 需求分析与容量估算 功能需求 功能 优先级 说明 单聊 P0 一对一实时消息 群聊 P0 多人群组消息(最大 500 人) 在线状态 P1 显示用户是否在线 消息已读 P1 已读/未读状态 多设备同步 P1 手机、电脑、平板同时在线 离线消息 P0 离线用户上线后拉取未读消息 消息类型 P0 文本、图片、语音、视频、文件 消息搜索 P2 全文搜索历史消息 推送通知 P1 离线时通过 APNs/FCM 推送 非功能需求 指标 目标 DAU 1 亿 同时在线 2000 万 消息延迟 P99 < 200ms 消息可靠性 不丢消息(at-least-once) 消息有序性 单会话内有序 可用性 99.99%(全年停机 < 53 ...
Redis 经典用例全解:从数据结构到系统设计
Redis 最容易被误解成“更快的数据库”。这个理解只对了一小半。Redis 更适合放在系统的热路径上,处理短生命周期状态、派生索引、原子协调、近实时统计和少量高频列表;完整事实仍然应该由数据库、日志或对象存储承载。 系统设计面试里,Redis 的价值也不在命令背诵。更重要的是把业务需求翻译成几个稳定的问题模型: 这份数据是否可以过期 这份数据丢了能否重建 读路径是否远热于写路径 是否需要排序、范围查询、集合运算或原子判断 Redis 故障时,系统还能不能保持核心正确性 答案如果把 Redis 当成事实库,通常会在持久性、审核追溯、深页查询或跨 key 一致性上掉坑。更可靠的边界是:数据库保存事实,Redis 保存热路径和派生状态。 Redis 的系统设计位置 flowchart TD Req["业务需求"] --> Sem["抽象操作语义"] Sem --> DS["选择 Redis 数据结构"] DS --> Key["设计 Key 和分片边界"] ...
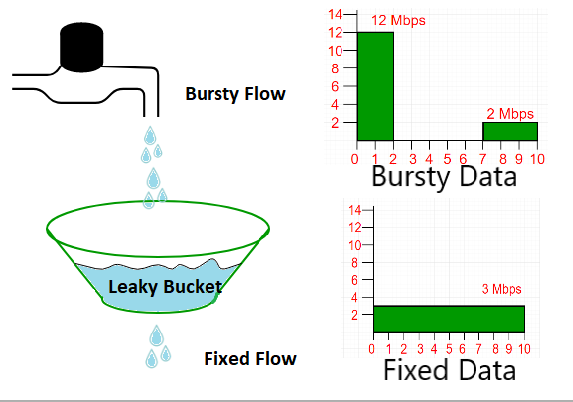
系统的弹性
背景介绍 1999年,Dan Kegel 在互联网上发表了一篇文章,首次将 C10K 问题带入软件工程师的视野。在那个互联网勃兴的年代,计算机的运算处理能力,ISP 能够提供的带宽和网速都还十分有限,用户的数量也很少(那时候一个网站几百个人是很正常的事)。Dan Kegel 却已经敏锐地注意到极端的场景下资源紧张的问题。按照他的观察,某些大型的网络站点需要面对高达10000个客户端的并行请求。以当时的通行系统架构,单机服务器并不足以处理这个这个问题(当时绝大部分系统也没有那么大的流量,所以大部分人也没意识到这个问题)。因此,系统设计者必须为 C10K 问题做好准备。在那篇文章之中, Dan Kegel 提出了使用非阻塞异步 IO 模型,和使用各种内核系统调用黑魔法来提高系统 IO 性能的方式,来提高单机的并行处理能力。不得不说,这篇文章在当时很有先驱意义,它使得大规模网络系统的流量问题浮上了水面,也让人们意识到了系统容量建模和扩容提升性能的重要性。在它的启发下,C10K 问题出现了很多变种,从并发 C10K clients,到并发 C10K connections,到 C10K ...
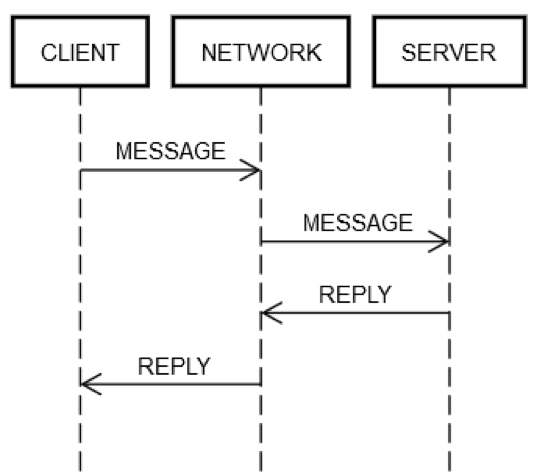
aws 的分布式系统相关挑战
原文:《分布式系统相关挑战》 早期的亚马逊系统的相关挑战 当服务器出现到第二台的时候,分布式系统的挑战就出现了: latencey scalablity 理解网络 API 数据编组和解组 Paxos 算法的复杂性 随着系统的不断快速扩展和分布程度的不断提高,理论上的边缘情况成为了常态。所以小系统不出问题主要是因为分布程度不够高。 开发分布式实用程序计算服务(例如可靠的长途电话网络或 Amazon Web Services (AWS) 服务)比较困难。与其他形式的计算相比,分布式计算也更古怪,而且不够直观,因为它存在两个相互关联的问题。在分布式系统中,造成最大问题的是故障独立性和不确定性。在分布式系统中,除了大多数工程师习以为常的计算故障外,故障还会以许多其他方式出现。更糟糕的是,不可能时刻知晓某事项是否发生了故障。 分布式系统的类型 离线分布式系统 批处理系统 大数据分析集群 电影场景渲染农场 蛋白质折叠集群 这种离线系统没有对 request 和 response 之间的强实时要求。 虽然离线分布式系统实现起来并不容易,但它却几乎囊括了分布式计算的所有优点(可扩展性和容...
Web 会话与身份认证全景
Web 会话与身份认证全景 HTTP 协议是无状态的(RFC 7230 §2.3)。每一次请求对服务器而言都是全新的,服务器不会记住上一次请求来自谁。这个设计简化了协议本身,却把"如何记住用户"的问题留给了应用层。 围绕这个核心问题,衍生出一条完整的技术问题链: 1记住用户 → 安全地记住 → 跨系统记住 → 授权第三方 → 凭证选型 → 浏览器隔离 → 攻击与防护 本文沿着这条问题链,从会话管理到身份认证,从安全边界到攻防实战,构建一幅完整的技术全景图。 全景问题链 graph TD A["HTTP 无状态<br/>RFC 7230"] -->|"问题:如何记住用户?"| B["会话管理<br/>Cookie + Session"] B -->|"问题:单机 Session 如何扩展?"| C["分布式 Session<br/>复制 / 粘性 / 集中存储"] C -->|"...

Unix/Linux 系统的常见目录
一级目录 目录路径 缩写解释 / 全称 用途描述 常见子目录/示例 / Root 根目录,所有其他目录的起点 无 /bin Binaries 基础命令的二进制文件(所有用户必需) ls, cp, mv, cat /boot Boot 系统启动文件(内核、引导加载程序) vmlinuz-*(内核文件)、grub/(GRUB配置)、initramfs /dev Devices 设备文件(物理/虚拟设备接口) sda(磁盘)、tty(终端)、null(空设备)、random(随机数生成器) /etc Etcetera 系统级配置文件(全局配置) passwd(用户账户)、fstab(挂载表)、apt/(APT包管理器配置)、ssh/ /home Home 用户主目录(个人文件和数据) /home/alice(用户 Alice 的目录) /lib Libraries 基础共享库和内核模块(支持 /bin 和 /sbin) libc.so(C标准库)、modules/(内核模块) /media Media 可移动设备挂载点(自动挂载) usb/(U...