交易系统模型设计

All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2017-12-22
分布式事务
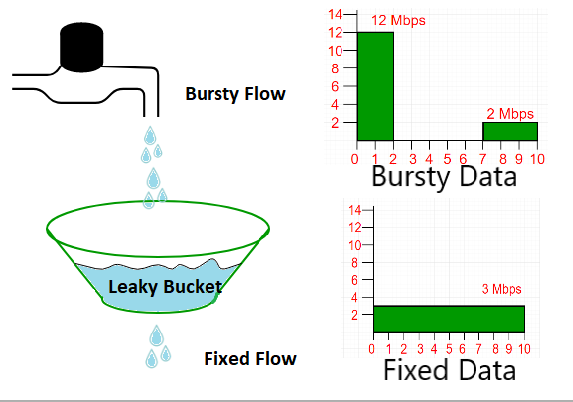
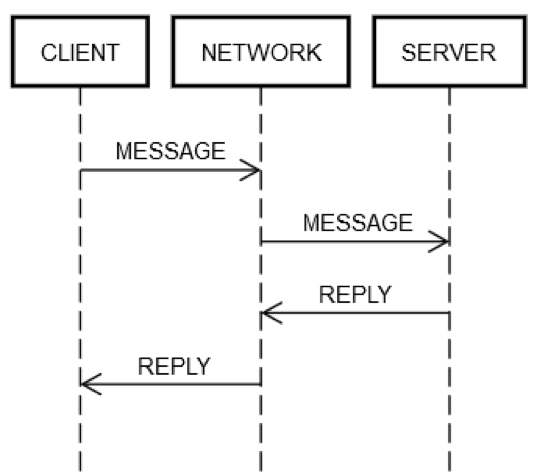
问题定义 对经典的电商场景而言:下单是个插入操作,扣减金额和库存是个更新操作,操作的模型不同,如果进行分布式的服务拆分,则可能无法在一个本地事务里操作几个模型,涉及跨库事务。 CAP 定义 根据 Eric Brewer 提出的 CAP 理论: Consistency:All Nodes see the same data at the same time。所有节点看到同一份最新数据(线性一致性)。 Availability:Reads and writes always succeed。非故障节点必须在合理时间内响应。 Partition tolerance:System continues to operate despite arbitrary message loss or failure of part of the system。网络分区时系统继续运行。 由此诞生三种设计约束和取舍方向: CA:放弃P,仅适用于单点系统,非分布式,如 MySQL主从同步。 AP:放弃强一致性,保证高可用。Cassandra,DynamoDB。Gossip协议可实现最终一致性。 CP...

2018-01-30
几种共识算法
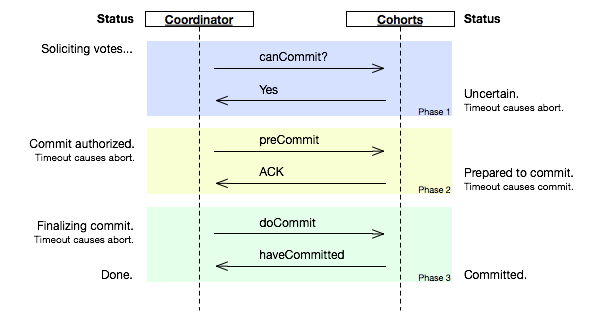
达成共识的英文原文是 come to consensus。达成共识以后,也未必代表数据是完全一致的(Raft 算法中 leader 发出 append log 的 commit 命令即算达成共识?但如果中途数据丢失,则还是会有子节点数据不一致)。 在分布式环境下,多个系统协同工作的效率,受制于系统交叉点的性能。在需要达成分布式共识的场景下,分布式共识算法在保证系统安全性的同时,限制了全系统横向扩展的性能提升。 根据环境的不同,可以应用不同的共识算法。 在完全互信的环境下-私有链、私有的分布式数据库,节点之间可以使用 Paxos 或者 Raft 这种 leader 相对固定的算法。 在有限互信的环境下-联盟链,可以使用 PBFT。PBFT 算法是依据确定性的投票(可能是漫长的投票,也可能进入死循环)达到确定性一致的算法。 在没有互信的情况下-公有链,可以使用 POW/POS/DPOS/POA。这类算法是基于概率得到正确的最终一致性,性能比 PBFT 要稍微好点。 最好的共识算法应该模块化,例如 Corda 中的 notary,Hyperledger fabric 中的 solo/k...

2018-04-02
一个滚动重启的状态保存问题
很多时候滚动重启,都会导致状态丢失。比较好的设计方法是把服务本身设计成无状态的,然后在上游的服务上做好 failover,然后增加 standby server,让 sticky 数据 transmit 到 standby 机器上,让 request 失败以后可以自己由上游重传到 standby server。然后就可以滚动重启了。 这大部分场景下还要考虑幂等的问题。 这就看得出热配置热替换的重要性了。在大多数情况下,除了发布新的 feature 升级以外,都应该尽量用热配置来避免重启。
2018-11-28
正交性
所谓正交性(orthogonal 意为正交的),就是设计的维度与其他维度完全隔离,一个正交的设计/值域设计,其变化绝不会受其他正交维度影响,也不会影响其他正交维度。 我们可以把 API 设计成正交的。这样 API 有独立变化的空间的。 我们可以把问题域切分清楚。问题域之间完全不相互干涉(注意跨问题域问题)。 我们可以把变量、字段、列设计成正交的。这样不同业务场景下,列之间的赋值不会相互覆盖。

2019-08-30
《高可用恢复思路》笔记
遇到线上问题,经常陷入一个误区:一定要找到问题的根因(root cause)。但实际上对线上应用而言,最重要的是恢复可用性,所以在开发设计环境除了完成功能性需求以外,还需要加入非功能性设计的需求: 限流保护。抵挡来自突发流量冲垮整个集群。 降级保护,对调用的服务接口保持警惕,其各种因素导致不可用,可以对齐降级,从而确保核心功能可用。 削峰填谷(traffic shaping),不因突发数据来袭,造成任务消费陡增,造成调用系统的连串抖动。 这些基本的系统保护,是应对未来的各种突发不确定事件的高可用思考。 以上描述的是问题的应对机制设计,问题的发现机制,也需要结构化地考虑,体系化地建设: 发现机制,是我们的眼睛,也是基础。 监控主指标,需要找对业务的主要指标,常见的主指标一般是:RT(响应时间)、总量、成功量、失败量、成功率。 主指标有异常,还要有细分维度(即结果还可以内部 group by aggregation)。 快速恢复 根据监控快速寻找问题发生的方向和位置。 找对恢复的人、恢复的预案。 倾向于选择成本低的恢复手段。—- 并不是所有的恢复都用大招(熔断、限流),大招一定...

2019-09-05
《应用架构之道》笔记
架构师的职责 化繁为简。架构师是职责就是把复杂的问题简单化,使得其他人能够更好地在架构里工作。 架构师要努力训练自己的思维,用它去理解复杂的系统,通过合理的分解和抽象,做出合理的设计。 软件架构 软件架构是一个系统的草图。软件架构描述的对象是直接构成系统的抽象组件。各个组件的链接则明确和相对细致地描述组件之间的通信。 软件架构为软件系统提供了结构、行为和属性的高级抽象。,由构件的描述、构件的相互作用、指导构件集成的模式以及这些模式的约束组成。软件架构不仅显示了软件需求和软件结构之间的对应关系,而且指定了整个软件系统的组织和拓扑结构,提供了一些设计决策的基本原理。 软件架构的核心价值应该只围绕一个核心命题:控制复杂性。 软件架构分类 此处输入图片的描述 业务架构:由业务架构师负责,也可以称为业务领域专家、行业专家。业务架构属于顶层设计,其对业务的定义和划分会影响组织结构和技术架构。 应用架构:由应用架构师负责,他需要根据业务场景的需要,设计应用的层次结构,制定应用规范、定义接口和数据交互协议等。并尽量将应用的复杂度控制在一个可以接受的水平,从而在快速的支撑业务发展的同时,...