MySQL 基本功
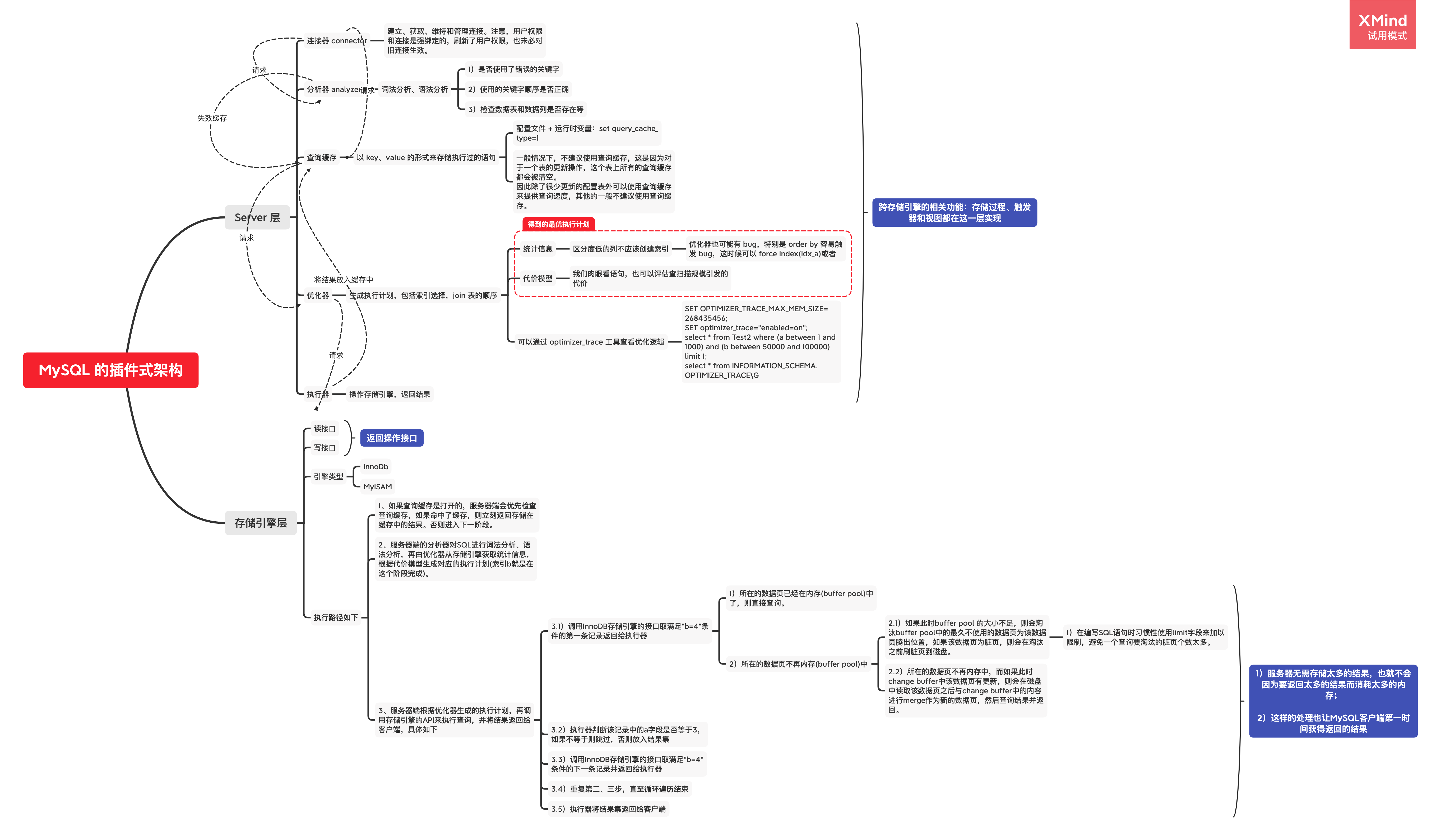
插件式架构
索引问题
索引的出现是为了减少单一维度查询时,搜索数据的成本。
索引的基础架构
索引的分类
不同的存储引擎支持不同的索引数据结构。
MySQL 支持的索引类型至少包括:BTree索引、Hash索引、full-text全文检索、R-Tree索引。
Innodb 支持的索引数据结构只有 B+树。
B+树索引
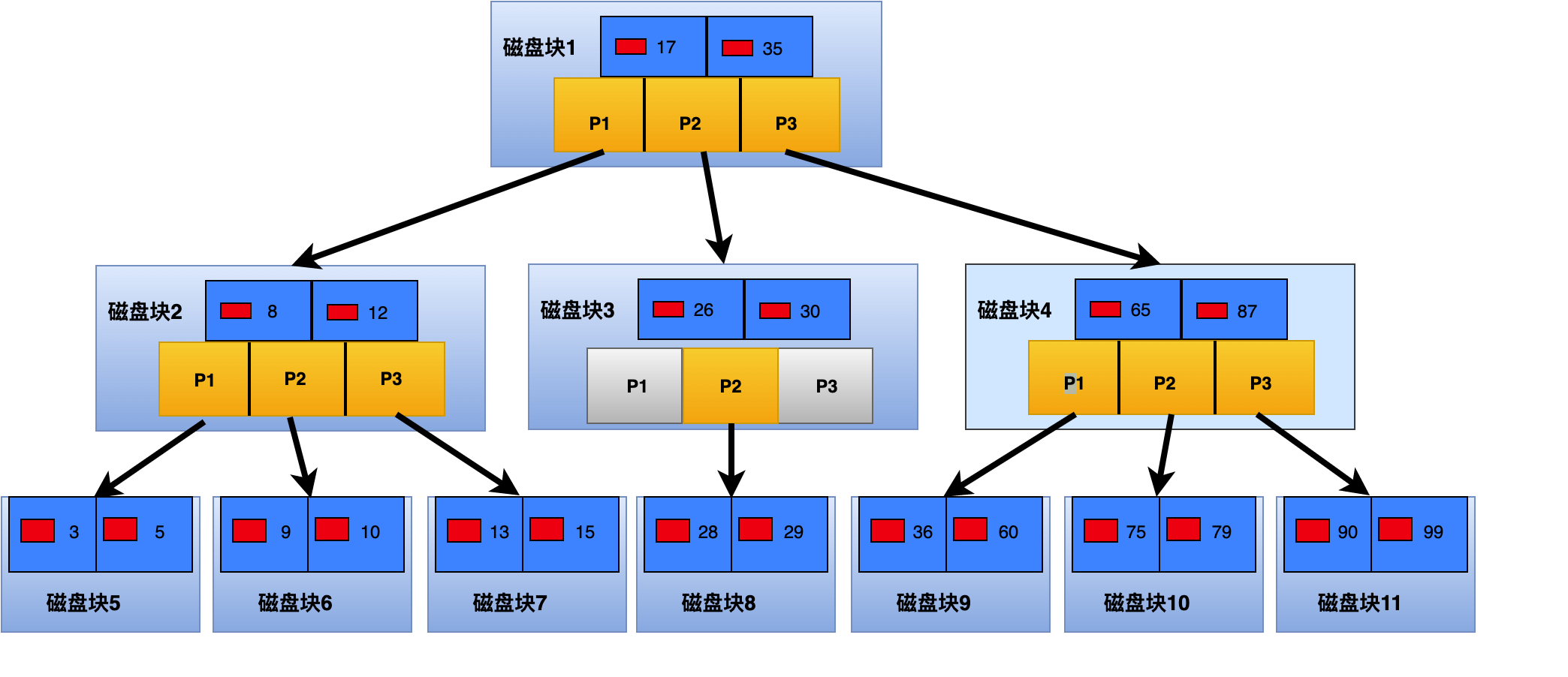
B 树扩充了二叉平衡树,让每个节点能够存储的数据大大提升。
B+ 树从 B 树演变而来,B 树每个节点都存储数据,但高度高,只有查找离根节点近的数据的速度是快的;B+树所有数据都存储在叶子节点,所以查询到特定的数据必须走完查询路径,也因此 B+树的查找速度稳定,遍历全部数据和范围查找的算法稳定(不用上溯下钻)。两种数据结构,各有所长。
B+树的每个节点可以被认为是一个磁盘块(block)-可以认为 MySQL 的磁盘块等同于 OS 的数据页,大小通常为 4k/8k/16k。磁盘块通常是双层的,第一层表示存储的数据项(data entry),第二层表示指向子节点的指针(pointer)。但 B+树本身只有叶子节点真实数据,非叶子节点存储的数据指引了指针的搜索方向(作为分界符)。
三层的 B+树能够存储的上百万条数据。也就是说,第三层是叶子节点,且叶子节点的数量为百万级。
假设数据总量为 M:
因为分界的关系,所以如果一个磁盘块能够拥有的数据项数量为 n,则可以拥有的指针数量为 n + 1。
则树的高度 height = log(n+1为底)M。
而数据的块大小又是固定的,也就意味着数据项的大小,决定了 n 的大小。所以 int 为 4 字节,bigint 为 4 字节,产生的 key_length 不一样,最终导致的树的形态也就不一样-注意,这就是B+树的数据只放在叶子节点的原因,非叶子节点存有最大限度的小数据(只有索引数据),它的 n 值最大,树的高度越低。反之,如果一个非叶子节点只能存储一个数据,则树退化为线性表。
总结:小数据 + 非叶子节点只存放小索引的设计 = B+树的高度。转换成 B 树则树的高度会变高很多,增加了磁盘 I/O。
最左匹配原则
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
不不能跳过索引中的列列,否则只能⽤用到索引前⾯面的部分。
但高版本的 MySQL 开始支持跳跃索引(待补充)。
如果查询中有某个列列的范围查询,则其右边所有的列列都⽆无法⽤用到索引优化。
索引列不能参与计算,另当like通配符在最左如:like’%dd’,或者使用负向匹配 not in,!=,<>等运算符都不不会使⽤用索引。
字段加函数则⽆无法使⽤用索引。隐式转换⽆无法使⽤用索引(这其实也是相当于对索引列加函数进行转化), 同样的问题也存在于 join 查询。
查询优化器对索引的选择
多个索引同时存在,也每次只能使用一个索引。有重叠的索引,如 status、status + time 可能导致任一索引不被使用,有时候单一索引反而更简单。因为添加索引的字段一定要有很好的区分度【cardinality】,区分度不够的时候回表的开销不如 all(full table scan)。
数据量小(比如小于2000 时)的时候 type 可能会是 all,即不走索引直接全表扫描,原理是类似 pg 和 oracle 的 cost-based optimizer。
哪些情况要建索引
- 主键自动建主键索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 在高并发下倾向建立组合索引
- 查询中的排序字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组的数据
- Index Selectivity = count(distinct column = cardinality)/count(*)。在遇到慢查询的时候,应该考虑建立新索引或者更新存量索引的结构,将查询的关键列包含进去。一个常见的问题是,一个单据既有状态,又有时间,时间的区分度是更高的,但常见的最佳实践是在状态上加索引,因为状态上的索引带来的潜在查询结果更小。 server 层通过 executor 调用 engine 的读接口次数会少很多。
哪些情况不适合建索引
-
频繁更新的字段
-
where条件用不到的字段不创建索引
-
表记录太少
-
经常增删改的表
-
数据重复太多的字段,为它建索引意义不大(假如一个表有10万,有一个字段只有T和F两种值,每个值的分布概率大约只有50%,那么对这个字段的建索引一般不会提高查询效率,索引的选择性是指索引列的不同值数据与表中索引记录的比,,如果,一个表中有2000条记录,表中索引列的不同值记录有1980个,这个索引的选择性为1980/2000=0.99,如果索引项越接近1,这个索引效率越高)。
与 order by 的关系
1、如果你只需要结果集中的某几行,那么建议使用 limit(limit 最好不要配 offset,配 id,要注意 id 滚动的问题)。这样的话可以避免抓取全部结果集,然后再丢弃那些你不要的行。
2、对于 order by 查询,带或者不带 limit 可能返回行的顺序是不一样的。
3、如果 limit row_count 与 order by 一起使用,那么在找到第一个 row_count 就停止排序,直接返回(类似 ES 的提前返回)。limit 的本质是找到足够多的数据的时候才停止,如果只是想限制查询足够多的数据,id < begin + limit 的性能表现会好得多。
4、如果 order by 列有相同的值,那么 MySQL 可以自由地以任何顺序返回这些行。换言之,只要 order by 列的值不重复,就可以保证返回的顺序。
5、可以在order by子句中包含附加列(组合 order by),以使顺序具有确定性。
6、ORDER BY的索引优化。如果一个SQL语句形如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort];
在[sort]这个栏位上建立索引就可以实现利用索引进行order by 优化。相反地,如果 order by 没有命中索引,就会导致 file sort或者错误的索引选择,mysql 5.7 也不例外。但很多时候,没有命中索引,也不一定就会慢,命中索引或多或少都会导致回表,有可能不回表的速度更快 - 这取决于 query optimizer 怎么看待这个查询计划。考虑多方诉求的话,可以打破常规,考虑把 id 加进索引里。所以 order by 的列不是查询优化器选择的索引是最尴尬的。
7、WHERE + ORDER BY的索引优化,形如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [value] ORDER BY [sort];
建立一个联合索引(columnX,sort)来实现order by 优化。
注意:如果columnX对应多个值,如下面语句就无法利用索引来实现order by的优化
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] IN ([value1],[value2],…) ORDER BY[sort];
8、WHERE+ 多个字段ORDER BY
SELECT * FROM [table] WHERE uid=1 ORDER x,y LIMIT 0,10;
建立索引(uid,x,y)实现order by的优化,比建立(x,y,uid)索引效果要好得多。
MySQL Order By 不能使用索引来优化排序的情况
-
对不同的索引键做 ORDER BY :(key1,key2分别建立索引)
SELECT * FROM t1 ORDER BY key1, key2; -
在非连续的索引键部分上做 ORDER BY:(key_part1,key_part2建立联合索引;key2建立索引)
SELECT * FROM t1 WHERE key2=constant ORDER BY key_part2; -
同时使用了 ASC 和 DESC:(key_part1,key_part2建立联合索引)
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; -
用于搜索记录的索引键和做 ORDER BY 的不是同一个:(key1,key2分别建立索引)
SELECT * FROM t1 WHERE key2=constant ORDER BY key1; -
如果在WHERE和ORDER BY的栏位上应用表达式(函数)时,则无法利用索引来实现 order by 的优化
SELECT * FROM t1 ORDER BY YEAR(logindate) LIMIT 0,10;
特别提示:
1>mysql一次查询只能使用一个索引。如果要对多个字段使用索引,建立复合索引。
2>在ORDER BY操作中,MySQL只有在排序条件不是一个查询条件表达式的情况下才使用索引。
9、如果不指定 ORDER BY,不能指望 mysql 默认返回任何默认顺序。但一旦指定了 order by,MySQL 的 order by 的默认值是 asc。
10、 MySQL 8.0 开始支持索引在磁盘上排序 。
11、Databases can read indexes in both directions. 但,如果走索引的列和 order by 的列正好相反,那么查询会非常非常慢。举例,假设 t 的数据量非常大,select * from t where gmt_create < '2019-08-11 22:00:00' order by id,如果 MySQL 的查询优化器决定使用 id作为索引(MySQL 上每次只有一个索引会生效),那么查询会先从主索引的树的左边往右扫(扫描顺序由 order by 的顺序决定),如果当前时间和 2019-08-11 22:00:00 之间的数据量非常大,会导致非常大的 filtered,查询会异常地慢(这种情况有点类似 index jumping-注意看这个例子的 6.3)。
12、order-by 语句可能会误导查询优化器,选择错误的索引,形成错误的查询计划。这是一个无数的 RD 和 DBA 工作中会遇到的已知 bug。
与 Group By 的关系
must appear in the GROUP BY clause or be used in an aggregate function
所有的 group by 里的列必须被select。select 中除了聚合函数,必须放在 group by 里。
group by 的实质是先排序后分组。在 group by 的列没有索引时,考虑使用 order by null(作用是强制对查询结果禁用排序),有时候可以消除 file sort(因为不需要排序了)。
常见的分组逻辑:
where 先搜出结果集,group by 对结果进行分组(整张表不一定会分到一组,如果分组键里有唯一索引每一行都是一组,则每一行都是一组,所以有个常见的逻辑谬误,如 max 问题),然后对分组进行 having 过滤。
索引失效_复合索引(避免)
- 应该尽量全值匹配
- 复合最佳左前缀法则(第一个索引不能掉,中间不能断开)
- 不在索引列上做任何操作(计算、函数、类型转换)会导致索引失效而转向全表扫描
- 储存引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *(特别是生成 orm 映射的时候,尽量把所有的列写入select 段中)。
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
- is null,is not null也可能会无法使用索引
- like 以通配符开头
- 字符串不加单引号(引发了隐式转化)
- 少用or(在大多数情况下用 in 代替,in 也不好,有时候会导致全表扫描)
null
参考《MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!》、《MySQL中NULL对索引的影响》。
对MySQL来说,null是一个特殊的值,Conceptually, NULL means “a missing unknown value” and it is treated somewhat differently from other values。比如:不能使用=,<,>这样的运算符,对null做算术运算的结果都是null,count时不会包括null行等,null比空字符串需要更多的存储空间等。
blob 与 text
这两种数据类型不能配置非 null 缺省值(即缺省值可以为 null),所以不适合配 not null 约束。
破除偏见
首先,null 列会存在于 MySQL 的索引里。一般传言认为:null 值必然会全表扫描,是不准确的;null 值不会存储在索引里,也是不准确的。

NULL 与 B+ 树的存储
一条记录的主键值不允许存储 NULL 值。设置为 NOT NULL 的列也不允许存储 NULL 值。
对于索引列值为NULL的二级索引记录来说,它们被放在B+树的最左边。
We define the SQL null to be the smallest possible value of a field.
在通过二级索引idx_key1对应的B+树快速定位到叶子节点中符合条件的最左边的那条记录后,就可以顺着每条记录都有的 next_record 属性沿着由记录组成的单向链表去获取记录了,直到某条记录的key1列不为 NULL。
是否使用索引的决策依据到底是什么
MySQL 的执行计划是由查询优化器产出的。查询优化器在这个场景里最重要的参考因子是成本(cost-based optimizing 的优化策略是数据库领域最常见的优化策略)。
- 读取二级索引记录的成本。
- 将二级索引记录执行回表操作,也就是到聚簇索引中找到完整的用户记录的操作所付出的成本。
换言之,回表意味着 IO 被放大了(简单来说,读至少乘以一个系数 2)。如果回表比简单地全表扫描聚簇索引成本还要高,那么查询优化器就会选择不走索引。
比方说对于下边这个查询:
1 | |
复制代码优化器会分析出此查询只需要查找key1值为NULL的记录,然后访问一下二级索引idx_key1,看一下值为NULL的记录有多少(如果符合条件的二级索引记录数量较少,那么统计结果是精确的,如果太多的话,会采用一定的手段计算一个模糊的值)- 这种在查询真正执行前优化器就率先访问索引来计算需要扫描的索引记录数量的方式称之为 index dive。当然,对于某些查询,比方说WHERE子句中有IN条件,并且IN条件中包含许多参数的话,比方说这样:
1 | |
复制代码这样的话需要统计的key1值所在的区间就太多了,这样就不能采用index dive的方式去真正的访问二级索引idx_key1,而是需要采用之前在背地里产生的一些统计数据去估算匹配的二级索引记录有多少条(很显然根据统计数据去估算记录条数比index dive的方式精确性差了很多)。
反正不论采用index dive还是依据统计数据估算,最终要得到一个需要扫描的二级索引记录条数,如果这个条数占整个记录条数的比例特别大,那么就趋向于使用全表扫描执行查询,否则趋向于使用这个索引执行查询。
理解了这个也就好理解为什么在WHERE子句中出现IS NULL、IS NOT NULL、!=这些条件仍然可以使用索引,本质上都是优化器去计算一下对应的二级索引数量占所有记录数量的比值而已。
MySQL 官方文档的介绍
参考《8.2.1.13 IS NULL Optimization》。
- 对 NOT NULL 的列使用 IS NULL 查询,表达式会被 optimized away,但如果查询的表是由于 outer join 产生的 null 值,则不会发生 optimization。
其他优化建议
- 批量insert语句最好采用bulk insert的方法,如insert into table(xxx) values (xxx),(xxx),每个批次以执行时间小于100ms为原则。
- 禁止使用Select *,*用所需字段代替。
- 禁止使用子查询.
- 避免使用Or( in 也不那么好),用Union代替.
- 不要使用大偏移量的分页。
- 为较长的字符串使用前缀索引。如果
alter table table_name add key (long_string(25));,可以起到类似 git 的 commit 前缀的作用。
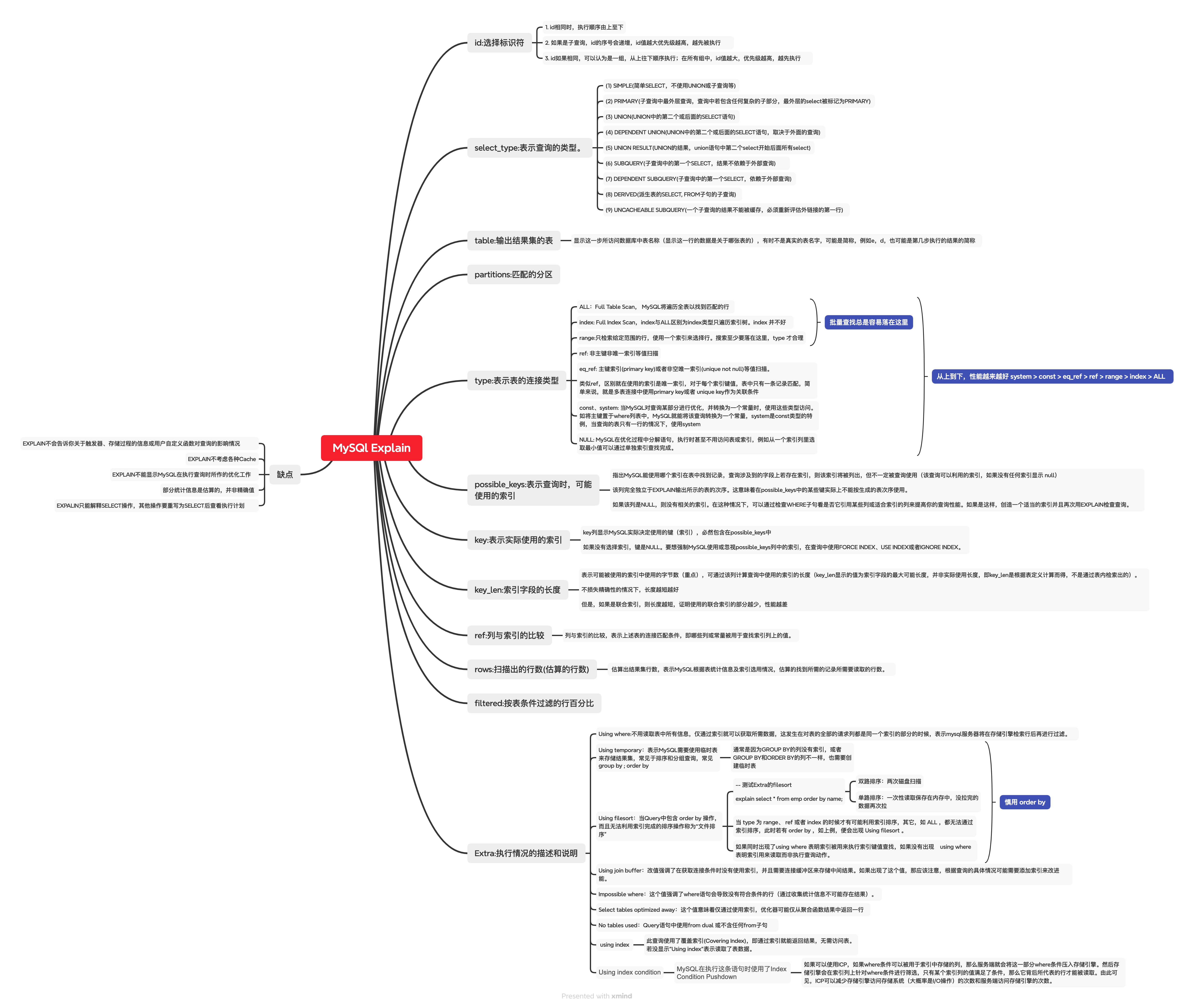
explain 思维导图